Hi @jeremy I am aware of there was an update for nlp (update ID#ade043e). I did git pull and conda env update. However, I got the following error message by running from fastai.nlp import * which worked previously. I tried to reinstall spacy but the error persisted. Any idea on how to resolve this problem?
<ipython-input-6-6070169c89a3> in <module>()
11 from fastai.rnn_reg import *
12 from fastai.rnn_train import *
---> 13 from fastai.nlp import *
14 from fastai.text import *
15 from fastai.lm_rnn import *
~/fastai/courses/dl1/fastai/nlp.py in <module>()
5 from .dataset import *
6 from .learner import *
----> 7 from .text import *
8 from .lm_rnn import *
9
~/fastai/courses/dl1/fastai/text.py in <module>()
9 def sub_br(x): return re_br.sub("\n", x)
10
---> 11 my_tok = spacy.load('en')
12 my_tok.tokenizer.add_special_case('<eos>', [{ORTH: '<eos>'}])
13 my_tok.tokenizer.add_special_case('<bos>', [{ORTH: '<bos>'}])
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/spacy/__init__.py in load(name, **overrides)
17 "to load. For example:\nnlp = spacy.load('{}')".format(depr_path),
18 'error')
---> 19 return util.load_model(name, **overrides)
20
21
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/spacy/util.py in load_model(name, **overrides)
110 if isinstance(name, basestring_): # in data dir / shortcut
111 if name in set([d.name for d in data_path.iterdir()]):
--> 112 return load_model_from_link(name, **overrides)
113 if is_package(name): # installed as package
114 return load_model_from_package(name, **overrides)
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/spacy/util.py in load_model_from_link(name, **overrides)
124 path = get_data_path() / name / '__init__.py'
125 try:
--> 126 cls = import_file(name, path)
127 except AttributeError:
128 raise IOError(
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/spacy/compat.py in import_file(name, loc)
117 spec = importlib.util.spec_from_file_location(name, str(loc))
118 module = importlib.util.module_from_spec(spec)
--> 119 spec.loader.exec_module(module)
120 return module
121
~/src/anaconda3/envs/fastai/lib/python3.6/importlib/_bootstrap_external.py in exec_module(self, module)
~/src/anaconda3/envs/fastai/lib/python3.6/importlib/_bootstrap_external.py in get_code(self, fullname)
~/src/anaconda3/envs/fastai/lib/python3.6/importlib/_bootstrap_external.py in get_data(self, path)
FileNotFoundError: [Errno 2] No such file or directory: '/home/ubuntu/src/anaconda3/envs/fastai/lib/python3.6/site-packages/spacy/data/en/__init__.py'```


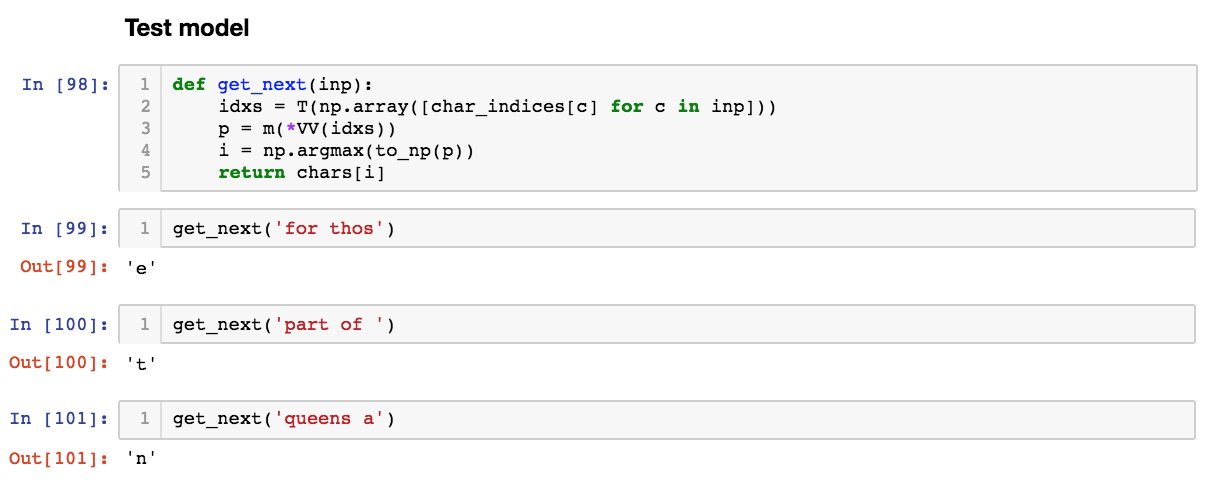
 Here’s the new stuff I learned:
Here’s the new stuff I learned: