no not yet, I am not suspecting it may be due to the bidirectional=True, is there any special thing i should be aware when using it? It seems push the loss really low and yet generating worse sequence. I am testing on lesson 6 notebook.
For bidir LMs I’ve just been training two separate models and averaging their predictions.
1 Like
I was talking about lesson6 notebook. I add bidirectional=True and the loss jump from 1.6 to 0.4.
So for testing my hypothesis, I try to replicate the scenario with lesson 6 rnn notebook. I was able to reproduce similar result, where loss drop significantly yet generating garbage sequence. Is there anything I do it wrongly?
I then try to remove the Bidir, then my accuracy drop form 0.9 --> 0.6, yet it generates sentence that make more sense.
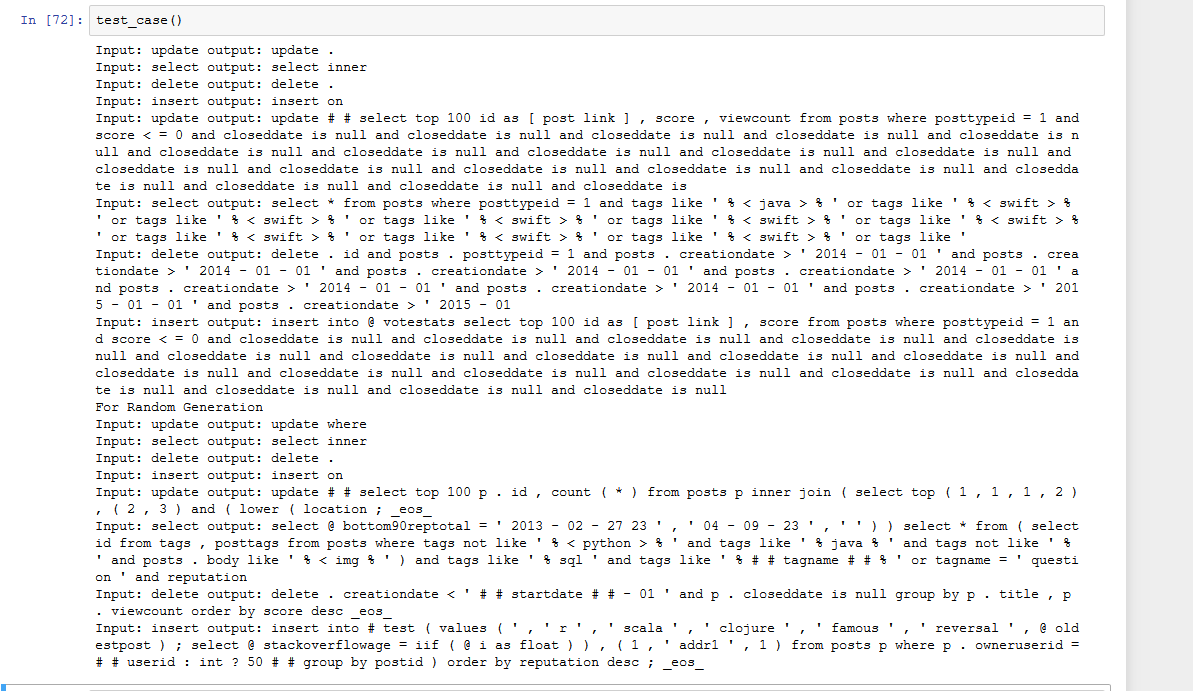
Looking for some help, thanks!
Edit: I actually flip the model in previous comments…now it’s correct.
Here are some result when I plug in your pre-processing to my model.
Without Bidirectional

With Bidirectional
Again, insane high accrucy with garbage output.
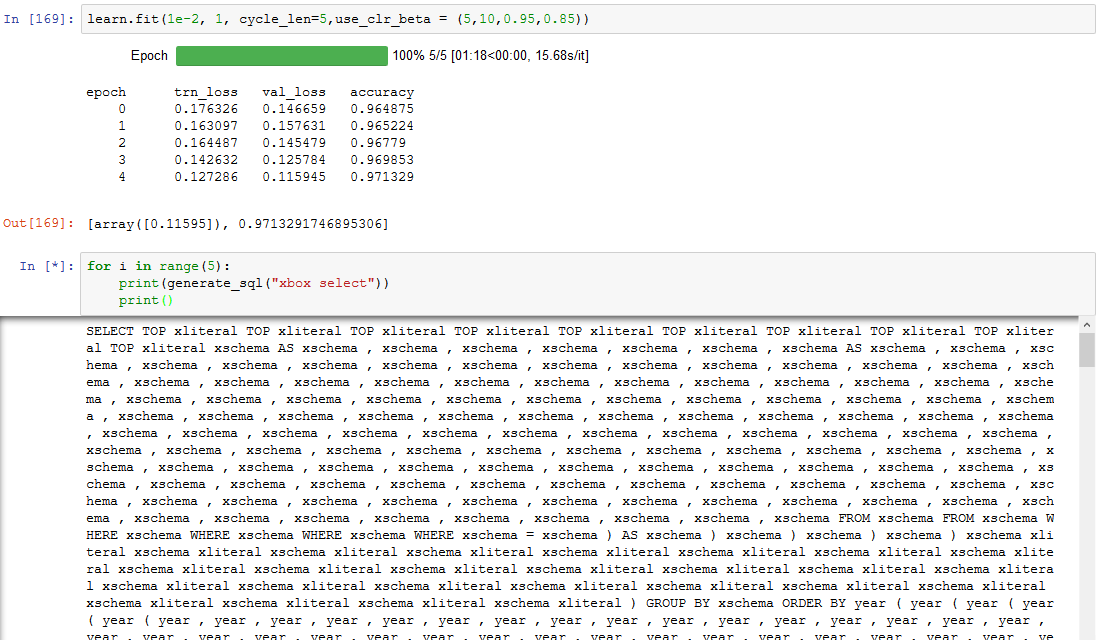
2 Likes
That’s some really interesting findings!
