I was reviewing the RNN notebook and have a couple questions.
When we created inputs, we did:
x1 = np.stack(c1_dat[:-2])
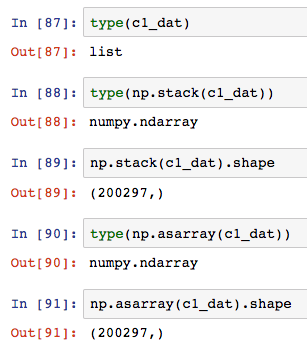
Why do we use np.stack and not np.asarray? I experimented some and they seem to do the same thing, but wanted to make sure I’m not missing something in thinking that the purpose of np.stack here is to convert python list to numpy.ndarray:
The second question is, why did we omit the last two elements in c1_dat? I made idx shorter to see if I can figure it out:
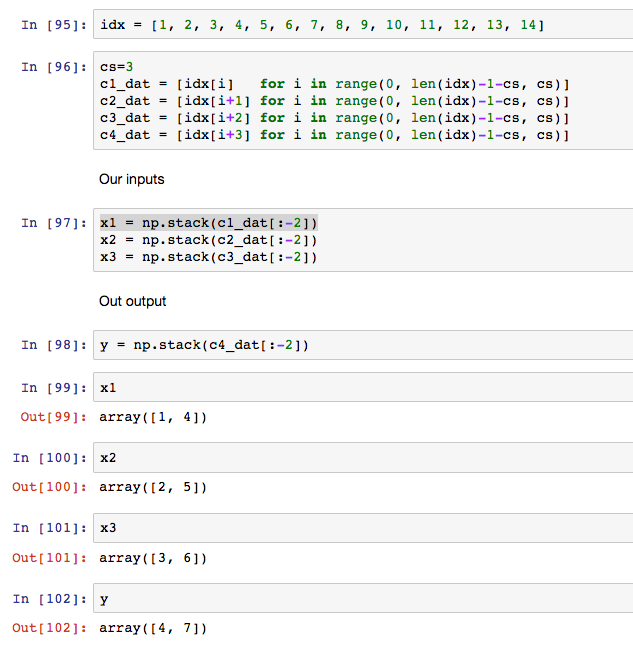
To me, we could have predicted y[2] = 10 from
x1[2] = 7x2[2] = 8x3[2] = 9
And similarly y[3] = 13 from
x1[3] = 10x2[3] = 11x3[3] = 12
If I take -2 out, it will look like
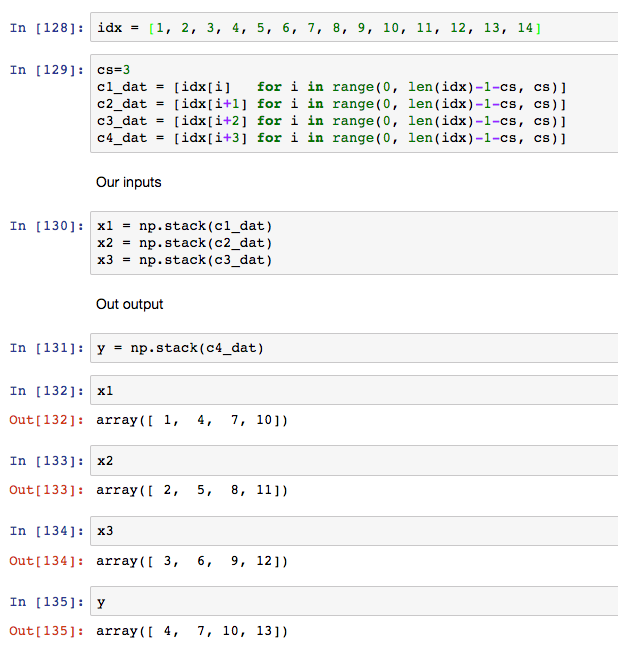
I thought maybe it’s dealing with idx length that is not cleanly divisible by 4 but it seems to handle it fine.
Any advice would be appreciated!