@user_432 You need to restart the instance for the upgrade to go into affect. (just hit restart runtime) (I’ve also updated the instructions to say this as well)
If you contribute to fastai2, the new command to run (that replaces tools/run-after-git-clone) is
nbdev_install_git_hooks
You might need to redo an editable install of nbdev if you had one before (to register all the new CLIs), note that this doesn’t work with the version on pypi yet (will do a new release soon-ish).
I have been following the discussion, though I have not actually yet installed and used fastai v2 (except playing around with RSNA kernel). However, I would like to do that now, and have a few questions.
I recently saw that the fastai_dev has been split. There is now a separate fastai2 library. If I understand correctly, this is for easy installation, right? So I can just pip install fastai2 and the version from the fastai2 repository will be installed?
What if I want to use the fastai_dev repository? That way I can get the latest changes. How I can install this version? What are the difference when using this version and the fastai2 version?
The fastai2 repo is what you should use until the final release, they moved it there to clear up the dev repo, and will be the most up-to-date code. You can’t quite pip install fastai2 yet, instead do a !pip install git+https://github.com/fastai/fastai2 (we updated the install directions here to show this). The final release will be on the main fastai branch (IIRC), however I can say that Sylvain and Jeremy said that this would be the only repo migration until the final release. Does this answer your questions @ilovescience
In google colab, I am trying to follow along with this tutorial. I could not import from nbdev.showdoc import *. I got the following error:
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-4-e0e43e5288cc> in <module>()
----> 1 from nbdev.showdoc import *
2 frames
/usr/local/lib/python3.6/dist-packages/nbdev/showdoc.py in <module>()
6 #Cell
7 from .imports import *
----> 8 from .export import *
9 from .sync import *
10 from IPython.display import Markdown,display
/usr/local/lib/python3.6/dist-packages/nbdev/export.py in <module>()
199 #Cell
200 #Catches any from nbdev.bla import something and catches nbdev.bla in group 1, the imported thing(s) in group 2.
--> 201 _re_import = re.compile(r'^(\s*)from (' + Config().lib_name + '.\S*) import (.*)$')
202
203 #Cell
/usr/local/lib/python3.6/dist-packages/nbdev/imports.py in __init__(self, cfg_name)
26 while cfg_path != Path('/') and not (cfg_path/cfg_name).exists(): cfg_path = cfg_path.parent
27 self.config_file = cfg_path/cfg_name
---> 28 assert self.config_file.exists(), "Use `Config.create` to create a `Config` object the first time"
29 self.d = read_config_file(self.config_file)['DEFAULT']
30
AssertionError: Use `Config.create` to create a `Config` object the first time
It is not. My tutorial notebooks don’t use it. Try running untar_data once so a Config file is made. To the rest, I’m unsure, I haven’t looked into the nbdev repo yet
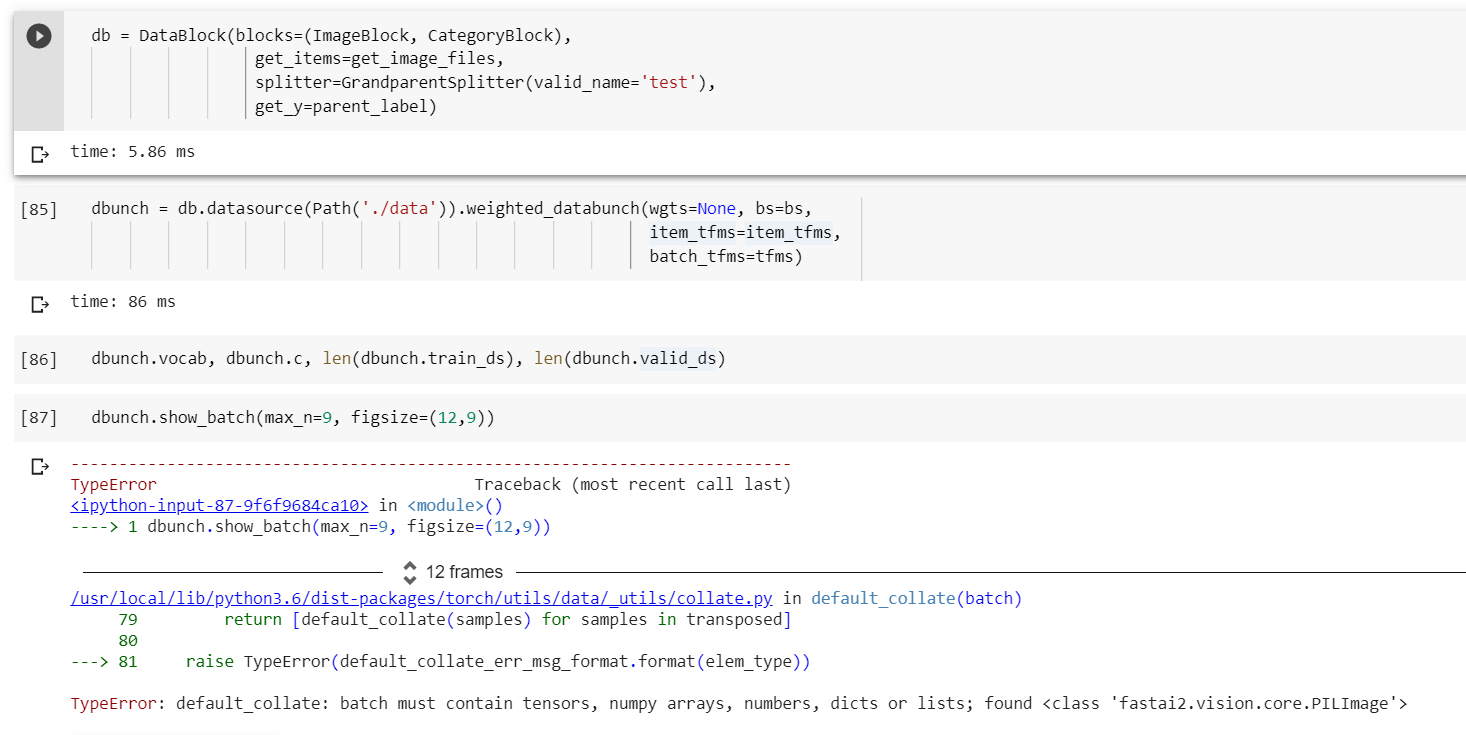
I’m facing imbalanced data distribution and I was searching for the same functionality as of the OverSamplingCallback - which we had in v1 (thanks to @ilovescience if I’m right). Since Jeremy said now we can use weighted_databunch() instead, I read the source code, noticed that this function takes in a DataSource, so I tried to implement it this way but get stuck at dbunch.show_batch() or further training, with the following error.
