Hi,
I have the following specification for the datablock to train a multicategory computer vision model:
dblock = DataBlock(
blocks=(ImageBlock,MultiCategoryBlock()),
get_x=get_x,
get_y=get_y,
splitter=splitter,
item_tfms=Resize((90,160), method=ResizeMethod.Squish),
batch_tfms=[*aug_transforms(size=(90,160), min_scale=1),Normalize.from_stats(*imagenet_stats)])
I used it to train a convnext model which went fine but when I printout the confusion matrix for the learner, it is only showing two classes as follows:
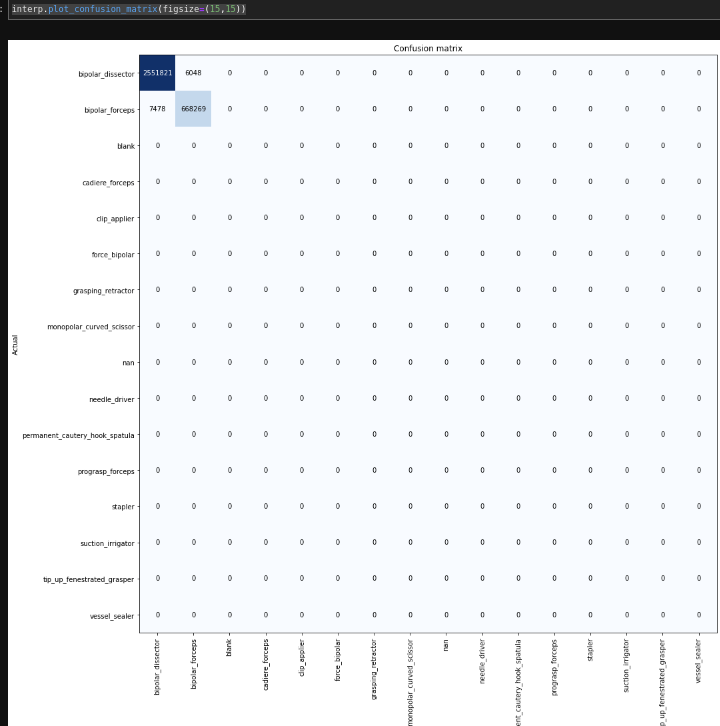
I thought that the validation set may not contain all the classes so I run the following code to verify the class labels in the validation set:
dsets = dblock.datasets(images_df)
ys = [i[1] for i in dsets.valid] # took a lot of time. There might be a bettter way to get ys from dls.valid
idx=[]
for item in ys:
for i,y in enumerate(item):
if y.item()==1.0:
idx.append(i)
idx=list(set(idx))
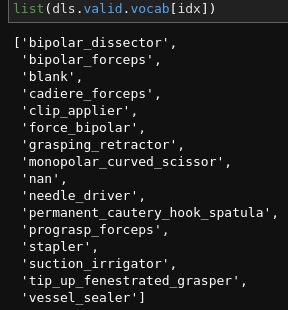
list(dls.valid.vocab[idx])
So I was wrong as the validation set contained all the class labels. See the output below:
Did anyone else encounter the same issue? Any guidance in fixing it will be much appreciated.
Thanks in advance
Best regards,
Bilal
