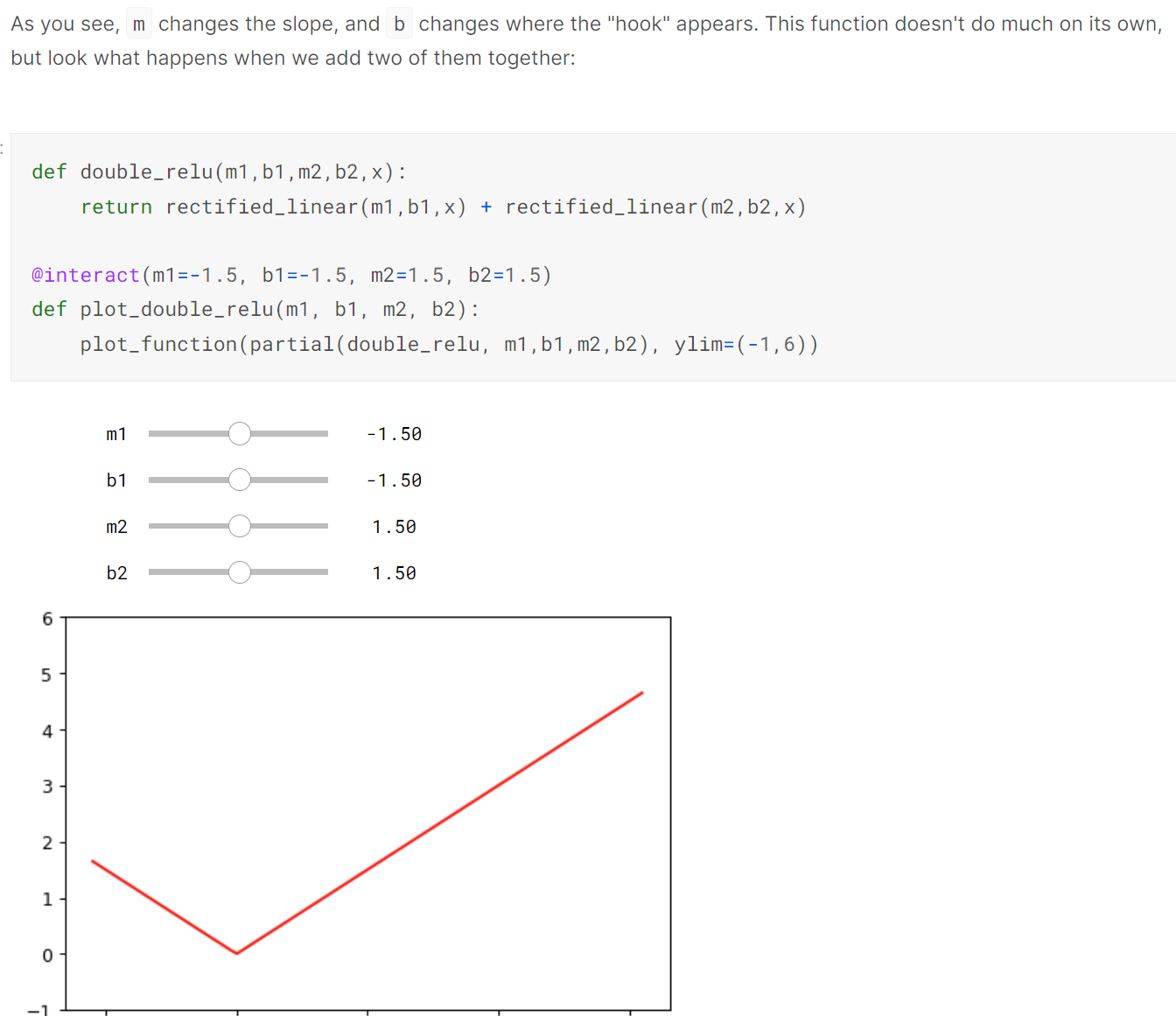
For non-classification tasks, error rate can be slightly more nuanced than just 1-Accuracy. For a good explanation, see:
and
and
For non-classification tasks, error rate can be slightly more nuanced than just 1-Accuracy. For a good explanation, see:
and
and
One book that I found helpful was Andrew Glassner’s “Deep Learning, A visual Approach”. It is not math heavy at all and a beautifully illustrated book. The title picture is rather drab which is unfortunate, because the book is really geared towards beginners and tries to explain a lot of concepts visually.
