I was running the dl/fastai_dev/dev/01_core_foundation notebook, so I am in the dev folder. Which config file is it looking for?
fastai_dev doesn’t work with nbdev, you should be in the fastai2 repo now.
Thanks for the hint. I had some issues after installing fastai2, but a restart of my docker container seems to have resolved the issue. Seems to be working now.
Thx for the help!
Is this a one time thing? How do we convert notebooks (which are in same directory with fastai2) to scripts now? Thanks
As explained in the README, you just type nbdev_build_lib. Changing repo is kind of a one-time thing but we will likely switch again when it’s time to release to put it in the normal fastai repo.
1 Like
@muellerzr - this worked for me - maybe updating the colab requirements here Fastai-v2 - read this before posting please! 😊 for the new install info
Done!
2 Likes
I’ve pulled fastai.script out into a separate project, improved it a bit, and documented it properly. It’s now called fastscript. It is a library for quickly and easily creating command line python scripts. Here it is:
Please try it out and tell me if you have any issues with it, or suggestions for things that could be more clear or straightforward. I’ve tried hard to put together some usable but simple best practices for creating and packaging scripts, so hopefully you find this helpful! 
8 Likes
Hello, I wanted to follow the fastai2 code walkthru on Colab.Firstly I’ve done,

then cloned the repo,
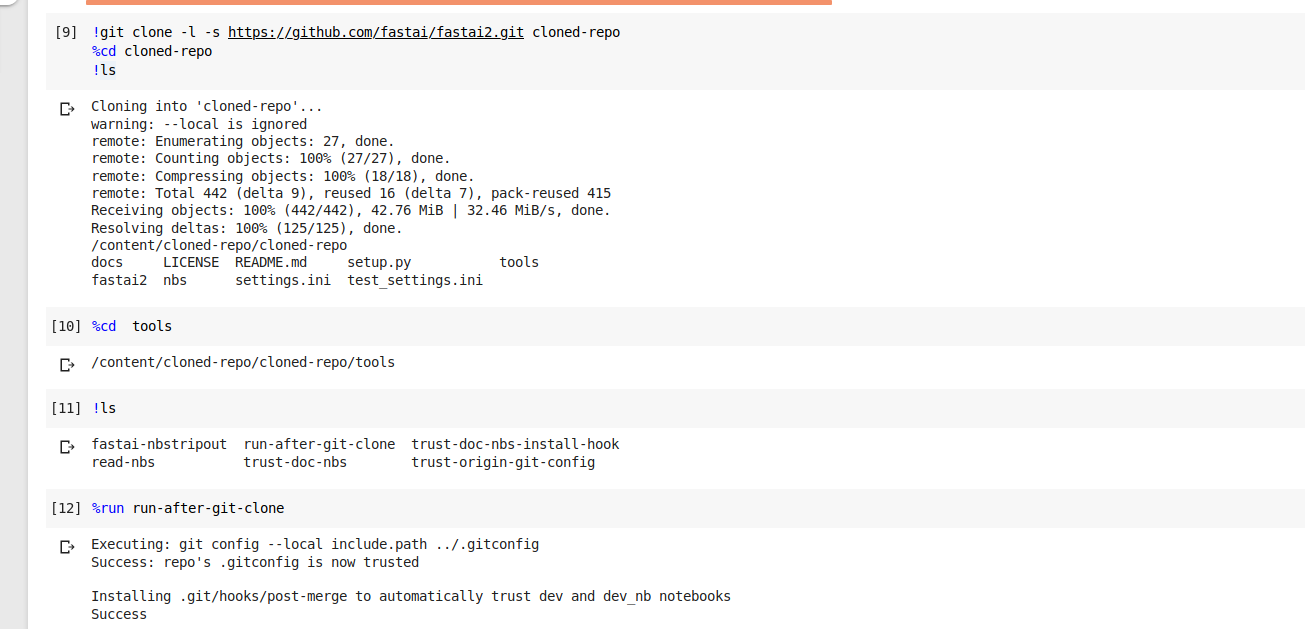

and then when I run this it shows me a error
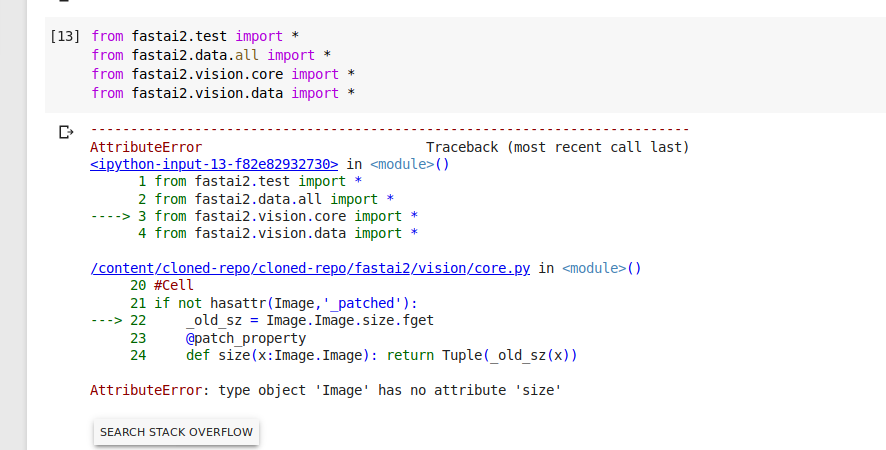
Am I missing something? I’m not a python expert so it would be helpful if someone could guide me:slightly_smiling_face:
@user_432 You need to restart the instance for the upgrade to go into affect. (just hit restart runtime) (I’ve also updated the instructions to say this as well)
2 Likes
Thanks, its working fine now.
