Thanks for the clarification.
but i was hoping that i can use 10% if training for validation and leave test data intact for TTA after training. I never thought that it will take randomly from training and testing set combined. it has not been clarified in the docs either.
Conceptually validation data should be kept separated from testing set (as well as testing set). and in many ML packages validation percentage are partitioned from training set only, not training and testing set combined.
if validation_pct is being taken from training and testing combined then any statistics calculated on testing set at the end are biased.
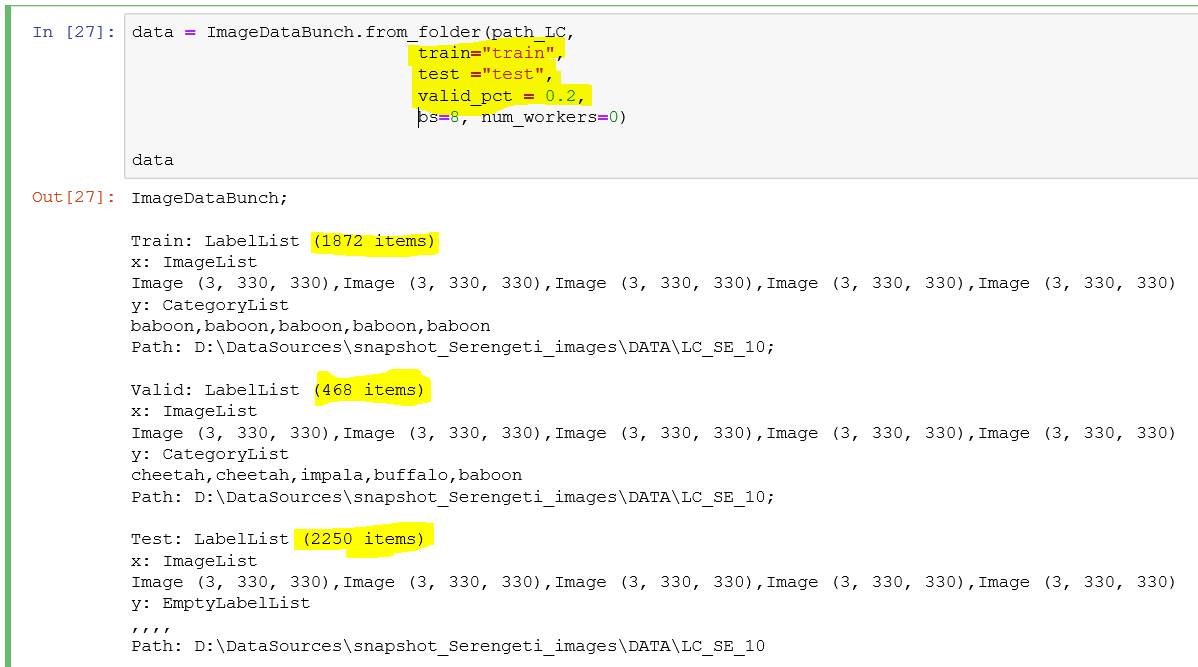
here in fastai if we indicated testing set separately still valid_pct is being taken from both:
So to be clear my question would be how we can have valid_pct partitioned only from training test and not testing set, so we can have an unbiased conclusion on results of prediction on testing set?
ImageList.from_folder looks recursively into all the subfolders for the images it can find, but you can then use filter_by_folder to include/exclude some folders you only want/don’t want
Thank you for your suggestion.
but now after I looked deeper in the API it seems that validation set is not being used at training process (I mean as the internal fine-tuning data as it is common in many packages).
for example if I define my databunch as :
data = ImageDataBunch.from_folder(path, ds_tfms=(tfms, tfms), train=“train”, valid=‘test’, bs=8)
Validation set will be used only at the time of prediction for example in : learn.get_preds(ds_type=DatasetType.Valid)
or : earn.TTA()
if this correct, i guess there is no concern to have valid=‘test’, right?
Normally you shouldn’t use your test set until the very end. The validation set isn’t used for training, but it’s used to fine-tune hyper-parameters since you adjust them to get a better validation loss/metric at the end of training.
thanks!
and how do you define labels of test set to be from the folder names?
this seems to not be correct
add_test_folder(f’{path}’ +’/test/’, label_from_folder()).
Thanks for clarification and sorry for tiring you.
But confusion comes in when there are methods such as .tta() or .get_preds() where you need labels for evaluations. perhaps a clarification in the docs where those methods are explained would solve the issue. perhaps there is an explanation now but when i checked it the last time there wasn’t any.
it will use the valid_pct partition of training data and not the new validation set that is being defined as .split_by_folder(train=‘train’, valid=‘test’)
However i figured out what is the issue. I found that unless you define your dataset as : ds_type=DatasetType.Valid it won’t use the new validation set.
If you please let me know why is this? or point me to where there is an explanation for it i would appreciate as it helps me and others to have a better understanding of what is the difference between DatasetType.Valid and data_test.valid_dl
That line can’t work with current fastai. ds_type must be of DatasetType. I’ll stop replying until you provide your whole code, as it’s pointless for me to try to guess what’s happening. Not trying to be mean, but I (or any other person in this forum) really can’t help without seeing everything. Failure might be linked to some line of codes before what you are showing.
Also the whole error message (if applicable) and your current setup (given by show_install) are necessary information to figure out what’s going on.
Thanks, and I think the answer is [quote=“sgugger, post:23, topic:28292”]
That line can’t work with current fastai. ds_type must be of DatasetType .
[/quote]
simply during the version update many thing has changed while the docs are still not fully updated and somewhat frustrating for everyone who is using it.
I understand that i have to share my code but in this case every thing was according to the aforementioned docs which i have shared the link and thought is needless to copy and paste everything again here. but here we go as you requested:
The docs are updated with each new version. If there are places when they’re not fully updated, any PR to fix them will always be more than welcome. TTA isn’t documented in any case, which is another thing where a contribution would be appreciated. In general you’ll find people will be more prompt to help you if you use language like “it’s not perfect, how can help make it better?” rather than just complaining.
Same for the changes. I’m not sure what are the many things that changed since the functions you use haven’t moved in the past three months.
thanks for your clarification. I will try to contribute to TTA documentation.
this is what i wrote two comments above:
and i just asked the question for what is the difference between two data type.
well, there have been changes that each of them took a bit of time until we figured out how to fix them from v0.7 to v1.0. it was unfortunate that we tried to use this library at the time many changes had to happen. Needless to mention all of them here. it was just bad timing i guess
Ah yes sorry, ds_type=DatasetType.Valid is what you want when you have set your new data, because it’s the validation set of data_test. I confused myself
Oh I didn’t realize you were talking of v0.7. It has been stated very clearly that v1.0 was a complete rewrite, so there is absolutely no backward compatibility. Also there was no docs for v0.7, so it’s not a question of having them be updated, more like writing them
There are many methods, actually : ) Please have a look at the data_block docs and the DataBunch docs, for a start. You should also be able to Google many useful blogposts about “fastai data block” API. Worth noticing the strive for consistency (kudos to the devs) between the creation methods for different data types, e.g. image, tabular, text, etc., such that very similar lines of code in fastai can be used for different DL models / applications. Thanks.