Edit: I went back and checked if the normal .databunch() worked but it didn’t. So if I call DataBlock().databunch(), everthing’s fine, but not if it is DataBlock().datasource().databunch(). I might have missed some basics here.
I appreciates any guidelines for this.
I’m confused about how the magic that allows transforms to be handled seamlessly for both individual items and batches, and it’s causing a few problems.
My signal transforms take an AudioItem as an argument. AudioItem extends tuple, and has a sig attribute for the audio signal (2d tensor, channels x samples, e.g. 1 x 16000 for 1s audio), as well as attributes for the sample_rate and the originating file of each audio.
I can easily do my transforms on the last dim so that it works for 1x16000 and 64 x 1 x 16000, and works independent of #channels/batch, but it makes no sense for these transforms to return an AudioItem when they are working with a batch, right? So where am I going wrong? Do I need a separate TensorAudio class that extends TensorBase, and that is what I should be doing my signal transforms on? Also, I notice if I write my transform code to be agnostic to the existence of a batch dimension, then these transforms work on the GPU even though they take an AudioItem and reference attributes of it like sig, how is this magic happening?
After running nbdev_install_git_hooks a .gitconfig file is created.
This file is not present on the fastai2 repo so I think it should be ignored. Should it be added to .gitignore then? It’s really annoying to have to remember to manually don’t include this file when committing.
How do we turn off GPU-ported augmentation when training? I’d like to push some specific augmentations (like resize, etc) on the CPU to free up GPU space. The reasoning for this is my GPU usage is considerably higher in v1 vs v2. How would I go about setting that up?
Just wanted to share my current progress with v2. It really is inviting to work on and gives a lot of room for (mis)use.
I made some fake data since I’m not allowed to share the real data. But it is time-series forecasting with LSTM and a simple layer on top. This for a couple of locations in 2 cities, these are included as embedding. The target depends on the weather. I tried to use the transforms where possible and to plot and test as much as possible.
Any feedback/comment/tips is welcome.
PS I’m currently stuck on a peculiar problem. Any pointers are welcome. When I execute learn.show_results(). It currently is the case that my *yb seems to contain an keyword argument reduction?? I do not get it because * means positional argument right? and ** would be keyword? But still:
~/devtools/fastai_dev/fastai2/learner.py in one_batch(self, i, b)
215 self.pred = self.model(*self.xb); self('after_pred')
216 if len(self.yb) == 0: return
--> 217 self.loss = self.loss_func(self.pred, *self.yb); self('after_loss')
218 if not self.training: return
219 self.loss.backward(); self('after_backward')
TypeError: mse() got an unexpected keyword argument 'reduction'
You need to implement reduction in your custom loss function to be able to use Learner.get_preds or Learner.show_results, in particular reduction='none'.


 (just hit restart runtime) (I’ve also updated the instructions to say this as well)
(just hit restart runtime) (I’ve also updated the instructions to say this as well)