Hi everyone,
I’m sharing with you a small code that saves the best model after all epochs of
a training run.
Below is a typical screen shot while calling the fit method.
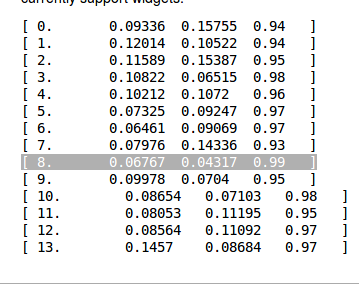
The best model was after the 9th (8th from 0) epoch with 0.99 accuracy on the validation set.
If you use the save_cycle attribute, only the end cycle epoch will be saved. But as a cycle could have many epochs, what if you have your best score after an epoch within a cycle? You’ll miss it. I didn’t do the maths to know whether in this case the 9th epoch was within or at the end of a cycle.
Anyway to solve this problem, I used a callback. I defined a class:
class SaveBestModel(LossRecorder):
def __init__(self, model, lr, name='best_model'):
super().__init__(model.get_layer_opt(lr, None))
self.name = name
self.model = model
self.best_loss = None
self.best_acc = None
def on_epoch_end(self, metrics):
super().on_epoch_end(metrics)
loss, acc = metrics
if self.best_acc == None or acc > self.best_acc:
self.best_acc = acc
self.best_loss = loss
self.model.save(f'{self.name}')
elif acc == self.best_acc and loss < self.best_loss:
self.best_loss = loss
self.model.save(f'{self.name}')
This class inherits from the LossRecorder which in turns inherits (not directly) from CallBack class of the fastai lib. For details, have a look in the file sgdr.py in the fastai lib.
Briefly, I check the model with best accuracy and best loss at the end of each epoch and save it. As I use the same name so the last one saved will be the best of the training run.
Then we have to call it with the fit method like:
lr = np.array([lrf/25., lrf/5., lrf])
my_cb = SaveBestModel(learn, lr, name='best_sgdr')
learn.fit(lr, 2, cycle_len=2, cycle_mult=1, callbacks=[my_cb])
Finally, we can load our best model after the training run as usual:
learn.load('best_sgdr')
learn.TTA()
And that’s all.
Hopefully this will be helpful for some of you.
A final word is that, I’m really appreciating now the good design of the fastai lib. Because when I had this idea, I thought I had to do surgery through the lib to get it work and finally it was not the case. Really neat design @jeremy !