I would like to know if we remove one (or some) image(s) from a training data set, is there any way to calculate the impact of it to the model. We know that for Deep Learning algorithms we need a lot of data, but there should be a way to conclude that for my model, image A is more important than image B?
I have just started Deep Learning adventure and very exited about finding this web site. It is my first question on this forum. Hope it is not too boring
If your dataset contains lots of images (say > 10k), removing just one image is likely to not have any visible impact on your model. If you are dealing with a tiny dataset, it may have an impact. I can think of one way to check the impact but it’s a bit tedious. Just train the model from scratch twice with dataset_full and dataset_mins_one_image and see if there is a difference. You will probably need to run that experiment a bunch of time and then average the results to make sure the change is not due to a different weight initialization.
The neural net is trained based on the loss function, and the loss function measures the difference between the training labels and the model’s predictions for the training images. If you remove an image from the training set, the loss function changes, and therefore the loss “landscape” that is used for SGD also changes. In other words, your model is now learning a slightly different function.
However, since we train on mini-batches and not the entire training set, the loss landscape that SGD sees is quite different with every training iteration. And since we shuffle the images with every epoch, no two mini-batches will ever be the same (especially when training with data augmentation). We therefore never train on the true loss function, only on a very rough (and mostly wrong) approximation of it.
The point being: what your model learns is an approximation of your “real” loss function / training data anyway. The impact of a single image may be different each time you train the model, because of the randomness involved in the training process.
Can you give an example where you need to make this kind of decision?
In general, all images are important, i.e. you hardly want to throw away images.
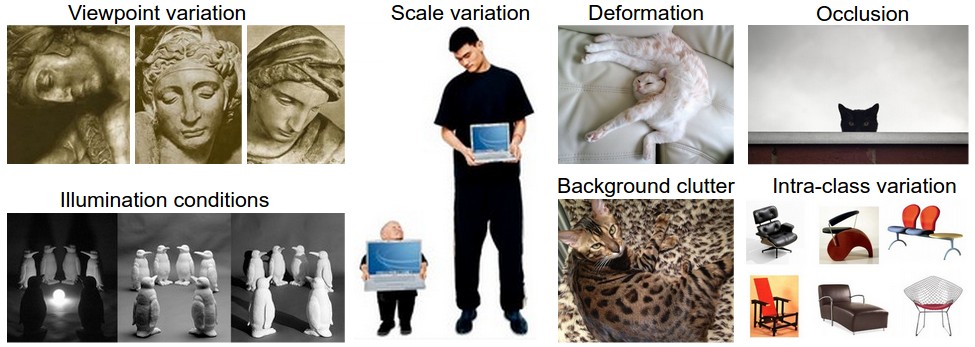
For e.g. if you are building a cat/dog classifier, you want all kids of cats and dog images in all kinds of positions and lighting conditions and framings and postures and … to be present in your training set - so that your model can recognise a cat or a dog in all these situations. You want your model to be invariant to these variations.
But ofcourse, for a cat/dog classifier, images of cars might be irrelevant.
When I try to understand Deep Learning algorithms and steps, I always compare with other ML algorithms, that I have some experience. And one of the first things that we do, is to detect the outliers. Because, outliers change the model completely: so I can calculate the impact of an observation to the model.
Maybe the right question would be: is their outliers for DP algorithms, i.e. any images that have completely different features and change behavior of model?

{kind=link}