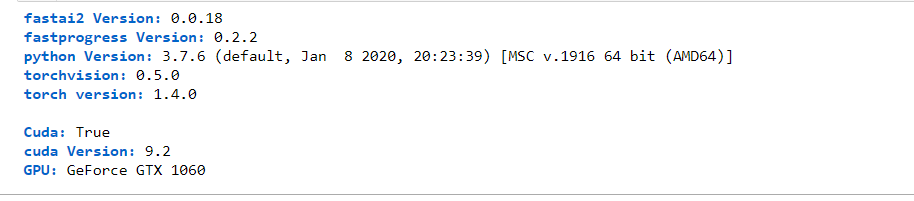
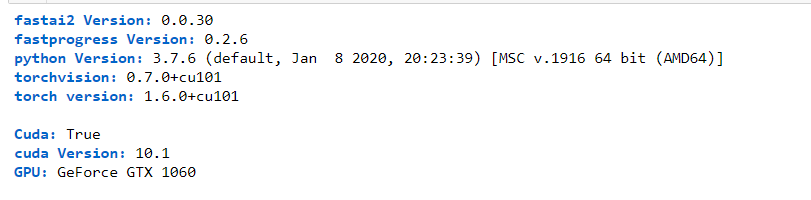
Hi,
I am facing this error when trying to use fastai2 in Kaggle. I have upgraded to torch 1.6.0 and installed fastai2 using pip. Would request help from anyone.
AttributeError Traceback (most recent call last)
in
7 from matplotlib import pyplot as plt
8 get_ipython().run_line_magic(‘matplotlib’, ‘inline’)
----> 9 from fastai2.torch_basics import *
10 from fastai2.basics import *
11 from fastai2.data.all import *
/opt/conda/lib/python3.7/site-packages/fastai2/torch_basics.py in
2 from .imports import *
3 from .torch_imports import *
----> 4 from .torch_core import *
5 from .layers import *
/opt/conda/lib/python3.7/site-packages/fastai2/torch_core.py in
244 # Cell
245 if not hasattr(torch,‘as_subclass’):
–> 246 setattr(torch, ‘as_subclass’, torch.Tensor.as_subclass)
247
248 # Cell
AttributeError: type object ‘Tensor’ has no attribute ‘as_subclass’