I get a really low oob score of 0.4716 and an rmse of 0.027 on the red wine quality dataset. Why is my oob_score so low? Does it mean that I am overfitting?
I have trouble knowing how to handle small sets of data. This one has 1599 records only. As soon as I create a validation set of size 30, my r^2 drops from 0.90 to 0.11! So I don’t use a validation set, instead I use oob_score_. Now r^2 is 0.90 but the oob_score_ is 0.47.
This is my model without a validation set:
m = RandomForestRegressor(n_estimators=80, max_features=0.5, n_jobs=-1, oob_score=True)
m.fit(df_trn, y)
print_score(m)
Convert the training and test data in the same way if you don’t want the error to appear. So whenever you’re encoding the categorical variables apply the same method on both training and test data.
in ML course (2017)
lesson 3 - in rf_interpretation
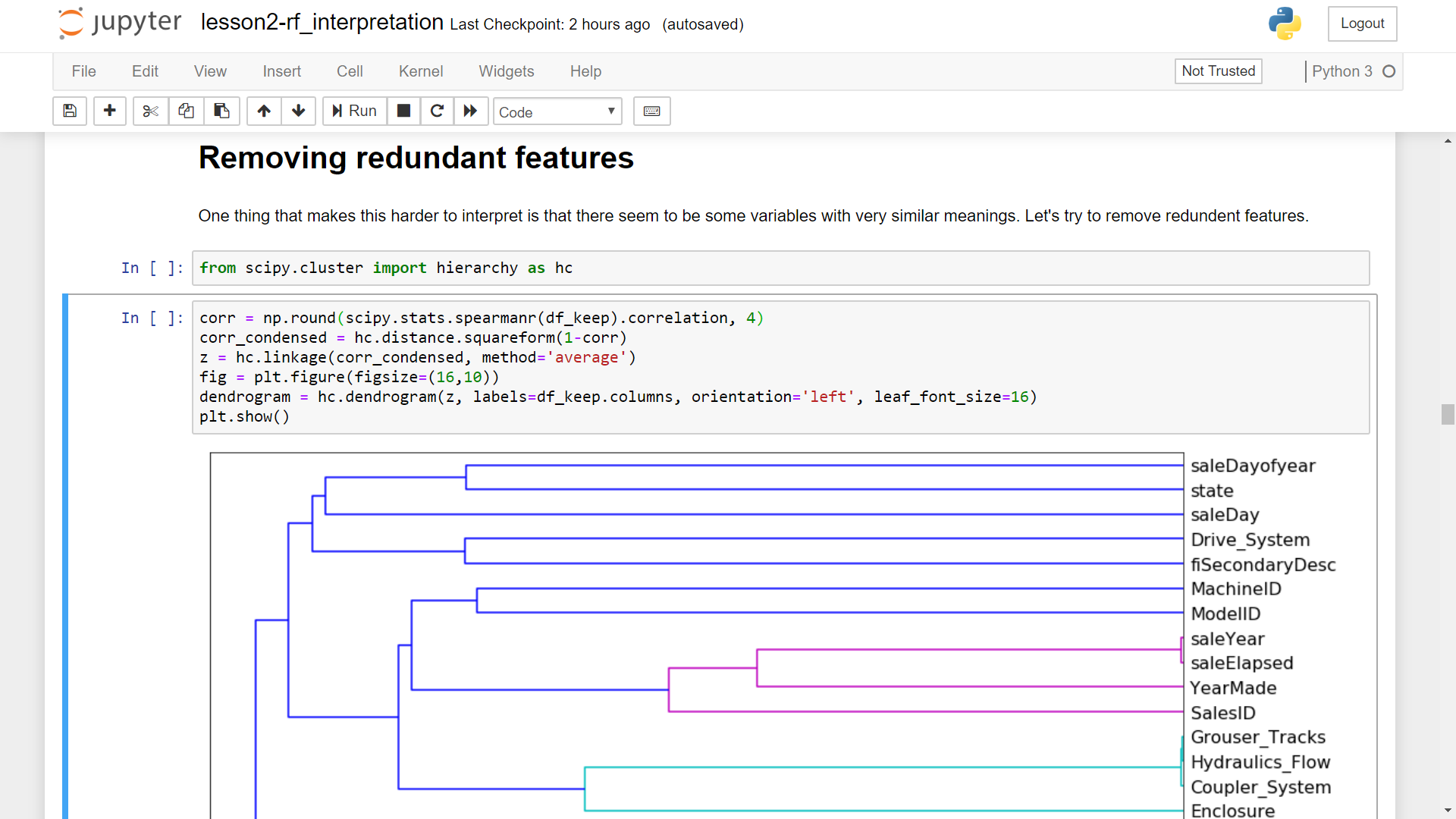
i tried plotting hierarchical clustering without feature importance (finding the most effective independent features)
i mean instead of just keeping the 30 important columns (first image)
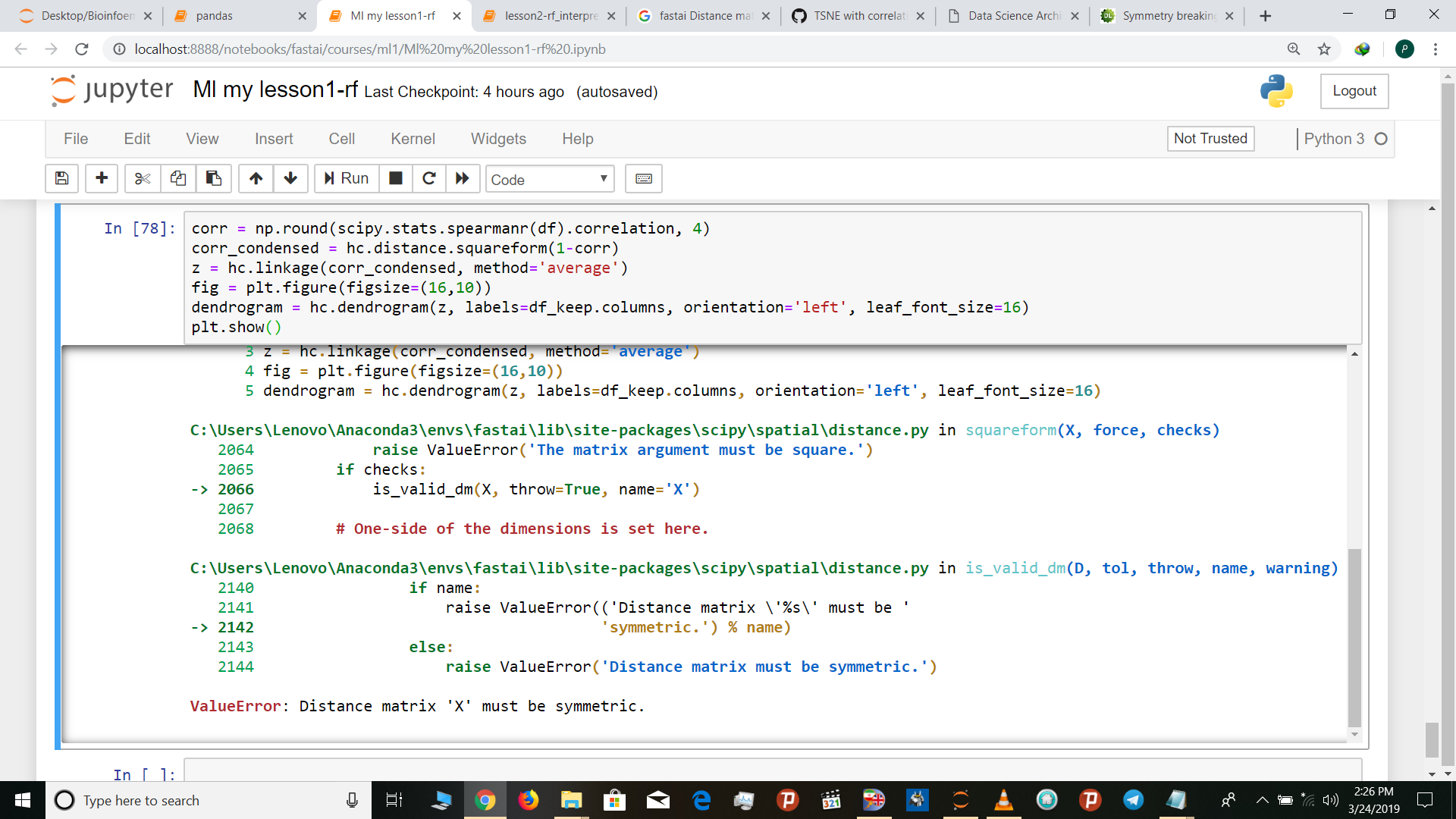
i used all columns (second image)
then i got this error “Distance matrix ‘X’ must be symmetric”
why is that ?
maybe some column has problem or number of columns are too much
What is the minimum required system specifications for running advanced machine learning algorithms and how can one integrate a command line tool.
Like say i want a dataset to differentiate between hotels and non hotel images for an hotel website like https://timbu.com/
2- I am trying to do both, Machine learning for coders (end of 2018 course) and Deep Learning for coders (released 2019), everything for the new version of DL course seems to be clear, and thus i already installed GCP to work through the lessons. I have been looking for resources around to make GCP work with the Machine Learning course and haven’t seen any. My guess is just add the Jupyter NB files to the same instance of Fast.ai v3 DL course. I do not have to create another instance right?
3- The most updated Jupyter NB material for ML 2018 course for coders, that i would get from Github, would be this right? However, i only see 5 lesson notebooks on Github; On the main page, i see 12 video lessons…
all this may seem very straight forward to you, but i am very new to do this. Any help would be appreciated!
Hi Jeremy, after signing up on crestle,I am only able to find a server for fastai v3, which does not have the contents for Introduction to ML (Random Forest). Are the contents still available, if so, under which server, also, crestle has changed quite a bit since you made that video.
Anyway, much thanks for your lessons!