@ilovescience It’s worth noting that my comments were for training from scratch, on ImageNet. Fine-tuning from the pretrained model is a different exercise that is typically less sensitive to h-params and requiring less epochs.
The EffNets are capable models, so no doubt they can produce solid results for Kaggle or other pretraining exercises. I just wouldn’t recommend them as a first choice on any given problem since they are more challenging to work with and a lot of their ‘efficiency’ benefit isn’t realized with PyTorch + GPUs.
Google AI team posted new EfficientNet weights with AutoAugment training. Improvements across the board, but only .1% top-1 by B7. However, B6 and B7 weights are incl this time round.
B6 & B7 are absolute monsters to run so haven’t updated all validation scores just yet.
Also interesting are the MixNet models. A promising idea to explore in other architectures. I had a shelved ResNeXt-like model with bottleneck 3x3 replaced by groups of 2 * 3x3, 5x5, and 7x7. It was converging nicely but I dropped it for other training priorities before completing. Must revist now.
@rwightman your repo is so great! One thing that could make it even better would be to add a training time column to the table of models that you’ve trained yourself. And maybe also max GPU memory use? Param count isn’t always a great proxy, as you know!
Retroactively, the training time is going to be a challenge. The way I train right now, I use a few different local machines of widely differing capabilities, best is probably at least 4x the worst. So, there’d be varying configs. Other challenge is that I often kill a training session and resume later if priorities change and I need to use a machine for another task.
Something I thought would be useful for this and other reproducibility challenges, is to keep a train history embedded in the training checkpoint. Basically something that records timestamp + hparam delta whenever an hparam or scheduled hparam changes. Embedded in the checkpoints it wont be lost across stop/restart or even moving to different machines. It could be later parsed and used exactly replay training for a given model despite manual tweaks. So, an ‘hparam replay buffer’ of sorts.
Max gpu usage is on the list of todos. I need to experiment more with appropriate sampling points and rates to capture a representative value. Capturing the state during validation/inference is usually reliable, but I see more variability and sometimes epoch to epoch fluctuation in training, especially with AMP enabled.
just tried to use the .freeze() method with Efficientnet as well as the discriminative learning rate with slice(x,y) in the fit_one_cycle() method, and it doesn’t work. I figured out that there’s only one layer group, which prevents fast.ai from freezing another layer group.
I tried to understand how I can tweak Lukemelas’ implementation to come up with multiple layer groups. Has anyone already implemented it or am I plain wrong on my assumption ?
Yes, I was going to report my findings on the forum, but I went through this post, it seems to me that it is about training from scratch so I didn’t weight in. Another important reason is the test is based on kaggle on going competition, using local cv, LB score to report model is not solid. But I will just share what I tried, at least for the current score, efficient net is outperform my resnet model (0.7x to solid 0.8+ single model)
I tried efficient net B0-B4 on current APTOS competition, with pretrained weights from imagenet.
Here is my experiment setup with b0
bs=64, img_size=224, default argumentation.
Plain efficient net b0, change the fc layer output to data classes.
Cut the model at head. Freeze the body, fine tune the head with some epochs, unfreeze, fine tune small epochs.
model.split(lambda m: (m._conv_head)) if you ever wonder the code
cut the model at the ._block middle. Where the filter size changed from 40-80. Another cut at conv_head.
So now the layer_group is 3
Gradual freezing, discriminative learning rate.
Surprisingly, the result is 1>=2 >> 3
Where I thought the order should be 3 > 2 > 1
Some thoughts:
Efficient net is scaled with best architectures so different lr doesn’t work?
I didn’t manage to find time to fully understand the paper, the cut is based on understanding of resnet. But as you can see, they are different.
Based on kaggle LB, b0-b4 has increased score linearly with same setup. Also, pay attention to img size, as efficient net also scaled input size.
I also have some questions in mind:
Should I cut efficient net?
Should I replace the conv_head with fastai standard head? Concatpooling, linear… etc. Based on my understanding, this changes the architecture of efficient net, so it is not scaled anymore?
