@mgloria I may be a moment as I won’t get to look at things until tonight. Can you do a .path on it? (Curious) or .name? You can see the attributes by doing dir() on a variable
Sure! No dbunch.name, dbunch.path returns Path(’.’) and available methods as follow:
['__class__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattr__',
'__getattribute__',
'__getitem__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__lt__',
'__module__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__setstate__',
'__sizeof__',
'__str__',
'__subclasshook__',
'__weakref__',
'_default',
'_device',
'_dir',
'_docs',
'_xtra',
'add',
'add_na',
'after_batch',
'after_batch',
'after_item',
'after_item',
'after_iter',
'append',
'argwhere',
'as_item',
'as_item_force',
'attrgot',
'before_batch',
'before_batch',
'before_iter',
'bs',
'c',
'cat',
'categorize',
'chunkify',
'clear',
'concat',
'copy',
'count',
'cpu',
'create_batch',
'create_batches',
'create_item',
'cuda',
'cycle',
'dataloaders',
'dataloaders',
'dataset',
'decode',
'decode',
'decode',
'decode_batch',
'decodes',
'default',
'device',
'device',
'do_batch',
'do_item',
'drop_last',
'encodes',
'enumerate',
'fake_l',
'filter',
'from_dblock',
'fs',
'get_idxs',
'index',
'indexed',
'infer',
'infer_idx',
'init_enc',
'input_types',
'itemgot',
'items',
'items',
'loaders',
'loss_func',
'map',
'map_dict',
'map_zip',
'map_zipwith',
'n',
'n_inp',
'n_inp',
'n_subsets',
'n_subsets',
'new',
'new_empty',
'new_empty',
'nw',
'o',
'offs',
'one_batch',
'order',
'overlapping_splits',
'overlapping_splits',
'path',
'pin_memory',
'pop',
'prebatched',
'product',
'randomize',
'range',
'reduce',
'remove',
'retain',
'reverse',
'rng',
'sample',
'set_as_item',
'set_split_idx',
'setup',
'setups',
'show',
'show',
'show_batch',
'show_results',
'shuffle',
'shuffle',
'shuffle_fn',
'sort',
'sorted',
'split',
'split_idx',
'split_idx',
'splits',
'splits',
'stack',
'starmap',
'subset',
'subset',
'sum',
'tensored',
'test_dl',
'tfms',
'timeout',
'tls',
'train',
'train',
'train',
'train_ds',
'train_setup',
'transform',
'types',
'unique',
'use_as_item',
'val2idx',
'valid',
'valid',
'valid',
'valid_ds',
'vocab',
'weighted_databunch',
'wif',
'zip',
'zipwith']
1 Like
i’m not sure, but .items may work. let me check too
dls.train_ds.items[0]
2 Likes
thanks a lot @barnacl with your code I managed to get the path train_imgs = dbunch.items['filename'].apply(lambda x: Path(path/'train'/x)) a bit edited because the input is a dataframe. Do you know of a way to use a table as input with Datasets api? I tried looking at multi-label example but it uses datablock api unfortunately. e.g. for me ParentLabel is not an option
