So in the lesson Jeremy mentioned that the validation images are center cropped to be square. But are the training images also cropped that way? It seems to me it would be the case, but that’s not clear.
Hi all, i tried building an image classifier based the steps outlined in the lesson 1 notebook.
I wrote my first medium post based on the results i had, please check it out and let me know your thoughts
I was doing the dog breeds identification in AWS . I was getting Nan in the training & validation loss while training with differential learning rates.
attached the image
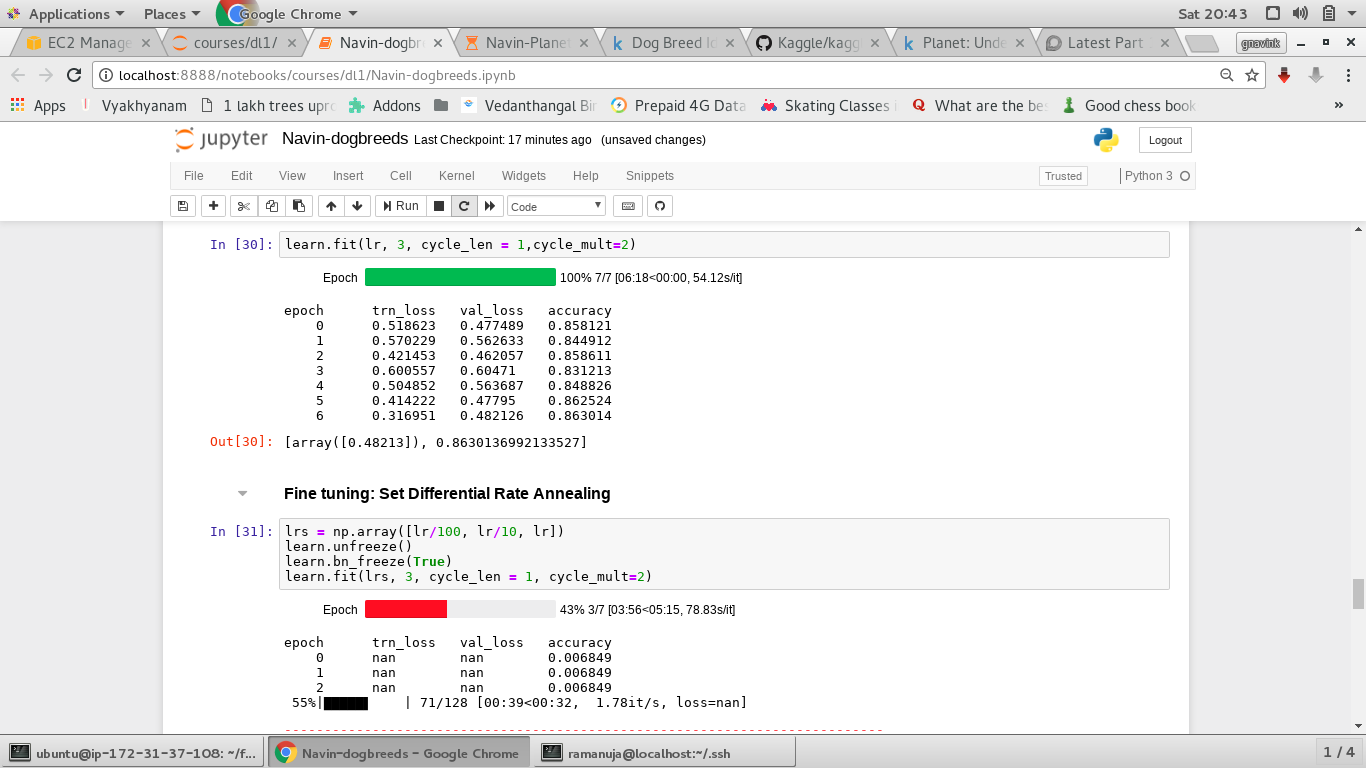
I was using learning rate = 0.2
May I know why it happens.
I have the same question. How is the model handling variable input sizes?
My notebook is similar to Jeremy’s dogbreeds notebook shown in the video except the below:
-
learning rate: Mine Jeremy
0.2 1e-2 -
Arch : resnet34 resent50
Later when I changed the learning rate to 1e-2 the Nan’s observed in the training/validation loss disappeared.
Is it that Nan’s appear when the learning rate is much higher as in this case 0.2 or 0.1 ?
The lr_finder was showing that lr of 0.1 would be a good choice…
Since no one answered, I’d add what I’ve found in case it’s helpful to someone: the code is buried deep in the transforms.py of the fast.ai library. By the code, the cropping of the validation images depend on the cropping of the training images. If the training images are cropped in the “random” or “googlenet” way, then the validation images are centre-cropped; otherwise, the validation images are cropped the same way as the training images.
Guys can anyone tell where to find all trained model weights by jeremy in lectures as i don’t have sufficient computational resources to train which is demotivating as i am not able to see results on my pc of the models which we are making.
This is a non-answer
how did you resolve this?
Having some issues with overfitting on the dog breeds challenge. I walked through the code as Jeremy explained his process but as soon as the first learn.fit(1e-2,5), my results diverge from his.
epoch trn_loss val_loss accuracy
0 0.536105 0.319523 0.902153
1 0.350298 0.297175 0.902642
2 0.254736 0.266593 0.912427
3 0.19815 0.265514 0.91683
4 0.166361 0.253992 0.918297
as you can see, my trn_loss rapidly decreases below the level of val_loss. As I move through the exercise, my trn_loss continues to drop while val_loss maintains at ~0.23-0.25.
I believe I’m overfitting, but i’m confused how this could happen if I’m running ostensibly the same code as Jeremy. The only change I had to make was to the batch size (decreased to 20) because I was running into cuda memory error. Could this cause this issue?
Hi to everyone! Please, help me with some error with notebook lesson2 “Multi-label classification”.
I am using a paperspace, so run cell. Below is the error.

