Let’s say that you have a categorical variable with cardinality N.
If you 1-hot-encode this variable, you’re essentially transforming it to a set of points in N-dimensional space. This is a suitable representation for a neural net. However, points in that space are subjects to a constraint: they appear only in the corners of an N-dimensional cube, so “almost all” area in that space is not used at all.
Now, if we let each category be an arbitrary point in the N-dimensional space, we can potentially use all available area. Moreover, with the previous constraint removed, and since an embedding is a linear learnable layer, the net can move these points to whatever places that yield the smaller loss at the end.
I don’t know for sure, but it looks like the reason why the max(50, c//2) rule works well in practice is because an embedding space with c//2 dimensions is a very large space, compared to 1-hot-encoded space with c dimensions, so it’ll be more that enough to learn meaningful relationships. The maximum cap of 50 is probably because each dimension “exponentially increases” the “representation power”, so going beyond 50 is an overkill, except when the embedding has to learn really rich representations, like a language model. By saying “exponentially increases” I draw an analogy to discrete spaces, however I don’t know how it properly translates to continuous spaces.
Anyone know which papers he was referring to when he started talking about using rnn’s for imdb?
He said there was some recent papers that had just come out doing something similar to what he is doing.
I’ve found some older papers on using rnn’s for text classification but not much recent.
I’ve got a lingering question about the categorical embeddings and missing data.
I think I follow how slices of the embeddings augment each training example, and can be updated via backprop much the same as any other weights, but does the embedding row that corresponds to “missing” ever get updated if there’s no “missing” examples in the training data? If it doesn’t get trained, does using random weights wreak havoc on performance if a test-observation is missing that category?
In this lesson day of week is used as an example with the Rossman data; I think every training observation has a day-of-week, so does the 8th row of that embedding matrix ever get updated?
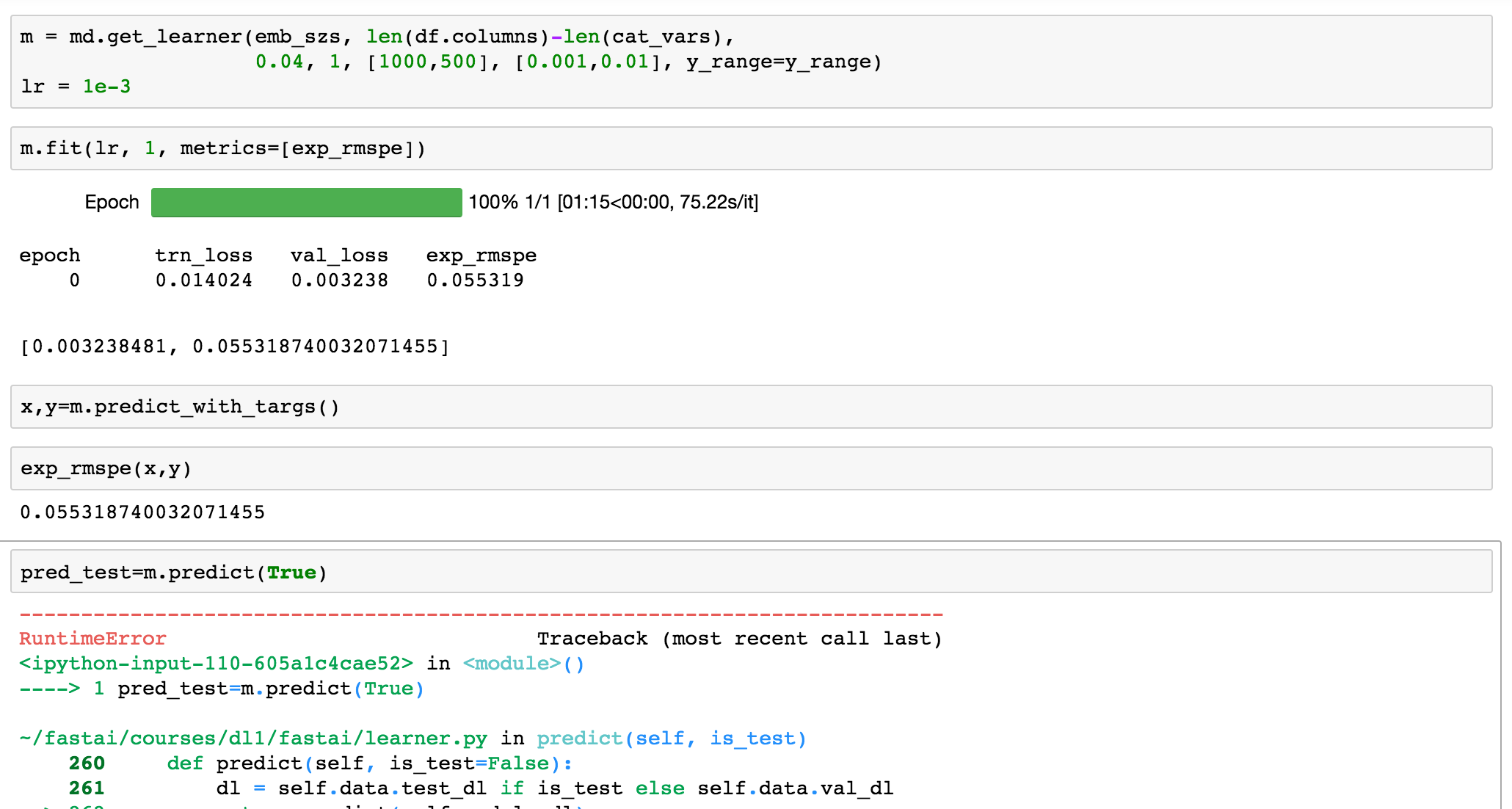
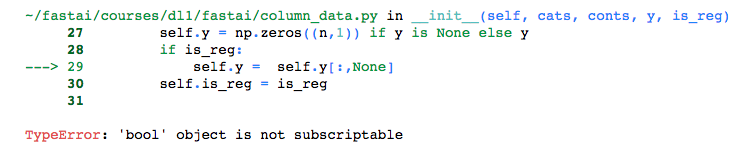
Has anyone been having trouble with the ColumnarDataModel in lesson3-rossman.ipynb? This was working fine last week but now when you try to use a ColumnarDataModel, the fitting procedure is fine and predicts on the training data but fails to predict on the testing data (below is a snippet adapted from lesson3-rossman.ipynb)
I am currently using the most recent version of fastai on github (the last commit id was 58eb7b18f97c19d4f9661e8110b2f8b96d517549)
It appears there were some changes in the github repository recently, I tried rolling back to just before commit id 51218e11f6f6c8603af8b9a84a02098bf9d64a82 (this was a change to the columnarDataModel) and this fixed part of the problem but replaced it with others so there might be an issue here but its not clear to me.