Andrew Glassner gave a lecture for non practitioners as well which some might find helpful in grokking the basic concepts of SGD and neural networks without all the intimidating math parts.
Book:
“Deep Learning: A Crash Course” SIGGRAPH video:
 | SIGGRAPH Courses")
Free Chapter on Probability :
Wow it looks amazing
Just looked at the PDF and this looks great. I love visual illustrations, when done right it can be very ‘obvious’ and help in explaining complex concepts. I might get a paper copy of this book just for the sake of illustrations. Thanks for sharing !
Yeah, it’s unfortunate the book’s cover is not attractive at all! I almost skipped over it while browsing through books at the library, but when I looked at the illustrations, I checked it out. I’m thinking of getting a copy too because I had to return it and now I’m in the hold queue again ![]()
It is printed on thick paper so the book is quite hefty, but YMMV.
Hi everyone,
Jeremy graciously showed how an SGD version via Excel, which helped clear out a few things. Seeing the whole process of multiplying and summing was beneficial. I still have a few questions:
Thank you all.
Regarding questions 1 and 2: I was also a bit confused by that part at first. You are right that the input (1424,10) is multiplied by the weight matrix (10,2) which gives the output of shape (1424,2). ReLU is then applied to each of the output columns which gives again an output of shape (1424,2) where all negative values were replaced with zeros. This is so far pretty standard. Now Jeremy adds up the two output columns to get a single prediction per row (which is then compared to the actual target to compute the loss and perform weight updates etc.). What you “normally” would do is to process the two output units of the first layer as inputs to another layer which gives your final prediction, but I guess simply adding up the output columns was meant as a simplification and seems to be working as well ![]()
That’s right. But we can do lots of rows of data at a time, and lots of groups of coefficients at a time.
Super clear now, I had forgotten about this. Thank you!
Hi all,
I’m fairly new to neural nets and deep learning in general and I’m really enjoying / keeping up with the course so far. However, I keep coming across words such as CNN,RNN,GANs etc and can’t quite get a good hold on those topics theoretically. I could quite easily follow the ReLU explanation used in neural nets, in lesson 3 and was hoping to find some clarity on those topics in similar terms. Any good resources to look at?
Also, what category of neural net would the very basic excel implementation of the model also done in lesson 3 come under?
Cheers!
IMO the best resource is the fast.ai course that you’re doing we, which introduce these things once you’ve got the foundations you need to understand them, and when you need to know them!
If you want to skip ahead, the 2020 recordings have you covered, or you could read ahead in the fastai book.
This week’s recommended reading covers RNNs BTW.
That’s awesome, Jeremy. Looking forward to it! Thanks!
Your question prompted me to look for some of these terms and I found this glossary by Google. Seems to be pretty good, I’ve bookmarked it. :
Ok, so I feel like the answer to this should be obvious, but I don’t get it. Doing SGD, we have the derivative/slope of the loss with respect to a parameter. So that should mean that the value of that slope is equal to the change in the loss (y-value) divided by the change in the parameter (x-value). So far so good. But why do we update the parameter (x-value) proportionally to the change in the loss (y-value)? I get that you need to go in the opposite value of the gradient, since we’re trying to minimize the loss. But why a large gradient indicates that we should move further along the x-axis than we should with a smaller gradient puzzles me. If anything, it would seem that a shallower gradient would require a bigger change to the parameter to achieve the needed change in the loss. But instead, we amplify the effect of a large gradient, and conversely minimize an already small gradient. I guess I just don’t understand why the magnitude of the gradient should have any bearing on how much we change the associated parameter.
I had the very same question. To me, if there is a very steep slope downward, it may go back up very fast again. Consequently, we shouldn’t move too far when the slope is very steep.
I implemented a very naive custom optimizer for this a while ago and I didn’t get it to work reasonably well. In fact, it was incredibly tedious, because if the slope is zero, or close to zero, I had to use some hacks (I am convinced this can be done a lot better than what I did a few years ago, when I didn’t have lots of experience). Just tried to find the code to understand better what I did, but I wasn’t successful.
I still don’t understand it either. Interesting questions to me are:
Does SGD shape the loss landscape to be stable with SGD? Are there other ways to get a stable loss landscape as well?
I thought some more about it (couldn’t find anything online unfortunately). What could easily explain it, is if the loss landscape is somewhat smooth, without abrupt slope changes. In that case when the slope is very steep, we can expect it to roughly continue like that, so a larger step is justified. On the other hand if the slope is very flat, it may at any point “switch” from going up to going down.