I am training a model to classify whether a sentence comes from Wikipedia or from Simple Wikipedia. (colab link)
The dataset is quite large, so there are 3,000 batches of size 64. It runs correctly for the first 600 batches, but then runs out of memory:
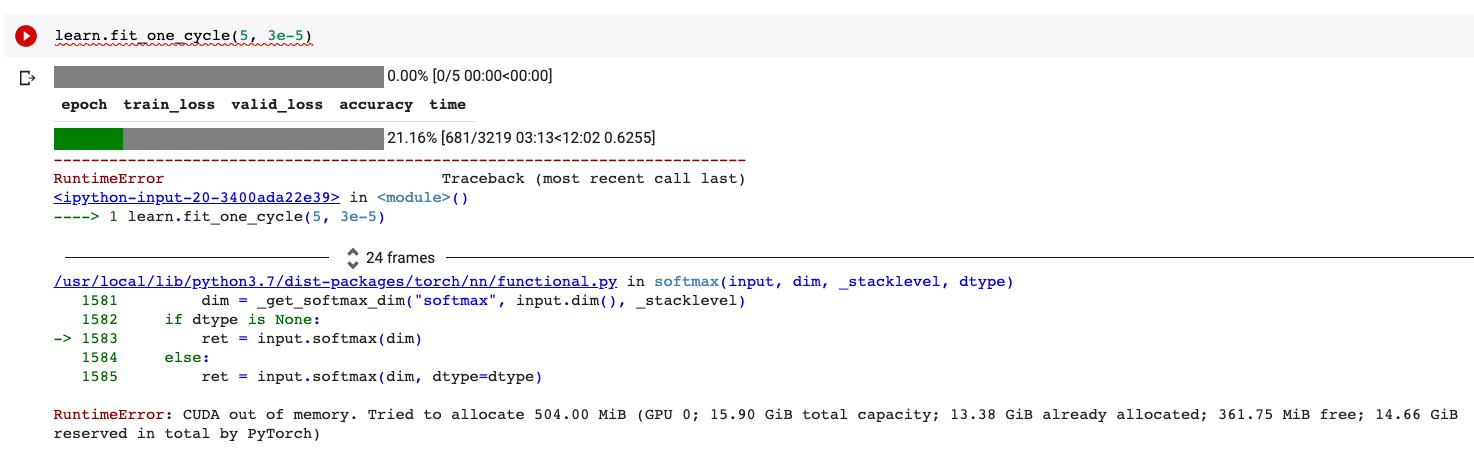
This makes me think that the problem is not a large batch size - if the batch size were the problem, it would have failed on the first batch. Instead, it seems more likely to be a problem with some sort of accumulator variable (pytorch docs explain the problem here).
My code is extremely simple, which makes me think that the bug may lie within the fastai library itself. My code looks like this: (full code on colab)
learn = Learner(
dls=dls,
model=Model(),
loss_func=CrossEntropyLossFlat(),
)
Is it possible that some internal variable is accumulating gradients and causing cuda to run out of memory? (it looks like we dealt with a similar issue in the past here)