Hi
I’ve been experimenting with language models for the past week and I finally trained a decent model to predict chemical structures (I will post about it soon!) .
But there’s something on my mind… is it possible to define the position of the predictions?
For instance
Suppose an input string:
“c1ccncc1”, which represents pyridine in SMILES notation. As we can see there are different positions on the ring depending on the distance to the nitrogen (N) atom.
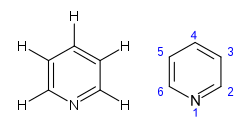
When I call learn.predict(TEXT), can I define in which position of the TEXT the next token will be added? From a chemical perspective that can change many properties of the molecule, such as charge distribution, synthetic viability and even biological properties.