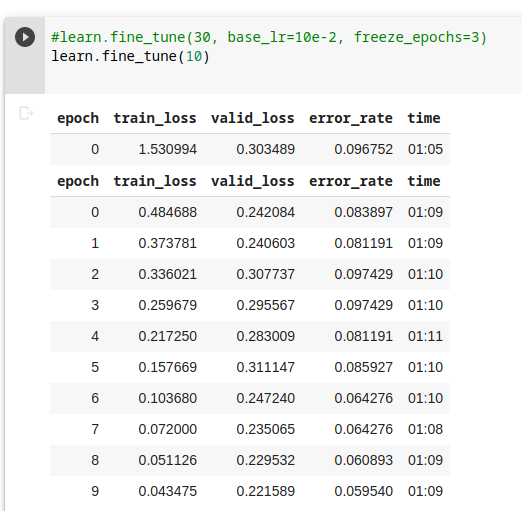
I have a question about Training Loss, Validation Loss and Error Rate from my training. I am new to Deep Learning and just want to make sure I am understanding this correctly.
Epoch #9 looks to have the lowest error rate, however, the validation loss is much higher than the training loss. Does it mean the model is overfitting?
Yes. It seems your model is overfitting to training data(a high variance problem).
Complicated answer:
In other words, your model is focusing on the quirks in your data instead of learning the underlying process that generated the data.
As stated in fastbook, loss is for the model to consume and metric is for us humans. As long as the metric is decreasing over training period, it means that the model is learning from the data and you don’t have to worry.
If the error rate is accaptable to you, you can focus on tuning the hyperparmeters for model performance.
If the error rate is not accaptable to you, then you need to worry about overfitting/underfitting problem to get to the result that is acceptable to you.
Few things you can try addressing overfitting:
Add regularization
Feature selection to decrease number/type of input features
Add more training data
PS: Note that i’m also a student and this is my understanding from finishig the course. Please correct me if i’m wrong.