Hi All,
First of all, thanks to Jeremy and the folks at FastAi team for putting out this fantastic course/library–love the overall philosophy, and as a beginner I’ve already learned more here in Part 1 than I could have believed possible.
I’m at a firm that is interested in doing an unsupervised clustering of unlabeled customer service transcripts by a latent call reason. I know it wouldn’t be making full use of ULMFiT, e.g., the decoder, but in theory using transfer learning on our corpus of text transcripts with AWD-LSTM would still be really powerful because the language model would be able to find relationships between sentences and not just words like in Word2Vec.
The obvious inspiration for this project is @hamelsmu’s amazing work on translating natural language in docstrings to headings of functions in code. But because things are moving so quickly at FastAi and library/classes are constantly updating, it’s been a bit of a challenge for me following the code from 0.7 even though the source code and documentation are excellent.
I’m able to easily create a TextLMDataBunch object from a csv and train a learner (that predicts dropouts well) on our customer service transcripts from factory methods. My question is: given a learner object, how can provide it an input transcript and use the encoder(?) to generate transcript embeddings, which could be used for downstream tasks like clustering/identifying similarity with others?
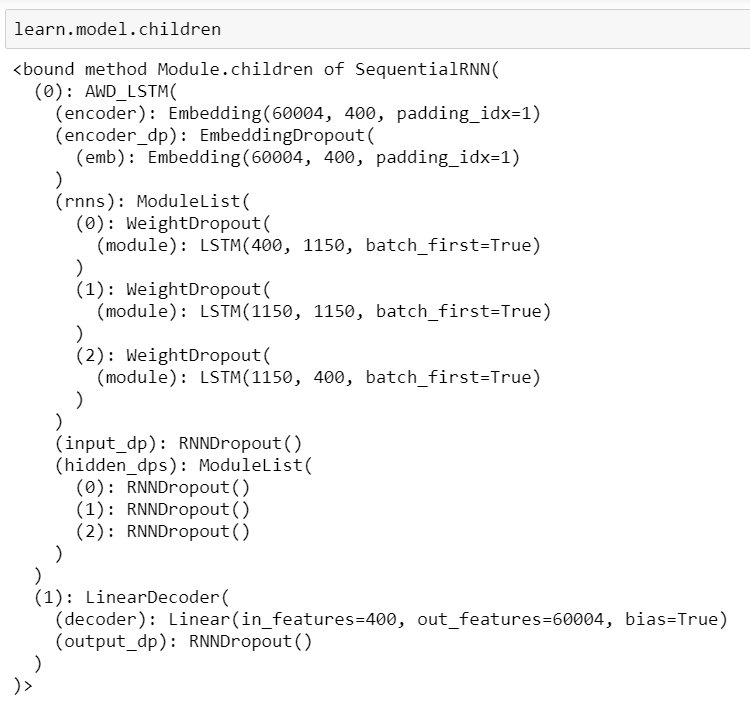
I can use learn.model._modules[‘0’].encoder to get a [60000, 400] torch object, which I believe to be the word embeddings for my vocabulary of 60k tokens. I’m confused after this step. Specifically, following @hamelsmu’s code, how would I:

- Convert a given chat transcripts to an appropriate Pytorch format such that my learn.model can accept it as an argument
- Access the last hidden layer?
Thanks!