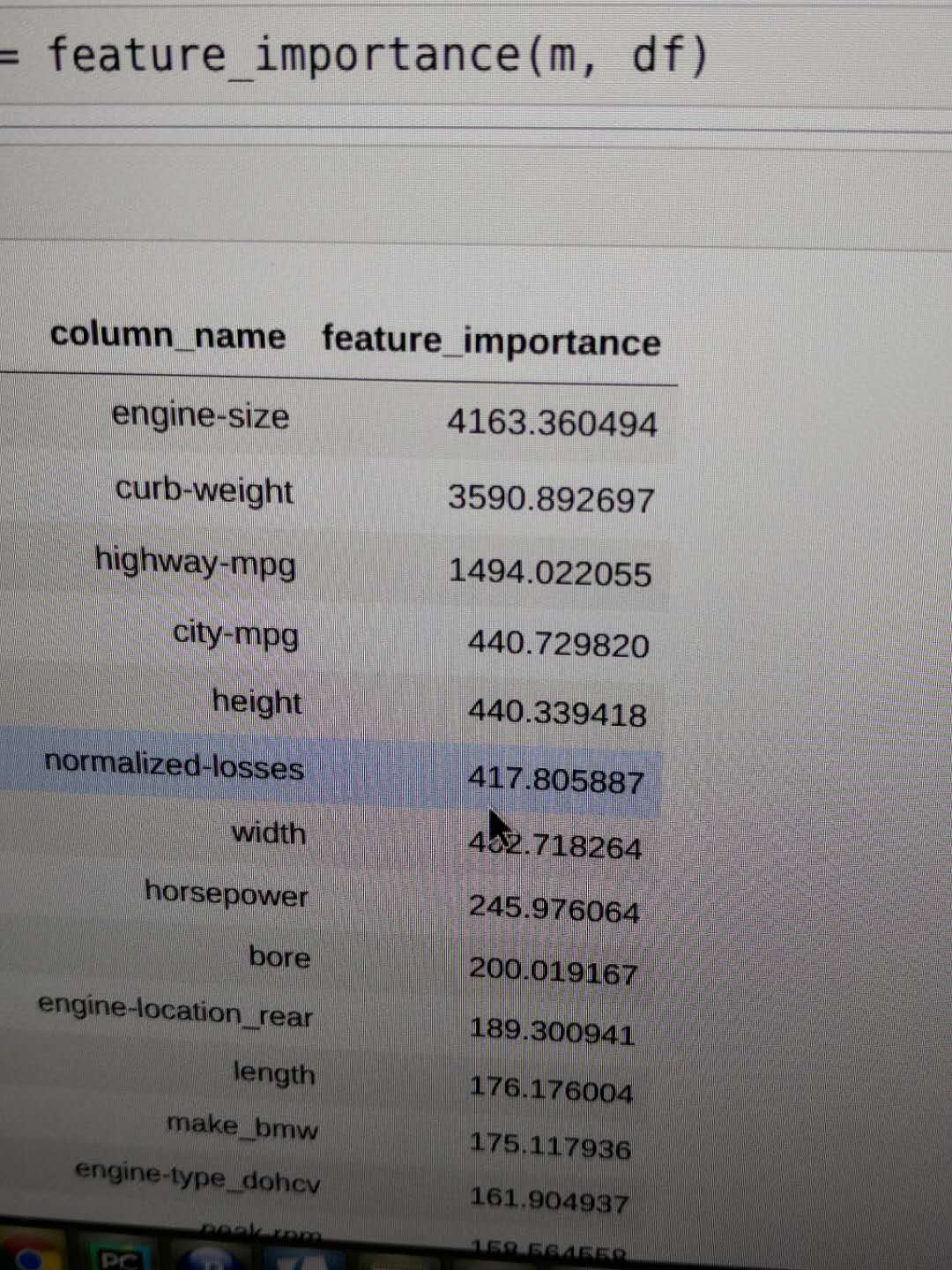
It depends on the feature importance implementation in scikit, what metric they are using and how they are calculating it. In general, I would probably focus on my metric of interest (business or Kaggle) then calculate validation differences for each shuffled feature. So here there is no perfect solution, but this approach at the same time makes it very flexible and powerful. It is metric and model agnostic
So, as long as you are confident about what you measure I wouldn’t worry much about getting it “right”