The new modules are pretty much done in the fastai_v1 repo (for the stuff that will be in fastai 1.0, we have some ideas of new features but they will have to wait for a little bit  ) and here is a general introduction of how it’s built. Now we’ll focus on documentation and as we make progress you’ll get more details on each module in the doc folder of the repo.
) and here is a general introduction of how it’s built. Now we’ll focus on documentation and as we make progress you’ll get more details on each module in the doc folder of the repo.
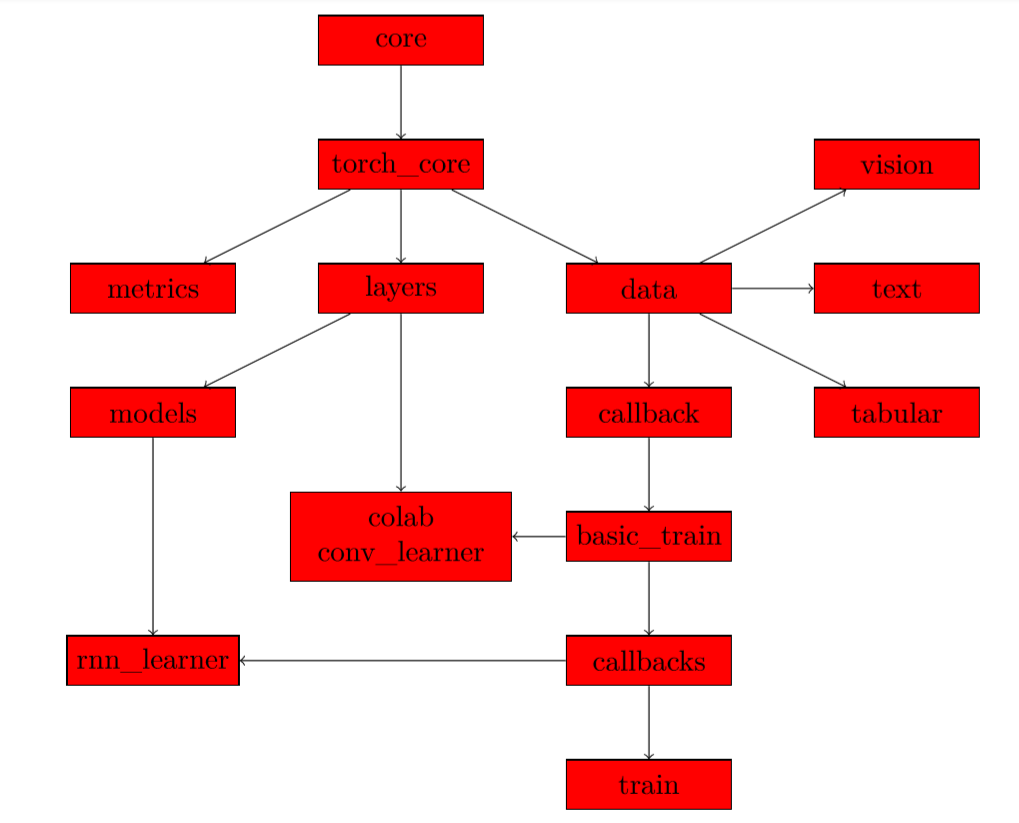
At the base of everything are the two modules core and torch_core. They define the basic functions we use in the library, we just split the ones that use general modules from the ones that use pytorch. We also put there all the shortcuts for type-hinting we defined (at least the one that don’t depend on fastai classes defined later). Each other module usually imports torch_core.
Then, there are three modules directly on top of torch_core:
- data, which contains the class that will take datasets or pytorch dataloaders to wrap them in a DeviceDataLoader (a class that sits on top of a dataloader and is in charge of putting the data on the right device as well as applying transforms such as normalization) and regroup then in a DataBunch.
- layers, which contains basic functions to define custom layers or groups of layers
- metrics, which contains all the metrics
From layers, we have all the modules in the models folder that are defined. Then from data we can split on one of the three main types of data: vision, text or tabular. Each of those submodules is built in the same way with:
- a module named transform that handles the transformations of our data (data augmentation for computer vision, numericalizing and tokenizing for text and preprocessing for tabular)
- a module named data that contains the class that will create datasets and the helper functions to create DataBunch objects.
This takes care of building your model and handling the data. We regroup those in a Learner object to take care of training. More specifically:
- data leads to the module callback where we define the basis of a callback and the CallbackHandler. Those are functions that will be called every step of the way of the training loop and can allow us to customize what is happening there;
- callback leads to basic_train where we define the Learner object, the Recoder (which is a callback that records stats and takes care of updating the progress bars) and have the training loop;
- basic_train leads to the callbacks, which are defined as modules in the callbacks folder;
- those callbacks are in turn imported in learn, where we define helper functions to invoke them.
Along the way, the module tta (for Test Time Augmentation) depends on basic_train, the module colab (for colaborative filtering) depends on basic_train and layers, so does the module conv_learner (for our models with a skeleton trained on imagenet and a custom head for classification) and the module rnn_learn (to automatically get learner objects for NLP) depends on callbacks (specifically the rnn callback) and models (specifically the rnn models).
Here is a graph of those relationships