Hey @fmobrj75 I am also playing around with Stanford Cars, did you use the lukemelas implementation of efficientnet? Do you have a notebook you could share, I’m struggling to get above 92.5% with b3…
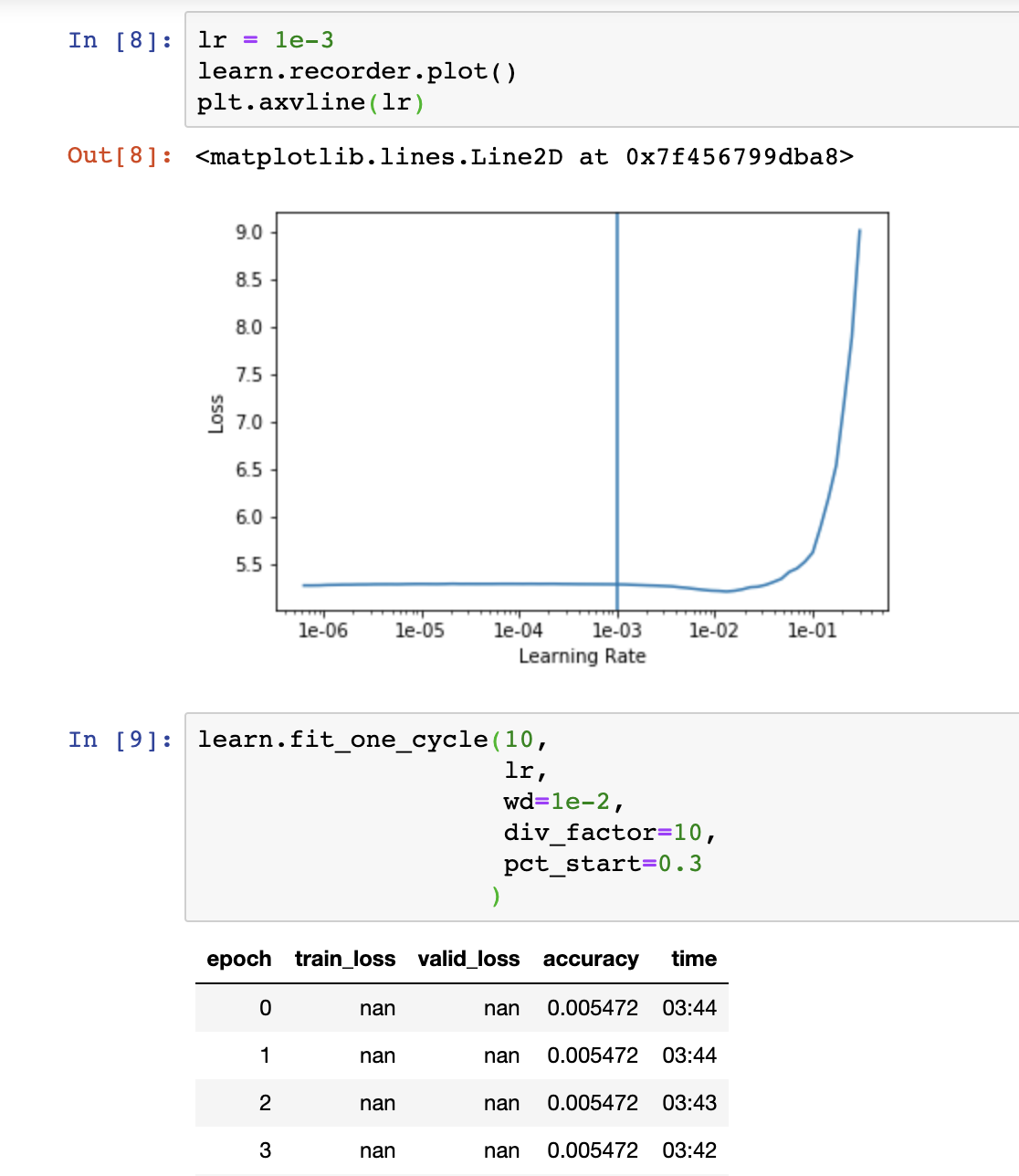
Has anyone had much luck on training Efficientnet b5 or higher? My loss keeps going to nan.
For reference I am training on Stanford-Cars and have been able to consistently get accuracy above 93.6% using Efficientnet b3. But with b5 either my losses go to nan or I make some tweaks so it can train but its results are far inferior to b3.
Move to a bigger machine (from P4000 to P6000) with more ram, to be able to use a reasonable batch size, bs=16 for image size 456x456 (b5 image size for the paper)
Used callback_fns=BnFreeze to freeze the BN layers. This worked (model was able to train), but its results were much worse than b5
Used Group Normalisation , again got it to train but results were really poor (potentially I need to explore a little more here though on the number of groups to use)
Higher LRs, Lower LRs…
Heres a typical call to Learner (b5_mish_gn_model is the model with GroupNorn instead of BatchNorm):
I only tried b0-b4 with imagenet pretrained weights. For b5-b7, I think you can check with @DrHB (don’t know how to tag people). But he is the one in APTOS 2019 with gold medal for Efficient Net B5+.
