I have a general question.
When starting a new project on either classification/localization, we often start with a pre-trained network. and fine-tune it for our special case.
Now, say the pre-trained network can handle already n classes and you fine-tune it to handle m custom classes. Is it possible to find an architecture such that we can actually now have a model that handle n + m classes ? Without applying model 1 and model 2 separately ?
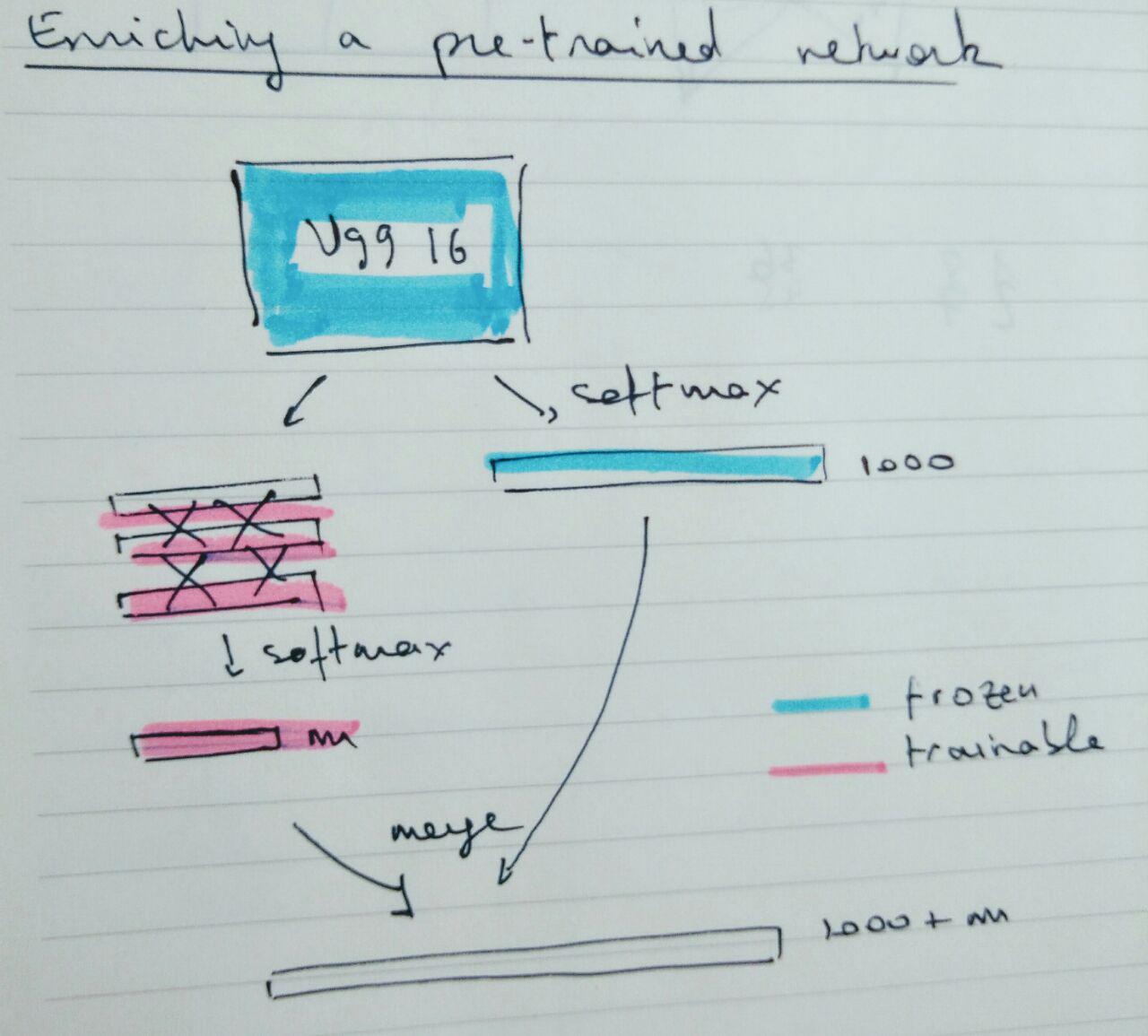
Concretely, can we “enrich” a pre-trained network with new classes without having to train again on the full initial dataset ? Hope I’m being clear I’d guess we can freeze an output layer with the say 1000 classes from VGG and then on another branch fine-tune… Not sure tho
It’s not a usual use case but there’s no reason why it shouldn’t work. Set the current network to untrianable and connect the output of the second to last layer (the 4096 wide feature vector if you’re talking about vgg) to the input of your new final layer. Essentially instead of popping the final layer you’re adding another alongside it. Then you just need to merge those two final layers for your output.
The only caveat I would add is that the new classes would need to be somewhat similar to the classes that you’re transfer learning off of since that’s where the intermediate features are derived from.

 I’ll try this. Thanks for your suggestion. I suppose you mean something like this ?
I’ll try this. Thanks for your suggestion. I suppose you mean something like this ?