thanks in advance.
Hi @cqfd , I have a doubt regarding “pre_compute” . It is mentioned that we pass in that dataset once (without any data augmentations) to get the activation vectors of each image. But when we go to the code,
Initially, in #1, It is written that pre_compute=True, and then in the next step we do
1.learn.fit(.01,1), doesn’t this mean that the weights of resnet34 arch are getting updated?
- For data augmentation, we put “pre_compute=False” for not computing activation vectors for data augmented images and do “.fit” again. My question is, how do you get activation vector for a rotated image which is diff from actual image. Do we use activation vectors of the original image? Are we passing the rotated image through resnet arch? If yes, that means we are computing activation vectors which goes against pre_compute=False?
I’m slightly confused about points 5.-7.:
Review: easy steps to train a world-class image classifier
- precompute=True
- Use lr_find() to find highest learning rate where loss is still clearly improving
- Train last layer from precomputed activations for 1-2 epochs
- Train last layer with data augmentation (i.e. precompute=False) for 2-3 epochs with cycle_len=1
- Unfreeze all layers
- Set earlier layers to 3x-10x lower learning rate than next higher layer
- Use lr_find() again
- Train full network with cycle_mult=2 until over-fitting
Let’s say that for step 4., I do:
learn.precompute=False
learn.fit(lrs=1e-2, n_cycle=3, cycle_len=1)
If after that, I do
learn.unfreeze()
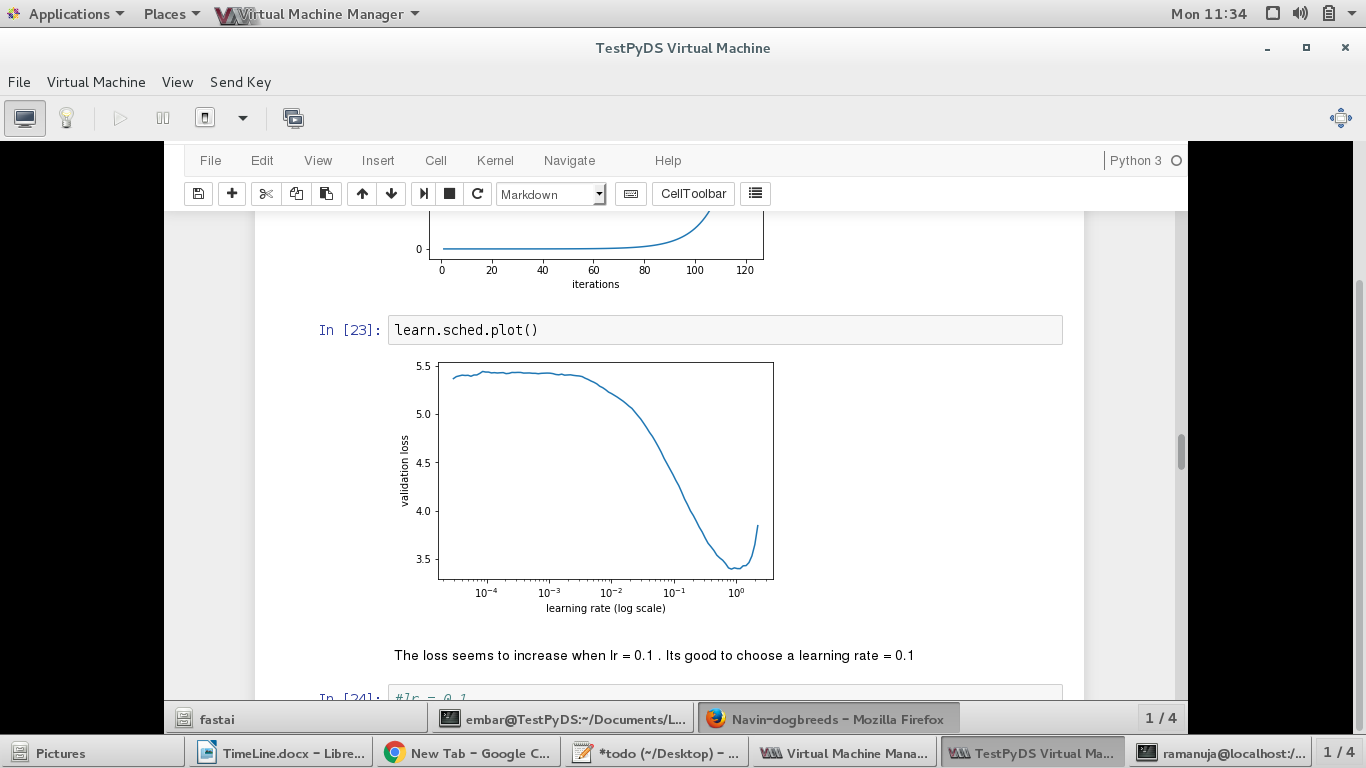
lrf = learn.lr_find()
learn.sched.plot()
then the learning rate finder will show me the loss as a function of learning rate, assuming that I use the same learning rate for all layers However, what I’ll actually do is use differential learning rates, like lrs = np.array([1e-4,1e-3,1e-2]).
So my question is: Can I tell the learning rate finder to show me the loss as a function of late-layer learning rate, assuming that early/middle-layer learning rate is 100/10 times lower than late-layer learning rate?
I’m unable to run any of the other architectures other than resnet34. I’m getting the following errors when I run the notebook.