Thanks @heye0507, and congrats @DrHB! Looking through your notebooks (https://github.com/DrHB/APTOS-2019-GOLD-MEDAL-SOLUTION) I see you didn’t increase the image size for b5 like they did in the paper (456 in the paper vs your 224) and that you didn’t specify a particular learner (default AdamW)
I’ll go back to basics and give these a go, maybe I was overthinking things
For image size, you can use smaller size as what introduced in the paper, but if you want to push the last droplet from the model, you’d better use the size they said in the paper.
Base on my understanding, I tried effb2, image size = 260 (which is the one in the paper)
effb4, image size = 256 (which is not the one in the paper)
For LB scores, yes, effb2 can have the same result as effb4. I don’t have a powerful machine, so I didn’t push the limit.
Another thing I tried is using rAdma as optimizer, and it did increase my effb4 LB score.
Thanks @heye0507, I’ll settle for some form of successful training run before asking for max performance
Still no joy, with a simplified setup, getting hit by nans again. I wonder if its something to do with my machine…its probably not the weights since it worked for @DrHB…
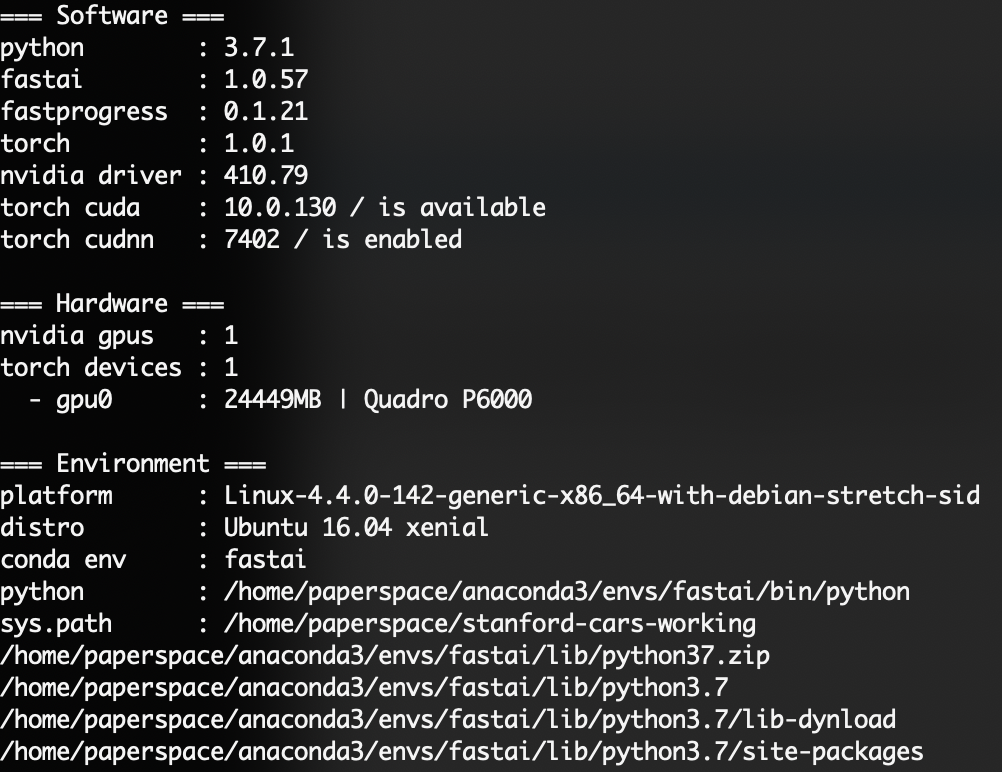
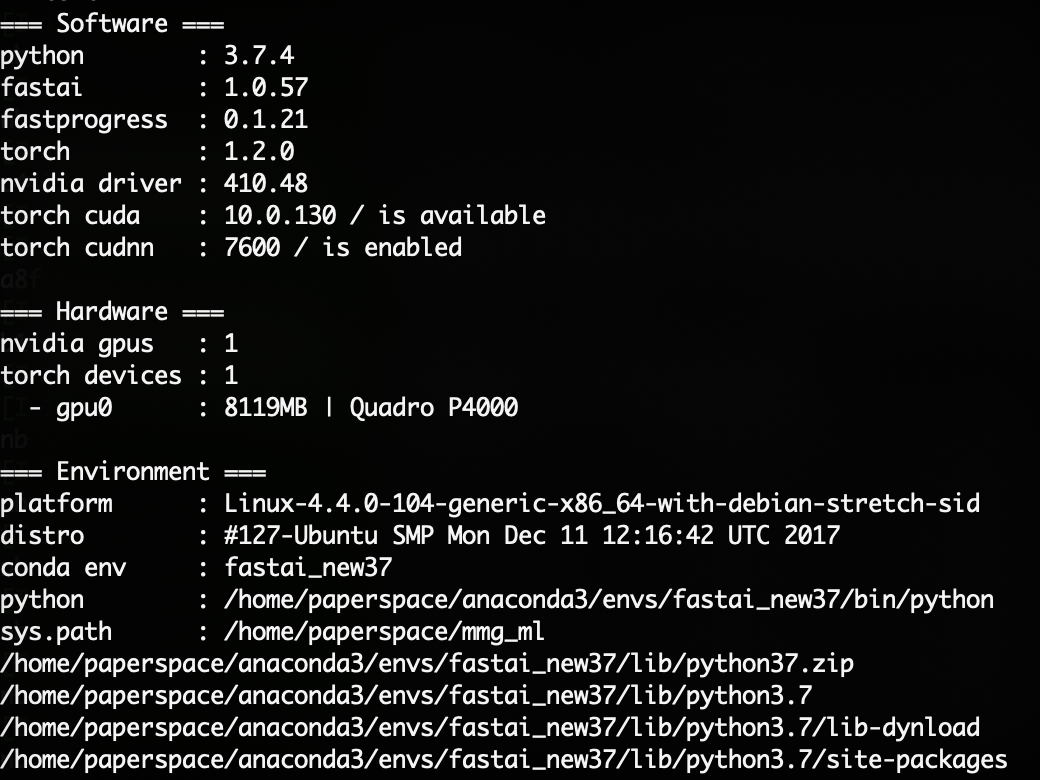
Hmm its something about the machine/installation I think. I was running my previous successful b3 runs on a p4000, but I just tried the same b3 run on the p6000 and its also giving me nans. So maybe I need to try a new environment with a fresh installation. I can see the working machine has pytorch 1.2 vs 1.0.1 for the p6000, hopefully its that!
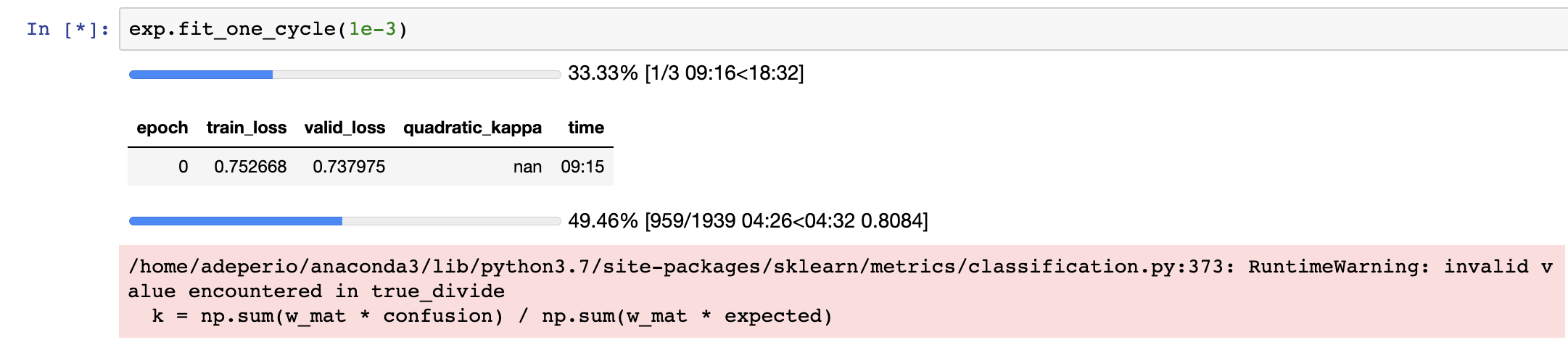
I’m not sure if this is related, but with 224px images, and using eff-b5 and batch_size=16, my train and valid loss comes through ok, but using the quadratic_kappa metric gives me nans on only some of my epochs.
 One thing that could make it even better would be to add a training time column to the table of models that you’ve trained yourself. And maybe also max GPU memory use? Param count isn’t always a great proxy, as you know!
One thing that could make it even better would be to add a training time column to the table of models that you’ve trained yourself. And maybe also max GPU memory use? Param count isn’t always a great proxy, as you know!