If you contribute to fastai2, the new command to run (that replaces tools/run-after-git-clone) is
nbdev_install_git_hooks
You might need to redo an editable install of nbdev if you had one before (to register all the new CLIs), note that this doesn’t work with the version on pypi yet (will do a new release soon-ish).
2 Likes
Hello all,
I have been following the discussion, though I have not actually yet installed and used fastai v2 (except playing around with RSNA kernel). However, I would like to do that now, and have a few questions.
I recently saw that the fastai_dev has been split. There is now a separate fastai2 library. If I understand correctly, this is for easy installation, right? So I can just pip install fastai2 and the version from the fastai2 repository will be installed?
What if I want to use the fastai_dev repository? That way I can get the latest changes. How I can install this version? What are the difference when using this version and the fastai2 version?
The fastai2 repo is what you should use until the final release, they moved it there to clear up the dev repo, and will be the most up-to-date code. You can’t quite pip install fastai2 yet, instead do a !pip install git+https://github.com/fastai/fastai2 (we updated the install directions here to show this). The final release will be on the main fastai branch (IIRC), however I can say that Sylvain and Jeremy said that this would be the only repo migration until the final release. Does this answer your questions @ilovescience
1 Like
So does that mean any new changes to fastai2 will be in the fastai2 library, not fastai_dev?
Yes
1 Like
In google colab, I am trying to follow along with this tutorial. I could not import
from nbdev.showdoc import *. I got the following error:
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-4-e0e43e5288cc> in <module>()
----> 1 from nbdev.showdoc import *
2 frames
/usr/local/lib/python3.6/dist-packages/nbdev/showdoc.py in <module>()
6 #Cell
7 from .imports import *
----> 8 from .export import *
9 from .sync import *
10 from IPython.display import Markdown,display
/usr/local/lib/python3.6/dist-packages/nbdev/export.py in <module>()
199 #Cell
200 #Catches any from nbdev.bla import something and catches nbdev.bla in group 1, the imported thing(s) in group 2.
--> 201 _re_import = re.compile(r'^(\s*)from (' + Config().lib_name + '.\S*) import (.*)$')
202
203 #Cell
/usr/local/lib/python3.6/dist-packages/nbdev/imports.py in __init__(self, cfg_name)
26 while cfg_path != Path('/') and not (cfg_path/cfg_name).exists(): cfg_path = cfg_path.parent
27 self.config_file = cfg_path/cfg_name
---> 28 assert self.config_file.exists(), "Use `Config.create` to create a `Config` object the first time"
29 self.d = read_config_file(self.config_file)['DEFAULT']
30
AssertionError: Use `Config.create` to create a `Config` object the first time
I installed the libraries like this:
!pip install torch torchvision feather-format kornia pyarrow Pillow wandb nbdev --upgrade
!pip install git+https://github.com/fastai/fastprogress --upgrade
!pip install git+https://github.com/fastai/fastai2
And then I restarted the runtime.
Is there something I did wrong? Also, what is nbdev used for in fastai? Is it required for basic usage of the library?
It is not. My tutorial notebooks don’t use it. Try running untar_data once so a Config file is made. To the rest, I’m unsure, I haven’t looked into the nbdev repo yet
2 Likes
Hi everyone,
I’m facing imbalanced data distribution and I was searching for the same functionality as of the OverSamplingCallback - which we had in v1 (thanks to @ilovescience if I’m right). Since Jeremy said now we can use weighted_databunch() instead, I read the source code, noticed that this function takes in a DataSource, so I tried to implement it this way but get stuck at dbunch.show_batch() or further training, with the following error.
