Hi there !
I recently have been experimenting with optimizers and initilization schemes and have found some weird behaviours about the default behaviour of a CNN in Pytorch and I would like to know if one of you could help me understand what is happening.
I trained from scratch a really standard VGG16 model (no BN, no Dropout) on CIFAR10. Here is what I tried:
Train with standard Initialization:
This is the weird case I don’t understand, the network simply doesn’t learn at all. Here is the result of the learning rate finder:

If I check how the gradients are behaving in this case, they are equal to 0 at each layer.
[stats(layer.weight.grad.data) for layer in learn.model.features if isinstance(layer, nn.Conv2d)]
[(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0')),
(tensor(0., device='cuda:0'), tensor(0., device='cuda:0'))]
The network has been trained with Adam but other optimizers (RMSProp, AdamW, …) were tested and the same results happened.
By playing with the lr value, the best thing I could get is a diverging behaviour. So either the model doesn’t learn, either it diverges, there is no in between.
Modify the weights initialization
If now I change the initialization of the Conv layers to kaiming uniform but with a a=0 instead of default sqrt(5), now the networks has gradients and is able to learn something (not the best graph ever, but at least something is happening)
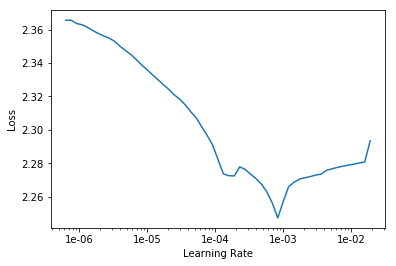
[(tensor(-4.2682e-05, device='cuda:0'), tensor(0.0002, device='cuda:0')),
(tensor(-2.8559e-05, device='cuda:0'), tensor(0.0002, device='cuda:0')),
(tensor(-1.2180e-05, device='cuda:0'), tensor(0.0001, device='cuda:0')),
(tensor(-9.3121e-06, device='cuda:0'), tensor(9.7041e-05, device='cuda:0')),
(tensor(-6.7986e-06, device='cuda:0'), tensor(6.6543e-05, device='cuda:0')),
(tensor(-4.9050e-06, device='cuda:0'), tensor(5.7243e-05, device='cuda:0')),
(tensor(-6.0228e-06, device='cuda:0'), tensor(5.2872e-05, device='cuda:0')),
(tensor(-3.1334e-06, device='cuda:0'), tensor(3.5574e-05, device='cuda:0')),
(tensor(-2.8126e-06, device='cuda:0'), tensor(3.3924e-05, device='cuda:0')),
(tensor(-1.7947e-06, device='cuda:0'), tensor(3.4823e-05, device='cuda:0')),
(tensor(-1.9354e-06, device='cuda:0'), tensor(3.9055e-05, device='cuda:0')),
(tensor(-1.7674e-06, device='cuda:0'), tensor(4.4218e-05, device='cuda:0')),
(tensor(-4.0000e-07, device='cuda:0'), tensor(4.8910e-05, device='cuda:0'))]
What could be the reason of such behaviour ? The default initialization scheme itself ? How can it even be possible for a network to have gradients equal to 0 ?
Even in case of vanishing gradients, shouldn’t some layers upgrade, at least a little bit ?
The code of those experiments is available here