My main challenge is how to get the images path and labels from the csv to datasets api to have more flexibility.
1 Like
@mgloria here is that done on a Datasets level:
def get_x(x): return f'{planet_source}/train/{x.image_name}.jpg'
def get_y(x): return df[df['image_name'] == x.image_name]
dset = Datasets(df, [[get_x, PILImage.create], [get_y, MultiCategorize()]])
dls = dset.dataloaders(after_item=[ToTensor(), Resize(224)])
Let me know what parts of this is confusing for you 
As you can see, we can just pass in the DataFrame itself into the API and specify how we want to get our x’s and y’s out of it
2 Likes
thanks a lot @muellerzr ! A bit more clear now. I adapted your code for my dataset but I am still getting an error which I am not able to interpret:
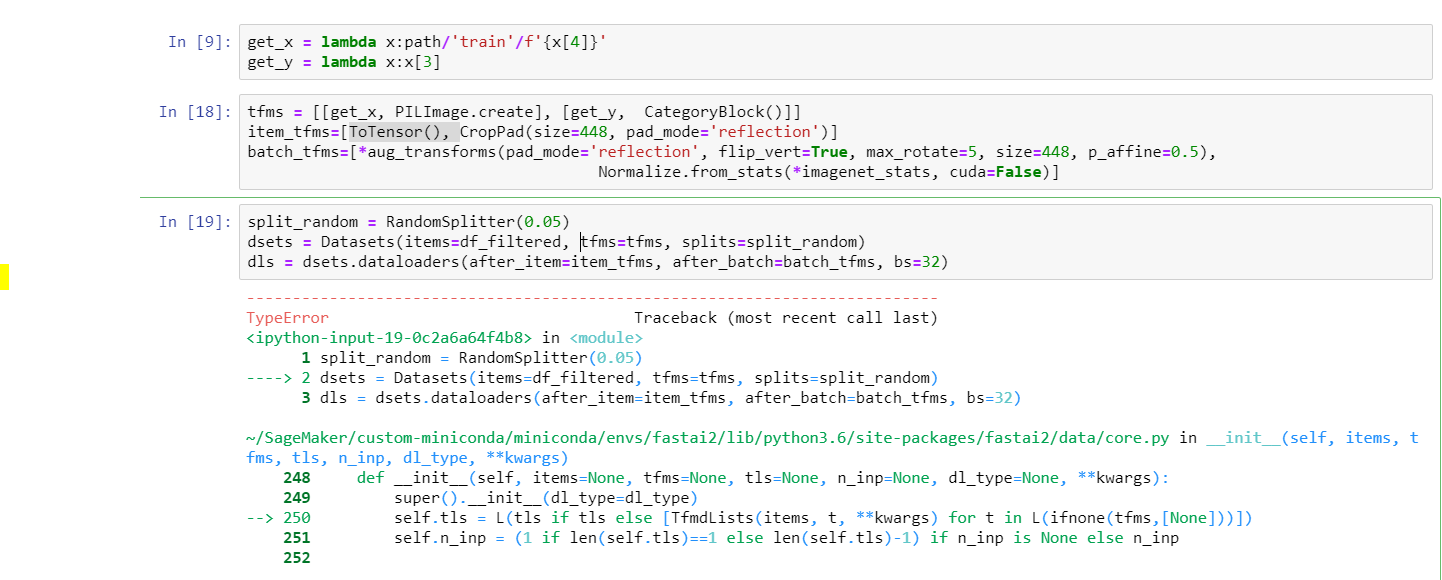
TypeError: 'function' object is not iterable
I wish there was somethink like pets.summary() that could help me here out.
@mgloria I’d look over the summary “hack” discussed in the notebook so you can apply it there. But if I had to guess, it has to do with your splits. Remember we need to call RandomSplit(0.1)(myItems) to actually get the splits. Otherwise we pass in a function (and probably get the above result you got)
I had tried initially doing this split_random = RandomSplitter(0.05)(df_filtered) but TypeError: 'TransformBlock' object is not callable… I guess it is because it is a pandas dataframe.
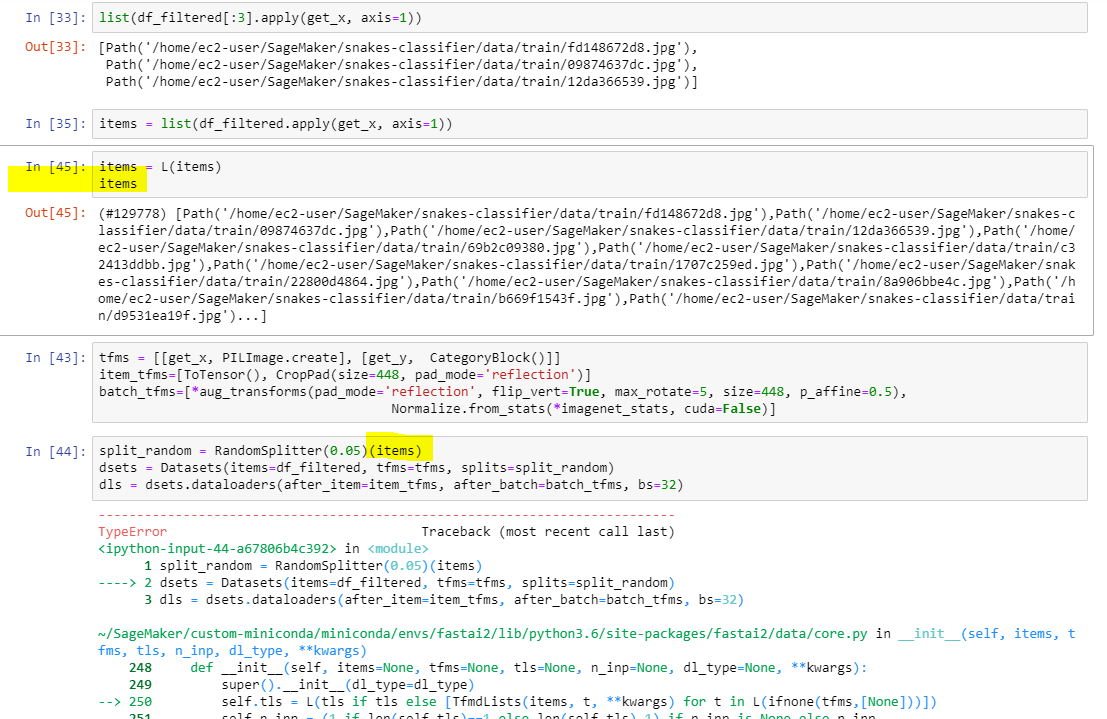
It expects a list of indexs. do RandomSplitter(0.05)(list(range(df_filtered)))
I guess I could do this to get the indices (list(range(df_filtered.shape[0]))) (passing the rows of the dataframe) but still complains that TypeError: 'TransformBlock' object is not callable
1 Like
@mgloria so if we look at MNIST, we can do:
splitter= RandomSplitter(0.1)
splits = splitter(items)
Where items is our get_image_files. Hopefully that’s a hint, best I can look at right now
I tried to be a bit sneaky to pass the paths in an L() but not even like this still TypeError: 'TransformBlock' object is not callable seems like this RandomSplitter is never happy!  I will consult it with my pillow
I will consult it with my pillow
1 Like
OH! @mgloria you’re using CategoryBlock! This is meant for the DataBlock. You should be using Categorize()! (or MultiCategorize if it’s multiple categories at one time)
Running the segmentation nb and when I try to create the unet learner:
learn = unet_learner(dls, resnet34, metrics=acc_camvid, config=config, opt_func=opt)
I encounter a HTTP Error
HTTPError: HTTP Error 403: Forbidden
Any thoughts WHY?? Anybody else have this problem.
