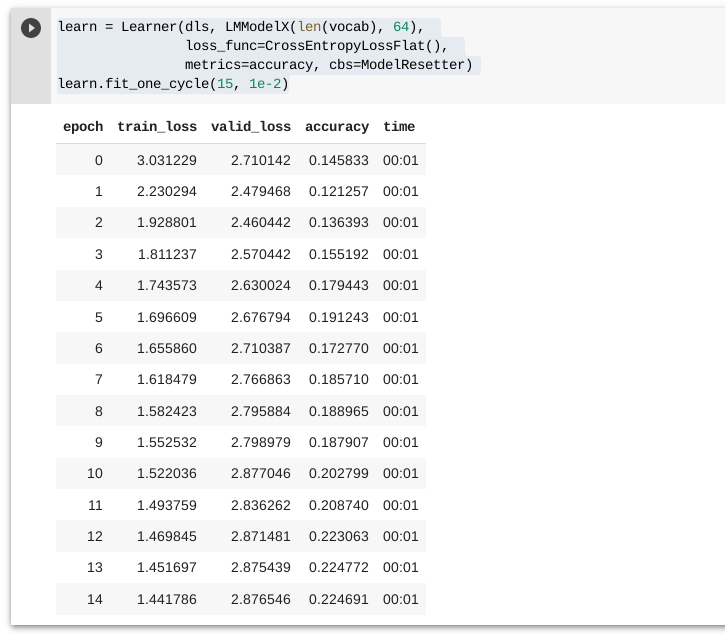
I tried implementing LSTM basd on LSTMCell. I am getting low accuracy (~20%) on HUMAN_NUMBERS dataset. Please take a look at the code and correct me if i’m doing something wrong.
Pre-processing - Similar to fastbook (Chapter 12)
bs = 64
sl = 16
seqs = L((tensor(nums[i:i+sl]), tensor(nums[i+1:i+sl+1]))
for i in range(0,len(nums)-sl-1,sl))
cut = int(len(seqs) * 0.8)
dls = DataLoaders.from_dsets(group_chunks(seqs[:cut], bs),
group_chunks(seqs[cut:], bs),
bs=bs, drop_last=True, shuffle=False)
LSTMCell - Code from fastbook
class LSTMCell(Module):
def __init__(self, ni, nh):
self.forget_gate = nn.Linear(ni + nh, nh)
self.input_gate = nn.Linear(ni + nh, nh)
self.cell_gate = nn.Linear(ni + nh, nh)
self.output_gate = nn.Linear(ni + nh, nh)
def forward(self, input, state):
h, c = state
h = torch.cat([h, input], dim=1)
forget = torch.sigmoid(self.forget_gate(h))
c = c * forget
inp = torch.sigmoid(self.input_gate(h))
cell = torch.tanh(self.cell_gate(h))
c = c + inp * cell
out = torch.sigmoid(self.output_gate(h))
h = out * torch.tanh(c)
return h, (h, c)
LMModelX - Single layer LSTM model
class LMModelX(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.rnn = LSTMCell(bs, n_hidden)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h = [torch.zeros(bs, n_hidden) for _ in range(2)]
def forward(self, x):
outputs = []
for i in range(sl):
res, h = self.rnn(self.i_h(x[:, i]), self.h)
outputs.append(res)
self.h = [h_.detach() for h_ in h]
return self.h_o(torch.stack(outputs, dim=1))
def reset(self):
for h in self.h: h.zero_()
Learner Result: