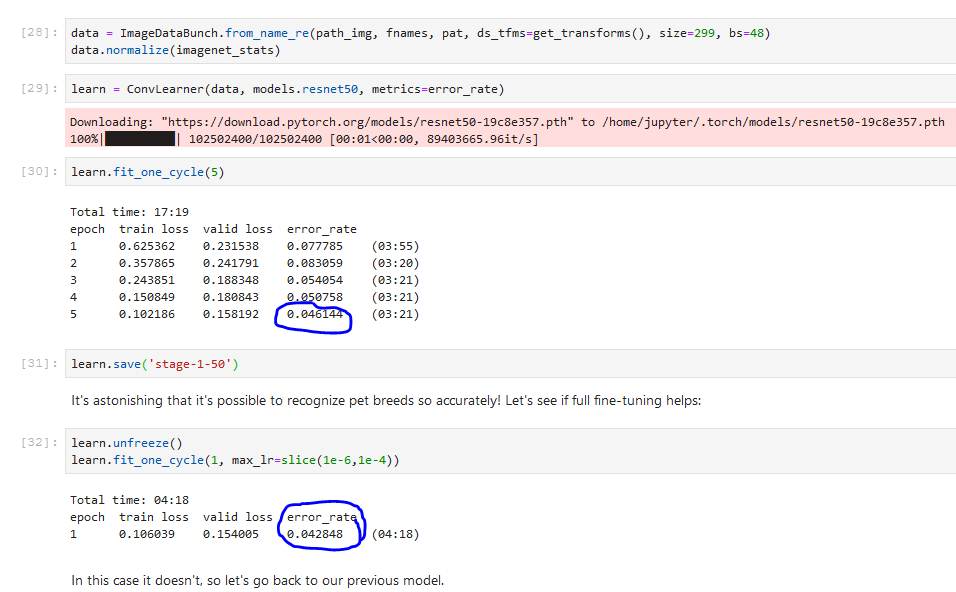
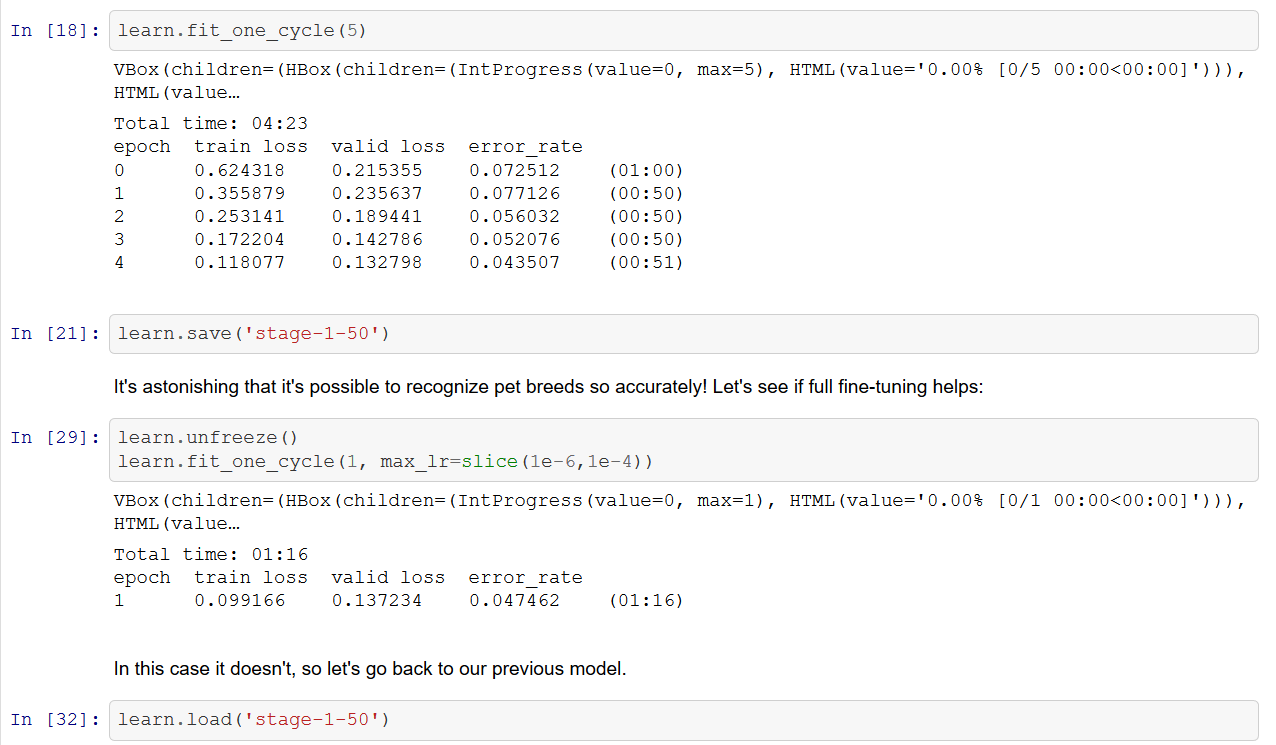
What could be the reason for getting different results when I ran the notebook as compared the results on the github notebook? Does this mean that the neural network generated by the ConvLearner function has different weights every time the code is rerun? If so how can I get reproducible results?
There’s a lot of randomness in initialization and training, so you can never get exactly the same result (even if you try fixing all the random seeds, some CUDA operations are non-deterministic). But if you train models to convergence, they tend to end up around very similar losses/error rates.
Thanks, as a follow up to that, when I use the model to evaluate on the test set, how do I pick which one to choose? Do I use whichever gave me lowest error rate on the validation set or would I have to iterate through multiple models? I guess my question is will a model that has lowest error on a validation set have lowest error rate on the test set as well?
It’s not necessarily the case that the model that does best on validation will do best on the test set. You may model the distribution of the test set incorrectly, or it might be different in other ways. In Kaggle competitions, it’s always a challenge to choose between the model that does best on your own validation, versus what does best on the public leaderboard (and then there’s also a private leaderboard that acts as a “true” test set, where models are only evaluated on it after the competition is complete).