OK @jeremy,
Indeed, as all parts of implementation are already in the lecture of lesson 2, I thought that the notebook had been made available.
So, I will rewrite them from the lecture, thank you.
@jeremy
Hi Jeremy,
Any way to get the images for dogbreeds competition? Git or download from Kaggle directly? It would be good if there’s a instruction on getting the competition images?
Best & Thanks,
Mac
You can call magic commands in external modules and then import them:
from IPython import get_ipython
get_ipython().magic(u"%matplotlib inline")
get_ipython().magic(u"%reload_ext autoreload")
get_ipython().magic(u"%autoreload 2")
If you put the above in a file named “utils.py”, you can call them via “import utils”, “from utils import *”, or “from utils import some_function”.
3 Likes
Look at values in learn.sched.lrs and learn.sched.losses array. Maybe they are out of bounds of your plot?
1 Like
- You can think about the model as if it consists of two parts:
a) a few convolutional layers that get raw pixels as input and produce a vector of size 1024.
b) 2 dense layers. The first has 1024 features as input, 512 features as output, the second gets 512 features as input and produces 2 as output. These 2 outputs (after applying softmax) are probabilities for cat vs dog.
If you initialize the learner with precompute=True parameter, the learner is doing a smart computational optimization. It evaluates the 1st part of the model (convolutional layers) for every image in your dataset. As a result, it computes a vector of 1024 numbers for each image. This is what is called “precomputed activations”.
Then when you train the model on your dogs’n’cats dataset, the learner doesn’t do all calculations for the convolutional layers again. It just gets the precomputed activations for every image, and trains only the 2nd part of the model - two dense layers. It speeds up the training a lot because two dense layers are a very small part of the entire model, it doesn’t take much time to execute.
Of course, precomputing activations will help only if you don’t want to retrain convolutional layers.
- The general idea of freezing lower layers is that you want to preserve information that was gained when the original model was trained on the large dataset. Unfreezing all layers would likely lead to forgetting of some important low level filters.
Above I described that precompute helps to optimize training when you want to train the last two dense layers and “freeze” all the convolutional layers.
You can decide to do something else, e.g. freeze only the first few convolutional layers and train the last few convolutional layers and dense layers.
When you train the model, the forward pass goes through all the layers. But when you calculate an error and do backpropagation, you update only weights of layers that are “unfrozen” and don’t change weights in “frozen” layers.
Using fastai library, you have a fine-grained control on which layers are “frozen” (untrainable) and which are “unfrozen” (trainable).
21 Likes
Watching Lesson 3 combined with your answer has improved my understanding extensively. Thank you for the detailed post !
Thanks. Will definitely take a look at that.
[some edits for clarification]
The following question has probably been answered somewhere here, but I haven’t yet seen a complete response.
With so many other reliable metrics, why do we use accuracy as our primary or initial measure of model goodness? In the first lesson, we do look at the confusion matrix. I’ve also seen AUC (area under the ROC curve) used as a more robust measure of the goodness of a model and it’s simple enough to compute.
So why not refine our network until the AUC stops getting better, instead of the accuracy? Am I overlooking something else in the network refinement strategy that makes the AUC or other metrics actually not as critical a measure for deep nets as I’ve assumed?
Thanks
I think AUC is a fine metric to use. It’s often used for Kaggle competitions, in fact.
Generally however accuracy is a little more intuitive to interpret, and being intuitive is important for understanding how our model is training. Also, accuracy is often the measure that’s closest to what matters in practice for the final model. AUC and accuracy are closely related, of course. Using both is a good idea!
3 Likes
In lesson 1 @jeremy uses differential learning rates as
lr=np.array([1e-4,1e-3,1e-2])
In lesson 2 he uses following
lr = 0.2
lrs = np.array([lr/9,lr/3,lr])
He says that, he used /3 and /9 so that he could train the middle layers more as the dataset is different than image net.
My question: what is the relation between higher or lower learning rates to training more or training less?
Did I miss something in video??
Thanks!
My thinking here is that a higher learning rate will push the weights around more - and therefore will give less credence to the pretrained weights. So in lesson 2 the earlier layers have higher relative weights, which means we’re pushing the weights further from the pretrained network.
Having said that, I haven’t done rigorous experiments, and I haven’t seen this technique used elsewhere, so take my theory with a grain of salt. @sebastianruder is helping run some experiments at the moment that may give some initial data on this, but it might be a few months before we have anything really concrete to show.
