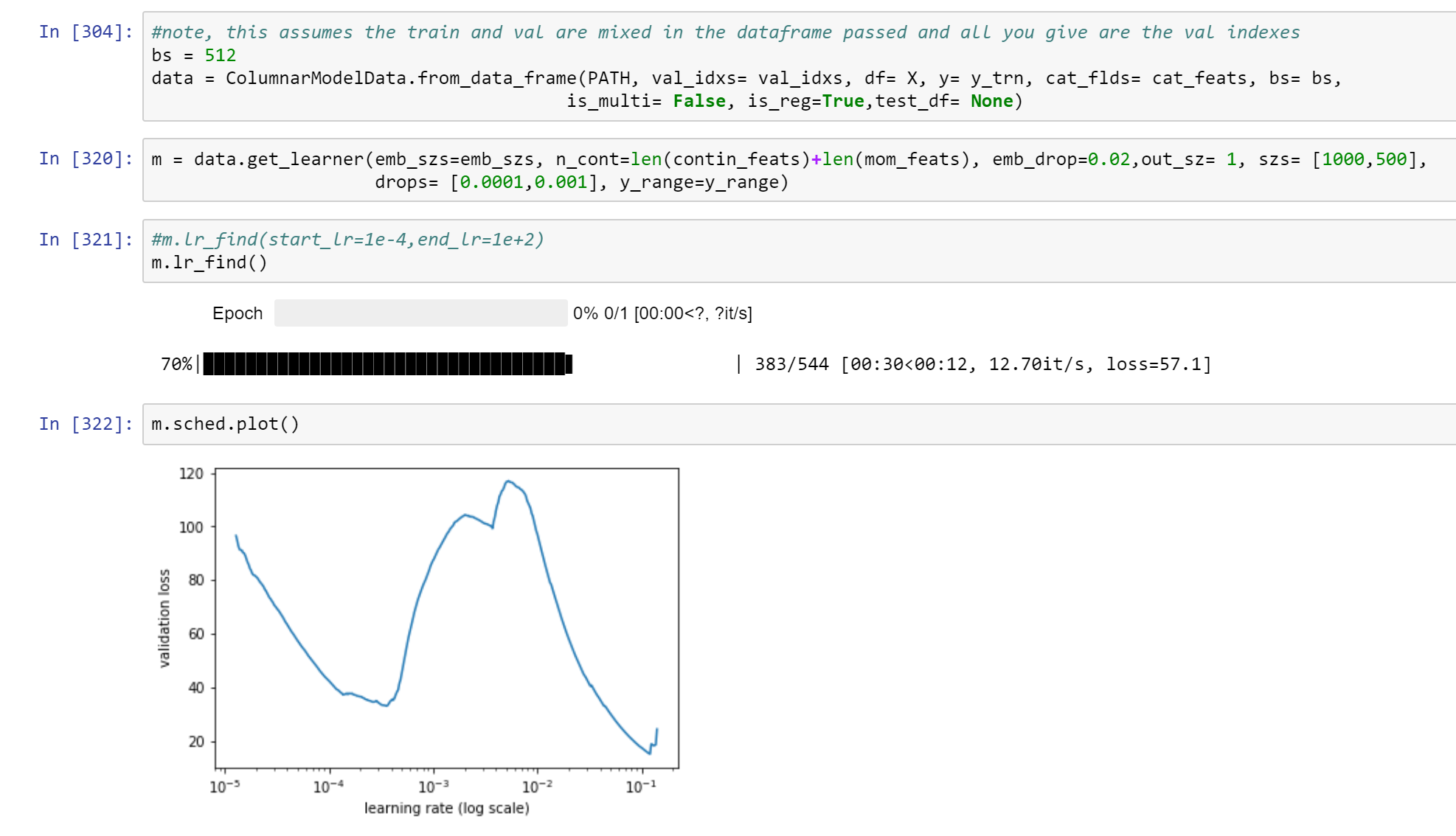
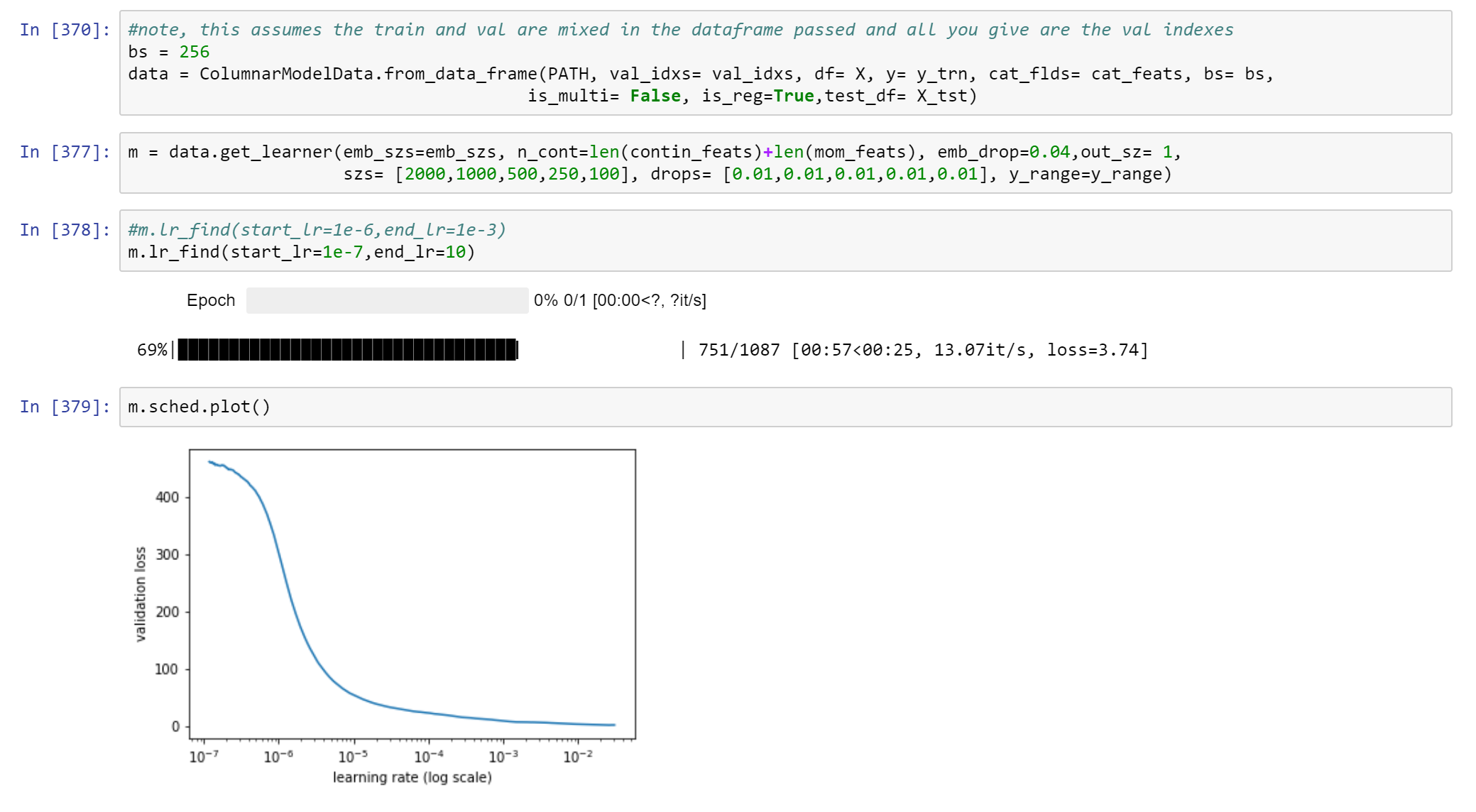
any ideas what could be causing such a crazy hump in my learning rate schedule? I have tried adjusting batch size, adjusting dropout, adjusting the number of hidden layers but it’s still there, I can only partially smooth it out.
This is using structured time series data that I’ve shuffled to provide better diversity per mini-batch
so i thought about this and in my case I feel like it shouldn’t matter but I’m open to being corrected on this. I have already split off the information in the date using add_date_part() so the information is still there in the dataset. I’m using all of those date features as categorical embeddings so i would hope that would preserve the time series information. The other thing is that my dataset looks a lot like the rossman dataset with the same date repeating for many different stores. rather than one single time series spanning the entire dataset without repeating.
I have tried without it and it works, but definitely appears to learn better after shuffling.
So I just managed to smooth out the hump by changing the architecture and the dropout (a lot). Honestly not sure why this works but it is the result of a lot of experimentation and inching in the direction of improvement(in the hump).
I’d be curious for feed back about why it works:
I went from:
2 layers: [1000,500]
dense_layer_drop: [0.0001, 0.001]
emb_drop: 0.02
BS = 512
I’ve also noticed that bs has a great impact on the learning finder plot and results. It’s curious that you say this did not have any impact in your case. Thanks for sharing the findings, I haven’t tried making a deeper model yet mostly due to simple datasets. I will give it a shot.