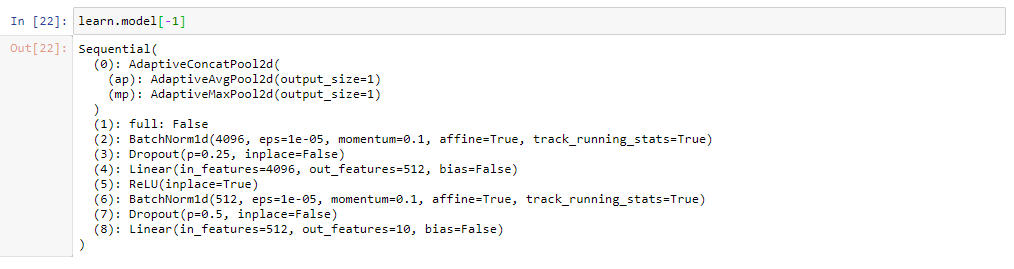
It’s actually not! There’s quite a bit happening in the background if we look at the source code for cnn_learnerhere. What we find is first we pass in a configuration. From this configuration we split our model into two different groups in which we fine tune on (first the frozen then we can unfreeze) just like we did in lesson 1. What’s different? Learnernever splits layer groups and freezes, you have to do this outside of Learner (because this is the base class, you won’t assume we will always transfer learn). Along with this, we see that cnn_learner calls create_cnn_model which then does 2 things:
Make a body of our architecture (removes the last layer group so we can transfer learn)
Create a fastai2 head for our model, which is more than just one last linear layer, and then initializes those weights for the last layer randomly.
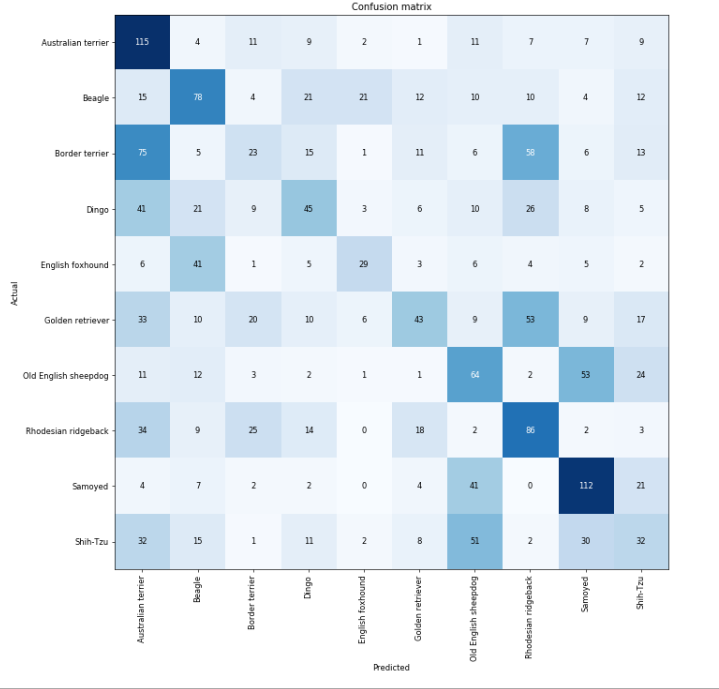
This behavior is the exact same as V1 vs V2 (V2 will also normalize if it’s assumed too among other things that are different but the main bits are the same). Also, you most likely still have the original 1000 classes as the output of your model (check by doing learn.model[-1] and the dimensions should be 1000). This can be another cause too.