Yes, I still have no idea why bidirectional model generate garbage sequence, looking for someone can give some insight about this…
I am putting all these into a blog post summary, do you mind if I included your pre-processing part in my notebook. As that helps my debugging and confirm the problem was not come from pre-processing bug. Please let me know if you have a medium account/ blog post that you may have already written, so I can tag you inside my blog.
It looks much better now even the accuracy is lower. I take the 5/10 most possible output at each step and sample them with softmax .

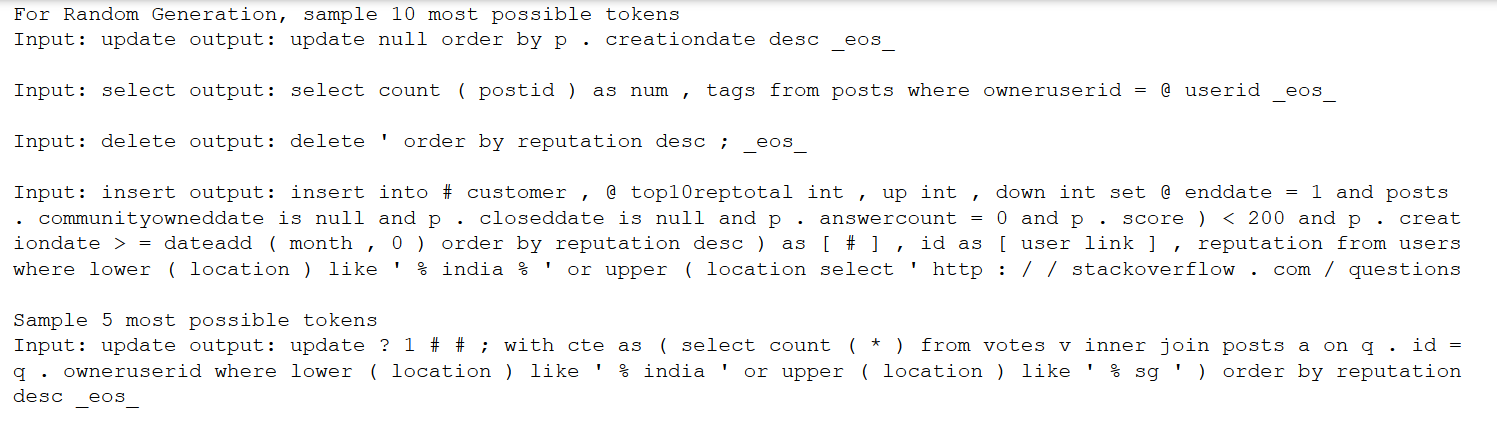
I will pause for now and catch up with GANs, maenwhile, hoping someone can answer my question. 
2 Likes
I actually reverse the caption in previous comments…In short, Single Direction works, but Bi-dir act weirdly.
I don’t see how a bidir LM could be used for generation. By definition, there are no future timesteps for it to learn from…
1 Like
Thanks for the reply, I kind of thought about this too, but then, isn’t the task always predicting the t+1 word while we have t input words? In training it is doing very well.
I guess I cannot see what’s the fundamental difference between “generation” and prediction during training. I try to seed it with a longer input ( same as the input length for training), but the result is still bad. I don’t understand what’s the different here.
Is the bidir in the encoder or decoder?
For encoder it makes sense - a JOIN will have a WHERE coming down the line…etc.
Hey, is anyone still interested in this topic? I’m looking into this potentially for future research or a personal project.
Any github projects looking for help?
1 Like
Hi All,
Any progess on text to sql? Can someone help me in getting started?
HI…
I hope this may help you -
SQL Server process
The SQL Server process uses the following components for full-text search:
- User tables. These tables contain the data to be full-text indexed.
- Full-text gatherer. The full-text gatherer works with the full-text crawl threads. It is responsible for scheduling and driving the population of full-text indexes, and also for monitoring full-text catalogs.
- Thesaurus files. These files contain synonyms of search terms. For more information,
- Stoplist objects. Stoplist objects contain a list of common words that are not useful for the search. For more information, see [Configure and Manage Stopwords and Stoplists for Full-Text Search]
- Learn SQL Server query processor. The query processor compiles and executes SQL queries. If a SQL query includes a full-text search query, the query is sent to the Full-Text Engine, both during compilation and during execution. The query result is matched against the full-text index.
- Full-Text Engine. The Full-Text Engine in SQL Server is fully integrated with the query processor. The Full-Text Engine compiles and executes full-text queries. As part of query execution, the Full-Text Engine might receive input from the thesaurus and stoplist.
- Index writer (indexer). The index writer builds the structure that is used to store the indexed tokens.
- Filter daemon manager. The filter daemon manager is responsible for monitoring the status of the Full-Text Engine filter daemon host.
Regards,
Srija
There are many tools that do this, and the vast majority of them use GPT-4. In my experience, training a model from scratch to do this isn’t worth it as it simply wont be usable IRL. Benchmarks on test datasets are not representative of real world situations.
IMO tools like BlazeSQL are your best bet