Interesting test. When I print those sums, I get high numbers but no nans.
Are you in half precision by any chance? Or can you train to redownload the data (remove the dogscats.tgz and folder to force it)?
@nok You are right, I can train without problem if I comment out the max_lighting part in the get_transforms().
ds_tfms=get_transforms(max_lighting=0) works fine too.
@sgugger I got the nan loss after redownload the data.
If everyone having this problem using Google Cloud?
I have tested it again:
Test: GCP Deep Learning Image with latest git pull
Result: Still get NaN
Redownload the dogscats data, still get the same error. The tensor is just in cpu? so I don’t think it’s related to fp16
Seems like the issue comes from GCP since it only happens there. Jeremy has told them so that we can sort this thing out.
GCP = Google Cloud Platform?
I am not on Google Cloud
Oh interesting. @elmarculino what kind of CPU do you have? Can you try py36 and see if you still have the problem?
My CPU is an AMD Phenom II X6 1055t. I got the same problem with python 3.6.
I wonder if it’s an AMD issue. Are you using anaconda? Try a different BLAS library: https://docs.anaconda.com/mkl-optimizations/ . Please let me know if any of these fix the issue?
Model name: Intel® Xeon® CPU @ 2.50GHz
For my case, I am in GCP and a Intel CPU, in python 3.6 and 3.7
I also tried checkout at tag 1.0.5, still get NaN
Yes, I’m using anaconda.
First test: Install nomkl packages
conda install nomkl numpy scipy scikit-learn numexpr
Result: NaN loss
Second test: Install openblas
conda install -c anaconda openblas
Result: NaN loss
Could not unistall MKL:
The following packages will be REMOVED:
mkl: 2019.0-118
mkl_fft: 1.0.1-py36h3010b51_0 anaconda
mkl_random: 1.0.1-py36h629b387_0 anaconda
pytorch-nightly: 1.0.0.dev20181015-py3.6_cuda9.2.148_cudnn7.1.4_0 pytorch [cuda92]
torchvision-nightly: 0.2.1-py_0 fastaiTry now - update from master first. Hopefully it’s fixed (I can’t test since I can’t repro the bug).
It’s running without problem now. Thanks Jeremy
Last version:
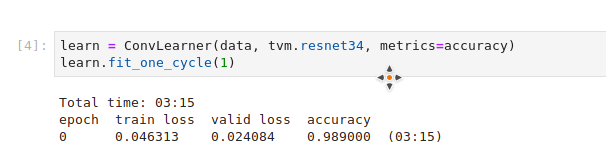
Old version with ds_tfms=get_transforms(max_lighting=0)
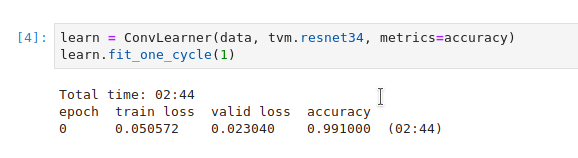
2 Likes
Thx! it is fixed now, I try to look at the commits that you made yesterday, but it is not obvious to me which commits fix the issue, I am interested in what was causing this.
Thank you. 
For some reason, there was some numerical instability in the lighting transforms. The fix is the clipping introduced here.
2 Likes
Ah, thank you! I didn’t realize the clipping was fixing this issue. So this instability seems somehow depends on other things(hardware?) as seems it is not a issue for quite a few peoples.
Something like that. Or perhaps some blas issue.
1 Like
Has anyone else been suffering a sudden NaN loss with other datasets?
I’m working with a large (200k) dataset for binary classification that gracefully descends a loss curve from .10 to .03 and in about 1 in 5 runs loss suddenly goes NaN when previous epochs have descended nicely. Granted that’s a low per-batch likelihood but high per-run. It never happened to me pre 1.0. I haven’t touched the loss_func. Once, it came back from NaN after a few epochs as if nothing had happened. My transforms are dihedral, and 10% bands of brightness, contrast change, with resnet34. Using latest fastai and pytorch builds, with fp16. Perhaps there is a clipping parameter I can set?
Plenty of changes under the hood in v1, so likely hyperparams need to change. Try lowering your learning rate by 10x.