The stack dump is LONG - so I have not pasted it in - but seems to be having difficulty downloading the resnet34 model.
Can provide stack dump if that will help.
@Srinivas it’s because you can’t download the pretrained model wherever you are at or it could be something on Colab’s side. I’m unsure. Wasn’t sure if it was an isolated incident. See here and my post below it:
I had the same issue earlier
Thanks for the quick response - I did try a couple of times.
I will try what you suggest.
Awesome! Brilliant that you realized about this details @muellerzr. Should we maybe add this information in the power point? Maybe just the link to the documentation. I was using the power as a reference but the transforms listed are just for Datablock api. This can be maybe a bit confusing since the difference between the two can be easily overlooked.
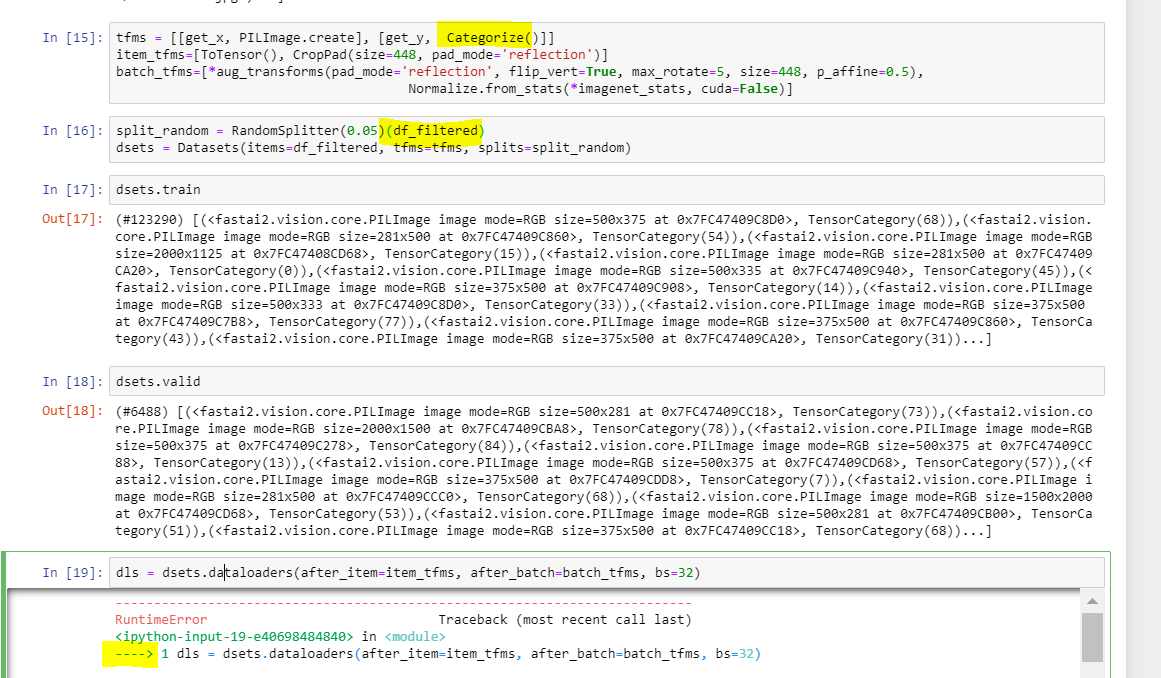
It looks to me now the first part is working.
Interestingly, it works now also with the dataframe -> much easier, no need to pass and L() with the paths
The error I am getting in the dataloaders is
RuntimeError: "uniform_cuda" not implemented for 'Byte'
2 Likes
@mgloria try setting CUDA to true on your dataloader otherwise I’m not sure. I’ve never seen that before.
Thanks again.
I had to manually create the /torch/checkpoints dirs under /root/.cache which already existed.
Then use the commands provided to copy down the model
I am able to proceed now.
FYI for others using colab.
1 Like