I am struggling with the code in chapter 17 of the book. As an R user my Python is just acceptable. I do not understand the following issues from this function:
def relu_grad(inp, out):
# grad of relu with respect to input activations
inp.g = (inp>0).float() * out.g
What is the concept behind “.g”, what is it called? I.e. why does relu_grad not need a return and instead changes the inp variable by adding a “.g” attribute?
How can inp be modifed in the function and be available out of the function’s scope?
This is also done in the section “Refactoring the Model” of chapter 17 but within the classes:
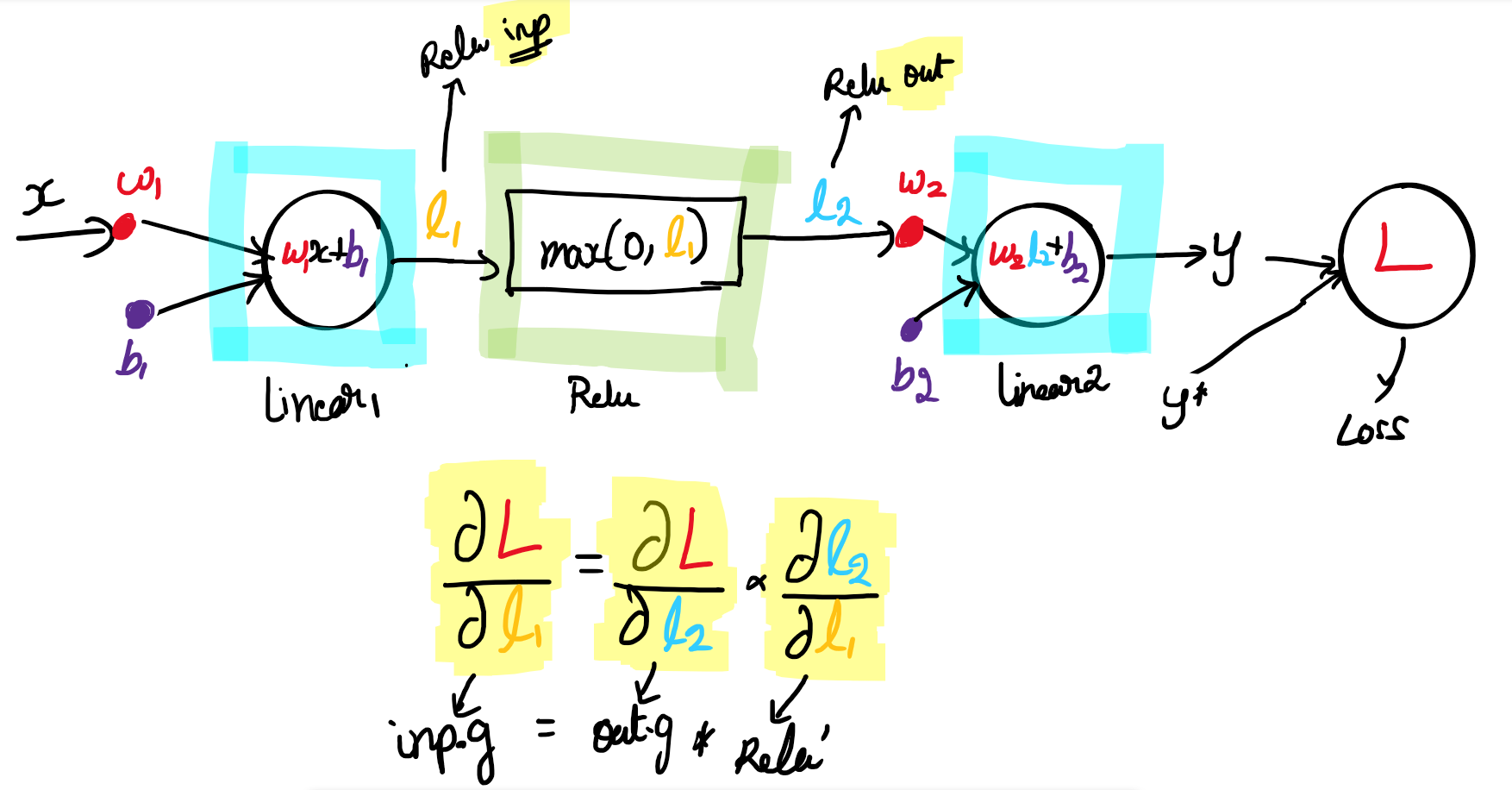
Here, the .g attribute represents the gradient. Do you understand conceptually how gradient calculations work in backpropagation? This is just the code that implements that for relu.
The way it is done here is similar to pytorch in style - gradients are stored as attributes, so since inp and out are objects with gradient attributes, we can just modify them in place if we want to and that change will persist outside the function (and there’s nothing to return here).
You don’t need to import attributes for objects - if the objects are within the scope of the function, then you can access them and modify them in place. I think this is similar to R’s $ syntax for setting attributes - the equivalent would be something like out$g as far as I understand R.
With python you can set attributes to any objects. More explanation of attribute here.
By using a .g we have manually set an attribute, which store the gradients calculated. Pytorch accumulates the gradient of the tensor in .grad attribute, removing the need for manual calculation. The code here mimics the behavior of .grad using .g
Now the gradient of input inp.g can be given by chain rule as out.g * Relu'
Note: Relu' denotes the derivative of Relu
In the first code, def relu_grad does this explicit calculation. With the refactored code, the logic is placed in the function .backward to denote the behavior of Relu during backprop, similar to what is done in Pytorch.
This gets called when model.backward() is called, this is shown in the code at subsequent pages.