Could somebody help with this issue? I’m running it on my local machine (windows 10) which has Nvidia gpu.
I didn’t understand that how we can train with different input sizes. On each tutorial people resizes their images into AxA square matrix with same size and same aspect ratio. So the input size of network will be same which is AxA. How can our model adapt itself with different input sizes?
for i in imgs[0:5]:
img1 = PIL.Image.open('tmp/340/train/'+i);
print(img1.size)
(424, 340)
(510, 340)
(453, 340)
(453, 340)
(489, 340)
Why don’t we train the model with precompute= False the very first time? What is the point with running it with True and then running it with False?.
Edit: I found the answer.
" The only reason to have precompute=True is it is much faster (10 or more times). If you are working with quite a large dataset, it can save quite a bit of time. There is no accuracy reason ever to use precompute=True"
In this code snippet, you’re printing the size of the raw dataset. We will resize the images into AxA square matrix to use in the model.
We resize images in the following way.
-
We have initialized a variable called ‘sz’ in the notebook, which is the size that the images will be resized.

-
‘ImageClassifierData’ class from the fastai library will be used to create the data with an appropriate size. This class will resize the images with the specified size.
-
In this example, the variable ‘data’ holds the dataset which will be used while training, where each image is of size 224x224.

Thanks for your answer
But,
-
It is not raw data. We have resized heighs of the images into 340px in get_data function.
Why did we do it? Why did we resized only heighs? -
Why did we built a temp directory?

I ran into the same error. Then figured out that if you are on paperspace DON’t run this cell. Instead, basically use one of the other methods - I used Kaggle cli (search for Kaggle cli on the deep learning website) and follow instructions to set it up - accept Kaggle competition and then use kaggle cli to download the necessary files to paperspace.
Then proceed with the rest of the nb. Just set up a /tmp folder under planet along with /models.
Believe that if you use crestle you need to execute this cell/set of commands.
1 Like
Really, As a begginer I enjoyed a lot. I trust the naming originates from the possibility that a few pictures you would catch from the side (like taking a photograph of a feline or puppy) versus some you bring top-down, like satellite pictures, or sustenance photographs on instagram. In the side-on case, reasonable information enlargements would flip on a level plane, aside from in the incidental instance of the sidewise or topsy turvy hanging feline/puppy . In best down imaging like with satellites, you can turn and flip the picture toward each path and it could in any case resemble a conceivable preparing picture.
Thanks&Regards
Katherine