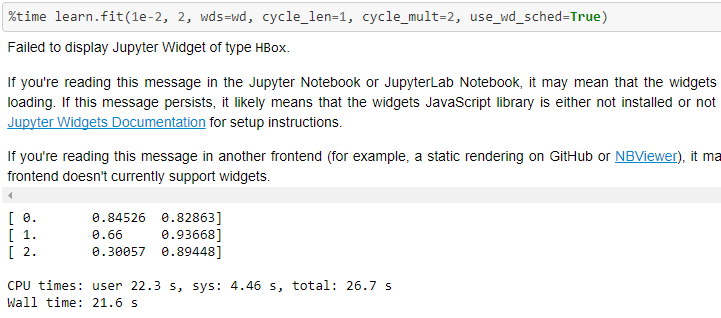
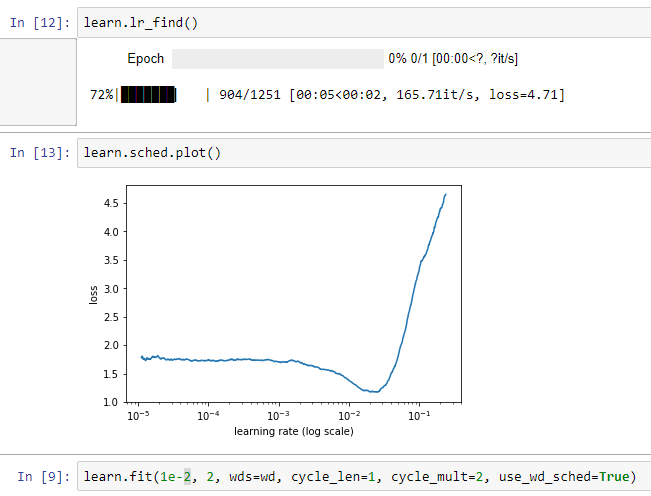
Thanks!
I also have a problem further on when creating the examples by scratch:
fit(model, data, 3, opt, F.mse_loss)
Epoch
0% 0/3 [00:00<?, ?it/s]
0%| | 0/1251 [00:00<?, ?it/s]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-25-09a5bc469dee> in <module>()
----> 1 fit(model, data, 3, opt, F.mse_loss)
~/fastai/courses/dl1/fastai/model.py in fit(model, data, epochs, opt, crit, metrics, callbacks, **kwargs)
83 batch_num += 1
84 for cb in callbacks: cb.on_batch_begin()
---> 85 loss = stepper.step(V(x),V(y))
86 avg_loss = avg_loss * avg_mom + loss * (1-avg_mom)
87 debias_loss = avg_loss / (1 - avg_mom**batch_num)
~/fastai/courses/dl1/fastai/model.py in step(self, xs, y)
41 if isinstance(output,(tuple,list)): output,*xtra = output
42 self.opt.zero_grad()
---> 43 loss = raw_loss = self.crit(output, y)
44 if self.reg_fn: loss = self.reg_fn(output, xtra, raw_loss)
45 loss.backward()
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/functional.py in mse_loss(input, target, size_average)
817
818 def mse_loss(input, target, size_average=True):
--> 819 return _functions.thnn.MSELoss.apply(input, target, size_average)
820
821
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/_functions/thnn/auto.py in forward(ctx, input, target, *args)
45 output = input.new(1)
46 getattr(ctx._backend, update_output.name)(ctx._backend.library_state, input, target,
---> 47 output, *ctx.additional_args)
48 return output
49
TypeError: CudaMSECriterion_updateOutput received an invalid combination of arguments - got (int, torch.cuda.FloatTensor, torch.cuda.DoubleTensor, torch.cuda.FloatTensor, bool), but expected (int state, torch.cuda.FloatTensor input, torch.cuda.FloatTensor target, torch.cuda.FloatTensor output, bool sizeAverage)