Hello,
I recently got a dataset of around 900 satellite images labelled by 6 cloud experts into 6 categories describing the type of cloud structure. They asked me whether I could build a classification network to automatically label new images.
Since I recently started Part 1 v2 I though I’d try doing this with the fastai library. This task poses several challenges:
- The experts most of the time didn’t agree on one category. Therefore, I have probabilities for each category rather than hard labels. As far as I could tell, the fastai ConvLearner didn’t support this, so I wrote my own hack to make it work.
- The dataset is super small. This makes transfer learning mandatory.
- The dataset is super imbalanced. For this we would probably want to use oversampling.
Here is my notebook which has images of the clouds and all the networks: https://github.com/raspstephan/cloud_classification/blob/master/cloud_classification.ipynb
Additionally, here is my fork of the fastai library where I hacked in the probability label support: https://github.com/raspstephan/fastai/tree/prob_classification
If anyone has any ideas for how to make my model better, that would be amazing. Also if you have any questions about the meteorological background, just let me know.
A quick update on dealing with the class imbalance.
Here is a snapshot of the class imbalance from the notebook.
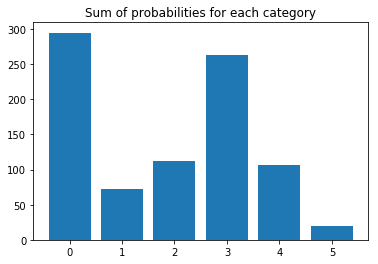
Looks pretty bad. Even worse, the 0th category is the “no fit” category when none of the other classes apply.
I tried the oversampling approach suggested in this paper: https://arxiv.org/abs/1710.05381
I thought a little bit about how to do this for my fuzzy labels. In the end I decided to preferentially sample those images which reduce the imbalance the most (code is in the notebook). Here is what it looks like after this procedure (blue - before, yellow - after).
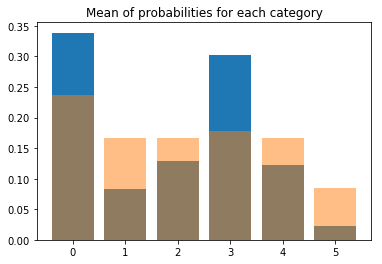
But one question remains: How do I validate my model? Should I use
- oversampling as well (with some images occurring more than once)
- just data from the real distribution
- or specifically pick images to achieve a balanced set (with unique images)?
After thinking about it for a while, I think it really depends on what you want from the model. Since we don’t want a model that always predicts the “no fit” class, it also wouldn’t be very useful to evaluate it with such an imbalanced dataset. In fact, I think it might be useful to do a data augmentation (flipping) even for the validation images. This is not possible in the fastai library right now from what I can tell, right @jeremy?
Finally, the paper mentioned above also suggests doing a Bayesian post-processing on the predictions called thresholding, where they state that “thresholding should be applied to compensate for prior class probabilities when overall number of properly classified cases is of interest”. I am not quite sure yet whether this applies to my problem.