Awesome work @ste, @zachcaceres. Just ran through everything and is working well for me. In fact the accuracy I’m getting is much higher than what you’ve reported in the notebooks!
I’m getting some errors due to the way you are raising exceptions. Would be happy to create a PR to change these
I really like how you’ve created and tested the classes in notebooks but wouldn’t it be easier to just have the actual code for the package separate and use ?? to see the source code. You wouldn’t need to run the buildFastAiAudio.sh script then either. This also makes creating a pull request to change the basic classes such as AudioData and AudioItem a lot easier. Merging notebooks can be a nightmare from my experience as the outputs are saved. PR
Would it be possible to have the timit dataset downloaded as done in the AWD_LTSM notebook.
Do you think it would be better to have a small set of wav files tracked in git for getting people up and running faster with the notebooks.
What do you intend to do with show_batch have spectograms show with audio underneath?
Currently you have add the custom layer manually on top of the cnn learner. A custom learner might be good here?
I noticed that the transform to spectogram wasn’t expanding the channel dimension to 3 as is done by the library for the mnist dataset. I’ve added that into my fork of the project. You were replacing the first Conv2d layer which would loose all pretrainined learning? I may be wrong about this.
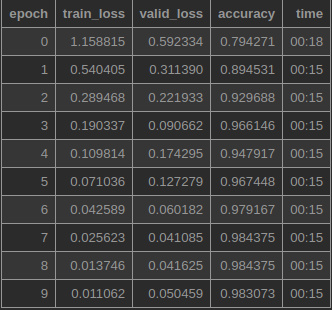
After making these tweaks I checked to see how well this approach performed on Free ST American English Corpus datset (10 classes of male and female speakers) I was able to get these results:
Seems the kernel showing 3d spectrogram, but it is actually just for convinient visualization. x-y is time-freq , z axis is amplitude which is the same like color in our 2d spectrograms… So no extra info added by using 3d…
I can imagine a useful 3d spectrogram like, multiple channels of sounds in the z axis. Like stereo, or more interestingly microphone array sound spectrograms concat. in the z axis for sound localization… I have thought about this before…
I’d suggest using the tools/run-after-git-clone stuff in the fastai repo to avoid this. See the fastai docs for details. Also try the ReviewNB service - it’s great.
Totally agree, the 3d spectrogram is very much a “human” vis and not a different representation of the data.
Check out @ste’s branch of the fastai-audio repo for an example of using not quite a different representation, but a kind of multi scale representation, (ab)using the fact that we’re really only ever training on tensors whether us puny humans can see them or not.
I was thinking of another way of aggregating - and then visualising - the information in an audio clip besides a spectrogram, but it really does capture most of what’s there.
It would be interesting to experiment with different kinds of spectrogram (“raw” vs. mel, power vs. amp vs. db) and different values for the params (number of FFTs, number of bins, bin size…). Honestly we’re just trying to find what looks “good” to our (puny) human eyes; there’s no guarantee that the prettiest image does the best job of helping a NN discriminate. For my next experiment I want to try making really “high def” spectros to train on.
And also interesting to play with the effects of audio signal transforms vs spectrogram params on the accuracy of the network. For example, if you augment your data by downsampling, but keep your spectrogram #ffts & #num_mels constant, will the “image” presented to the network actually be substantially different?
We haven’t tackled normalisation yet, either; and that could cancel out some assumed audio transforms, eg if you add white noise to every sample, and then normalise, you’re basically removing the noise you added…
There’s a lot to be learned here - and now a Kaggle comp to learn it on
Hey Baz, if you check out the “doc_notebooks” branch on the main git repo you’ll find a few changes. I changed all the notebooks to use the public dataset, changed the exception handling, made a few other cleanups, optimised some of the transforms, fixed a pretty critical bug with the spectrogram transform step, etc.
We’ll merge this in with the cool stuff Zac and Stefano have been doing on Monday, but thought I’d let you know in case you’re playing with it over the weekend.
And the “baseline” demo workbook now gets 98.4% accuracy maybe it will go even higher with your model layer modification!
We’re still actively working on this; you’ll be able to see Stefano has been testing ideas “manually” in his notebooks when we merge them (or it might already be there in a branch!), and the DataAugmentation notebook in the doc_notebooks branch has a slightly improved comparison helper. Ideally I think we’d want a pretty rich display widget that let you hear the original & transformed audio, see the original & transformed waveforms, and let you see the final post-transform spectrogram that the network is actually seeing. It’s a little tricky - because the way we’ve handled the transform (using the wav-to-spectrogram as the final step) it’s hard to access the “transformed -1” state. We’re debating whether it’s best to change the way the AudioItem handles being transformed (eg. adding a concept like “transform groups”) or change the way it __repr__s itself. I’m wondering whether it’s best to dig into Jupyter’s custom display() handling (particularly _repr_html) to make a richer show. We’ve even thought of a sub-project to make an ipython widget based tool to help you test and select transforms on the fly! I think it’s definitely something to focus on, as there is so much to experiment with, we’ll get high leverage from making tools that ease experimentation. Feel free to help!
FWIW, I did this last night, and it wasn’t good. It took ages to train because I had to use a tiny batch size, and was overall less accurate than using the relatively lo-res ones. So, not recommended.
There are many other variables to consider, as well; for example, the naive “pad to max” we use in the current demo notebook adds a LOT of zeros to the vast majority of samples, so doing a smarter uniformity selection would probably be advantageous (something like pad from end by average length"). (I suspect the reason the higher res specros were worse is because the relative amount of 0 bins was higher).
I’d also be interested to try progressive resizing - train the model on low-res spectros first, then generate higher and higher res ones to see if it made a difference. It would be interesting to do this at the audio level too (i.e. downsample to 8KHz first).
Keep in mind though that we are trying to adhere as closely as possible to the recommended FastAI workflow. There are probably things that we’re doing, such as writing the code in notebooks and aspects of code style that may break with typical software engineering practices and PEP8.
But this has been a conscious decision – because the hope is that this work can be harmoniously brought into the course somehow. Hopefully that doesn’t discourage you from PR’ing and collaborating
Last weekend I found the older fastai-audio package someone was working on and tried to build a simple pipeline to classify this dataset.
I kept getting tensor size mismatches and suspect this is because the library didn’t handle stereo audio.
These are all awesome questions.
Any audio experts have suggestions?
I understand that we’re using spectrograms because resnet is already trained on images, and we want to leverage that pretraining.
I personally wonder if we could get better results by working with raw waveforms. I know there’s been a lot of work with stuff like waveNet, and recently I saw a neural Vocoder [0] that seem to deal with audio in a fundamentally different way.
Also, when first approaching this problem I read [1] which suggested in its abstract that feeding raw waveforms worked better than Spectrograms, and that was from 2009 and seems to have some … pretty important authors.



 maybe it will go even higher with your model layer modification!
maybe it will go even higher with your model layer modification!