I’d like to generate latent factors for these widgets, essentially “widget2vec” (inspired by word2vec).
My hope is to use a similar approach of word2vec by using co-occurance pairs of widgets (instead of words) to training a model. In contrast to word2vec which defines co-occurance as ‘appearing near each other in a sentence’, I’d define co-occurance as ‘sharing an attribute.’ For example, lets say widget_1 and widget_2 both have attribute_a=1. Because they share this attribute, they are considered valid widget pair. To train the network, I would feed widget_1 into the network and train it to predict widget_2 (and vise-versa). The first layer of the network would be an embedding, which I could extract after training as my widget2vec.
Has anyone tried something similar? Or does anyone have know of any resources related to this approach? Or do you have any general thoughts on whether an approach like this would work?
I found a really interesting paper that addresses exactly the use case I’m trying to solve. Basically given a set of widgets, predict the most likely other widget that should be part of that set. (And generate latent widget embeddings in the process to be used in other models).
A bunch of parts of this paper it are over my head. Specifically their generalization of Fully Visible Boltzmann Machine, Matrix Factorization, Log-BiLinear models, and the Restricted Boltzmann Machine model as different types of “energy models.”
I haven’t come across “energy models” before, but found a Quora post by Ian Goodfellow that doesn’t seem that scary.
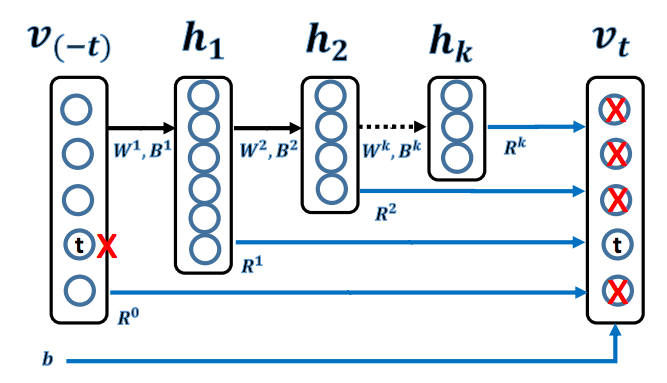
The Deep Embedding Model section of the paper doesn’t seem that complicated (page 4&5), and I think I’ve got my head wrapped around the general concept. However I’m having trouble figuring out some of the details. Like how those skip levels shown in the model are being handled
Are those single activations being propagated forward? Or is it more like ResNet where the entire output of the layer is passed forward and concatenated / summed into a later output?
Thanks @jonpollack, those are interesting pointers.
I’m also trying to do something similar: create word2vec-style vector representations for a series of loosely defined “objects”, each with a varying number of key/values.
At the moment I addressed the problem with Gensim’s doc2vec implementation which is fast and trivial to use, but I was looking for an approach like the one you suggested. An alternative I’d like to explore is to use DGANs for generating the embeddings.
Did you make any progress on this that you’d like to share here, since your post of April?
Ah, I still think it’s a super cool idea, but we were unable to get it to work with our dataset. Basically what happened was that we built our co-occurence matrix and then realized that matrix was too sparse to provide any meaningful signal. There must be techniques to reduce the matrix size and end up with a stronger signal, but we didn’t explore that too deeply. We actually did the same thing you did and are also using Gemsim’s doc2vec.