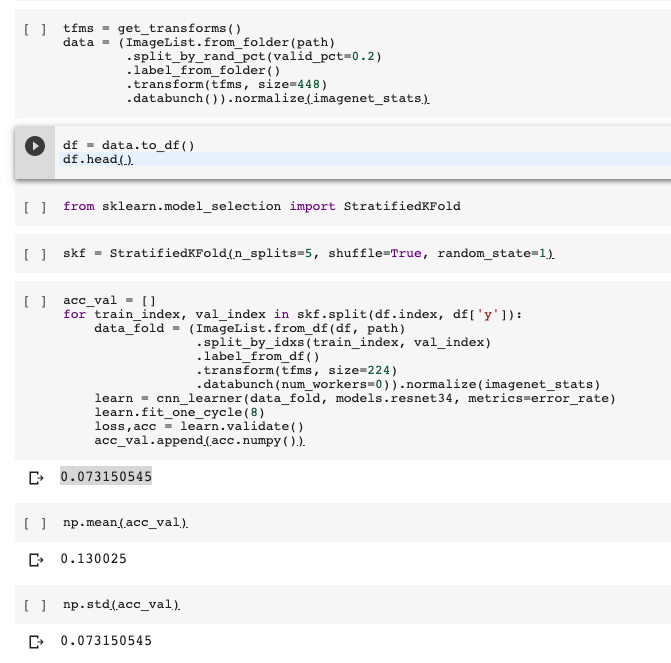
no intro, just sharing how to do CV predictions with fastai for train and test sets. Why not with ImageClassifierData.from_csv ? - well, because it gonna precompute activations every time you change folds both for train and for test. Obviously it should be enough to precompute activations once and than just change train/validation sets based on CV indexes.
Inside the CV cycle is where you train, and predict/test, correct? And then after you’ve trained your 5 models, you average the predictions together to get a final prediction?
I like @jeremy’s recommendation to just set precommpute=False. If I understand things right, it would eliminate the need for the change_fc_data function.
I’m trying to do cross validation also and I’m getting weird behavior. That is, every cross validation set except the first cross validation set gets a huge boost in validation accuracy when I switch to precompute=False for one epoch after many epochs with precompute=True. I’m talking like 85% to 97%. The first set stays essentially at the same accuracy when I switch to precompute=False (85%-> 86%).
My question is - did you implement this solution to make the training faster because you don’t need to precompute activations again? or is there something inherently cheating about doing cross validation after you’ve already precomputed the activations with one set?
For the record, I’m doing something similar to the dog breeds prediction, but I’ve made csv files containing indexes of stratified validation sets that refer to the csv file containing class+path.