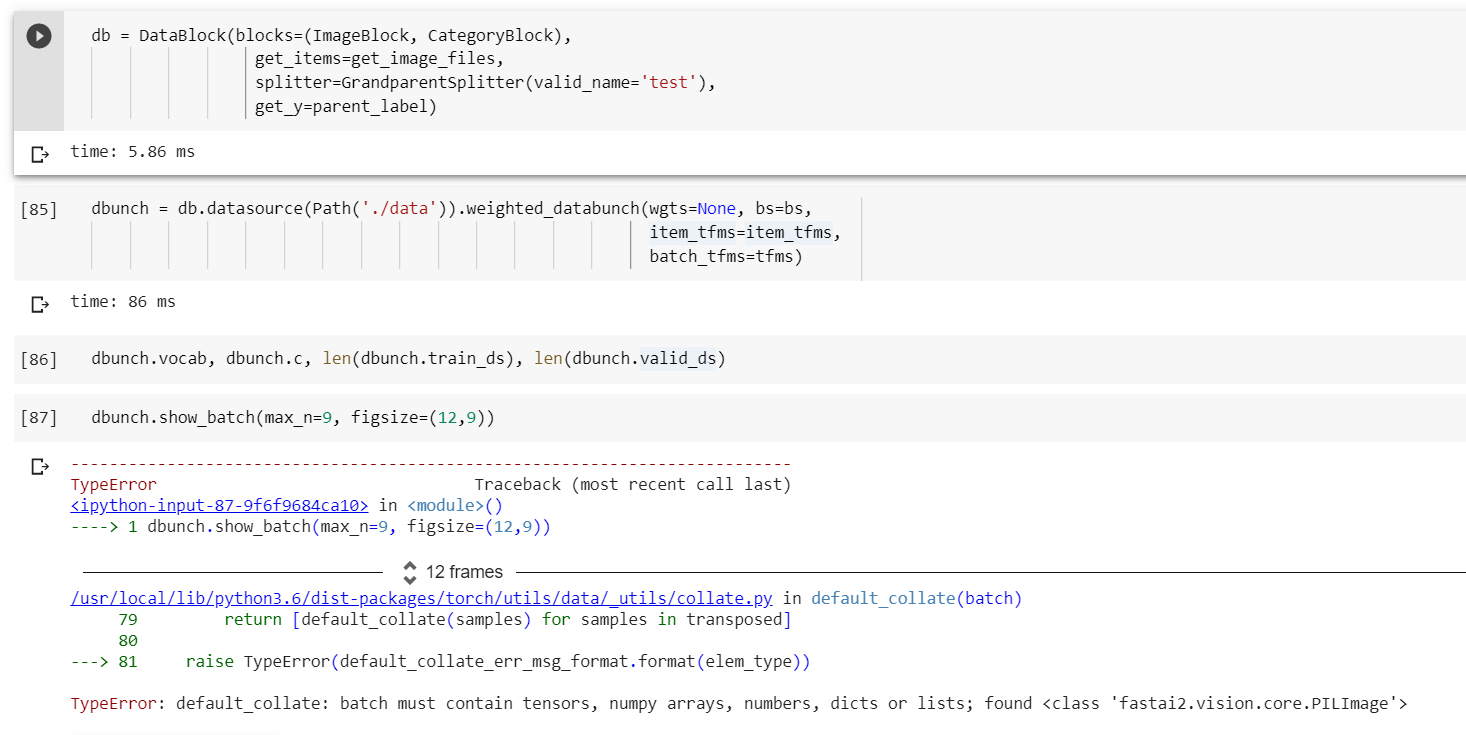
Edit: I went back and checked if the normal .databunch() worked but it didn’t. So if I call DataBlock().databunch(), everthing’s fine, but not if it is DataBlock().datasource().databunch(). I might have missed some basics here.
I appreciates any guidelines for this.
1 Like
I’m confused about how the magic that allows transforms to be handled seamlessly for both individual items and batches, and it’s causing a few problems.
My signal transforms take an AudioItem as an argument. AudioItem extends tuple, and has a sig attribute for the audio signal (2d tensor, channels x samples, e.g. 1 x 16000 for 1s audio), as well as attributes for the sample_rate and the originating file of each audio.
I can easily do my transforms on the last dim so that it works for 1x16000 and 64 x 1 x 16000, and works independent of #channels/batch, but it makes no sense for these transforms to return an AudioItem when they are working with a batch, right? So where am I going wrong? Do I need a separate TensorAudio class that extends TensorBase, and that is what I should be doing my signal transforms on? Also, I notice if I write my transform code to be agnostic to the existence of a batch dimension, then these transforms work on the GPU even though they take an AudioItem and reference attributes of it like sig, how is this magic happening?