Does anyone have a motivation for this transformation? It computes a debiased EMA of the loss (maybe inspired by this?) – but I don’t understand why you’d want to do that (esp. by default)
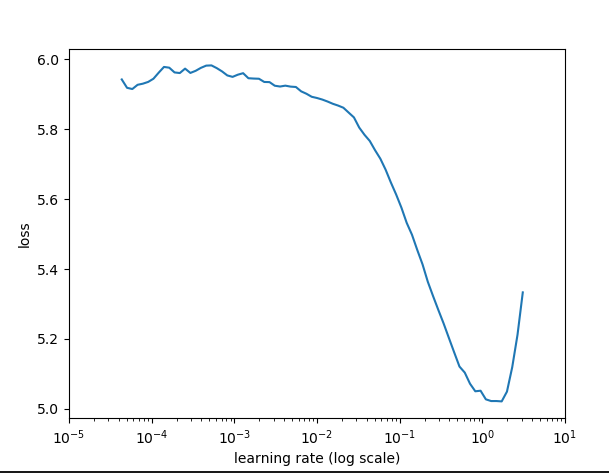
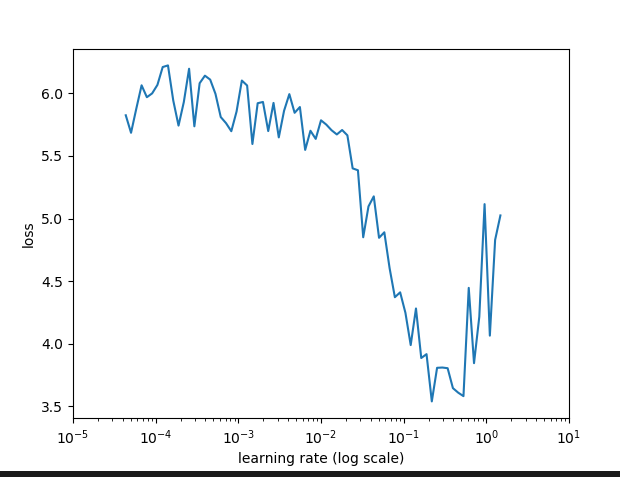
Specifically, I’m wondering about whether this is appropriate to use w/ the lr_find function. These are lr_findplots w/ using the EMA (as above) or the raw loss, respectively:
Raw loss is noisier (obviously), but the location of the minima are clearly shifted – about 2.0 for the EMA vs about 0.2 for the raw loss. I saw in the videos that @jeremy suggested finding the minimum and then going back about an order of magnitude – is this maybe because the EMA “delays” the minimum?
I’m also interested in the meaning of debias_loss. The TensorFlow fit method you linked to mentioned the Adam paper, https://arxiv.org/abs/1412.6980. In it they discuss “bias correction” (“debias”?). I’ll look into it more when I have time.
Yeah – ADAM uses a debiased estimate of the moving averages, but I’ve never seen it used in the reporting of the loss per batch as is done in the fastai library. After thinking about it more, I don’t think there’s any reason to do this besides preference for a smoothed loss.
I came here wondering the same and, after reading the StackExchange link shared by @Matthew, I think the goal using the debiased estimate is remove the influence of the initialization avg_loss.
I belive this is especially important when the number of batches is small. For example, with the initialization avg_loss=0 and avg_mom=0.98, if we have only 5 batches, all with loss=100, the value of avg_loss in each batch will be (2.00, 3.96, 5.88, 7.76, 9.61), which is clearly too low. Even with 100 batches, the final loss would be only 86.74. However, the debias_loss would be 100 for all the batches.
About the shift of the minima, I don’t think it is introduced by the transformation but just for the EMA.