I had this same question, and was wondering if it made sense to randomly overwrite some day of week values (in your example) with “missing” so the training would have to come up with something to do in those cases. In my head this was analogous to using dropout.
so I have fixed this, if you revert back to an old commit on this file, it should fix your problem.
$$ cd to your fastai directory (where the column_data.py file is)
$$ git checkout 51218e11f6f6c8603af8b9a84a02098bf9d64a82~1 – column_data.py
that will fix the problem
Hmm no changes there for me, spacy_tok is a fast.ai method:
spacy_tok??
Signature: spacy_tok(x)
Source: def spacy_tok(x): return [tok.text for tok in my_tok.tokenizer(sub_br(x))]
File: ~/fastai/courses/dl1/fastai/text.py
Type: function
Does it work if you restart the kernel and don’t do the spacy.load('en') cell? I think that’s already happening in fast.ai or pytorch, I just used a cell with it to isolate the issue to that call. But once you’ve seen it work you don’t need that cell any more. But I did just try running it and then the spacy_tok line and it still worked fine, so I don’t think that’s it either.
Hello,
I’m watching the 2017 lesson 4 video Lesson 4: Practical Deep Learning for Coders
And I notice that at about 15 minutes you mention that
'Interestingly, the author of Keras, last week or maybe the week before made the contention that perhaps it will turn out that CNNs are the architecture that will be used for every type of ordered data. This was just after one of the leading NLP researchers released a paper basically showing a state of the art result in NLP using CNN. ’
I’m now looking for articles or papers about the above researchs.
Can you provide me the links of them?
Thanks.
In the spirit of doing first and learning later, what is this lesson4-imdb notebook DOING exactly?
What is this accuracy number? Accuracy at doing what? What is it testing? It’s obviously not guessing something is or is not a dog. What on earth is it getting more accurate at?
I had about roughly same accuracy (~92.5%) as the class video got for IMDB. I only reduced the bs=12 and bptt=70, so it fits in my 8GB 1070.
I was trying to do my own predictions on some text i entered. part of the sentences gets repeated many times, and wondering why is it the case and how we can avoid this.
input: why is
predictions: the acting was terrible , the acting was terrible , the plot was terrible , the acting was terrible , the acting was terrible , the plot was terrible , the acting was terrible , the acting was terrible , the acting was terrible , the acting was terrible , ...
The first time I do pickle dump:
pickle.dump(TEXT, open(f’{PATH}models/TEXT.pkl’,‘wb’))
it returns this error:
PicklingError: Can’t pickle <cyfunction load.. at 0x7f1c88c7c048>: it’s not found as spacy.vocab.lambda
I deleted TEXT.pkl and tried again, but the kernel died
The machine used at paperspace: Fast.ai P5000 Ubuntu 16.04
Python version 3.6.4
spaCy version 1.9.0
Location /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/spacy
Platform Linux-4.4.0-104-generic-x86_64-with-debian-stretch-sid
Installed models en