What I’m trying to do is to create a CNN to distinguish between audio clips from Pearl Jam and The National. The first thing I did was download 23 songs by Pearl Jam and 24 by The National, extract a 10 second clip (starting at 00:30) from each one and generating a spectrogram for each clip (standing on the shoulders of giants here). Then I placed 16 images in the training dataset for each band and the rest in the validation dataset. Now, some things I didn’t expect or don’t understand.
Repeatedly yields different results despite having the same seed.
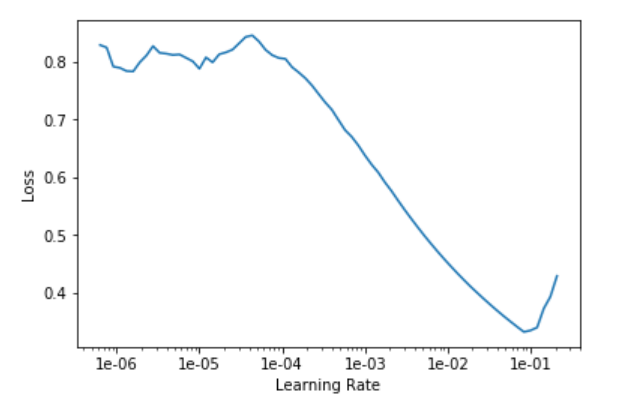
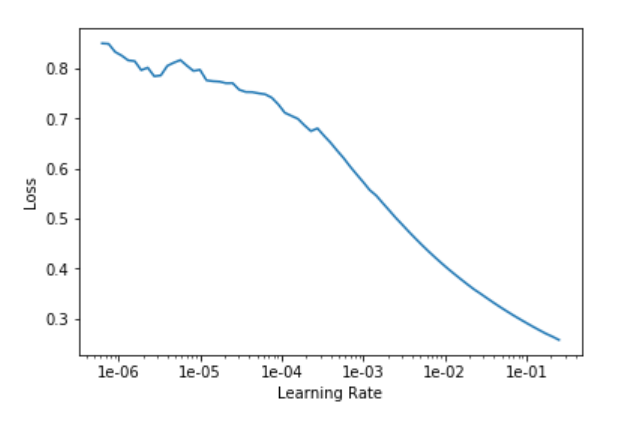
Second, running
lr=1e-2
learn.fit_one_cycle(8, slice(lr))
Also yields different results when run repeatedly. I assume this is because I’m not starting off the model from scratch, but then is there any way to get rid of all the learning and start over without recreating the learn object?
there’s some pytorch random seed goodies under the hood as well as numpy. try adding the following where you’re setting the seed… and don’t forget to recreate your databunch when you recreate the model. there’s seed dependencies in there too. good luck mate.
Thanks! That seems to work. Although I find it strange that it wasn’t mentioned in the lecture. If I don’t use your code the result are not repeatable.
The other issue I’m having now is that I can’t figure out why I should choose a specific value for the first parameter in learn.fit_one_cycle(5, slice(1e-2)). Why 4 or 5 or some other value? Also, the error rate in the last epoch for that is 0.25. Subsequently running
A specific number of epochs is not that important when you are using fit_one_cycle because of the shape of learning rate function (look here)
It’s decreasing in later epochs, so few more epochs will not have a big impact and should not cause overfitting.
Ofc if you choose a very high number (eg. 100), the network will convergence very slow.
And for a too low number, the network will not be able to learn. Something between 5-20 should be ok.
If you think about it more, the right num of epochs depends on the size of the network, batch size, regularization, learning rate and other hyper-params. I didn’t saw a specific prescription
There are two handy callbacks in fastai EarlyStopping and ReduceLROnPlateau to increase safely number of epochs. But I think they work better with fit function (with constant lr).
I do something like this:
fit_one_cycle freezed
fit_one_cycle unfreezed
fit with previous epoch lr (taken from learn.opt.lr), with 2 times more epochs, and both callbacks
First step has a huge impact on loss.
The third step decreases loss only slightly
I think that perhaps you need more data, IMO your model is overfitting to the few training instances you have quite quickly, that’s why you went from a 18% error rate all the way down to a 50% error rate which is basically just flipping a coin to choose between the two artists.