2 Likes
Hello, I am a student with a pretty basic laptop with 2gb 940MX. I am currently stuck at the part where we unfreeze all the layers of the network and train them and it is showing an error of ‘OUT OF MEMORY’. I don’t have access to any cloud GPU’s either. I just have one solution to go ahead if i could get the file ‘224_all.h5’ that is located under models folder under the dogs-vs-cats dataset folder from anyone who has trained the model. Really appreciated if anyone could provide me with the file. Thank you.
Try using a much smaller batch size, and a small architecture (eg resnet18).
Thank you sir for replying, I tried that but all in vain it still gives error of out of memory. Only solution I can see here now is if anyone could provide me with the weights of the fully trained resnet34. Thank you.
Hi,
In the loss vs iterations plot generated by learn.sched.plot_loss(), the loss is computed from a mini-batch or is it for the entire training dataset?
After every iteration, is the loss of entire training set computed for this plot? Or is the loss computed from the mini-batch that was used for the iteration?
Thanks.
I tried to re-create the Dog-breed competition shown in the Lesson 2 video, but When I tried to use the TTA method, I receive an error:
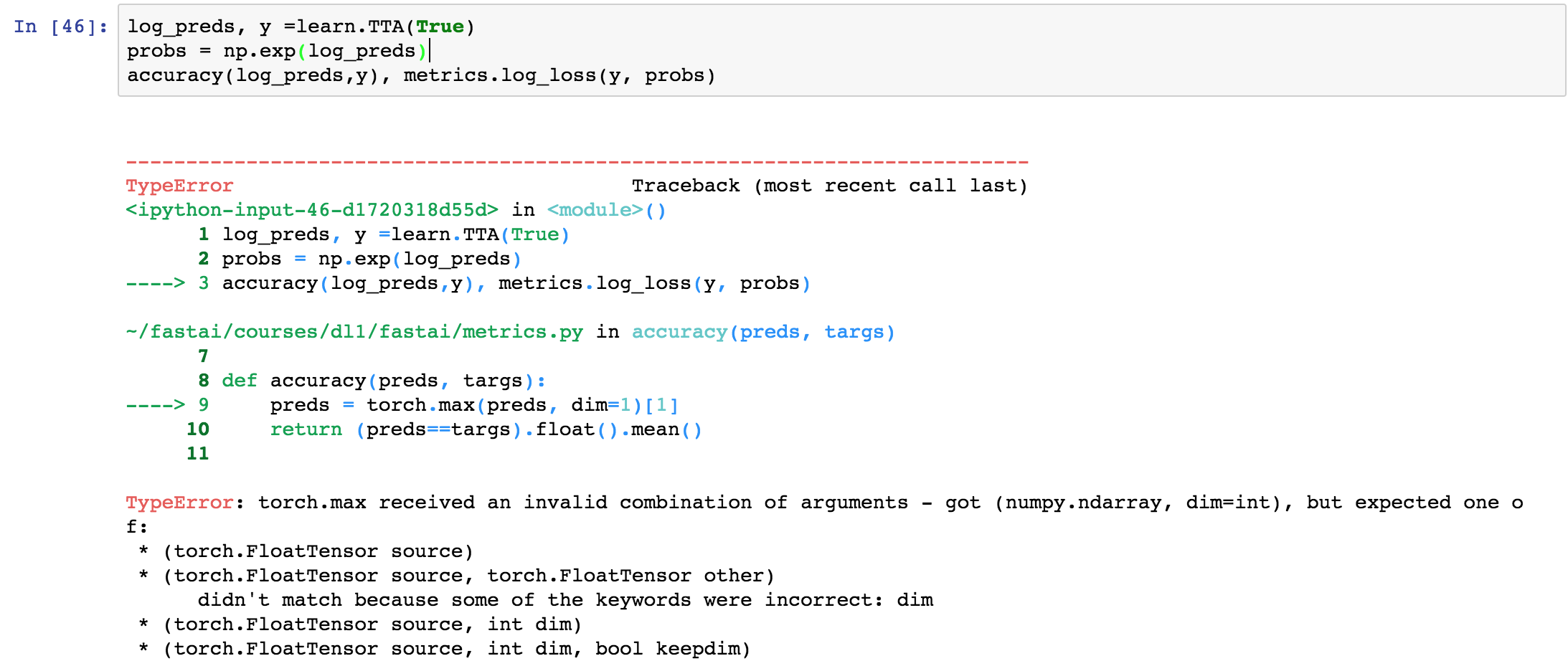
Does anybody know what’s the meaning and how to solve it?
I am not familiar with English too much, maybe there are some post had discussed this problem before.But any reply should be helpful, Thanks a lot.
1 Like
Thanks for your correction,But I still got the same TypeError
1 Like
Hi guys, I could not find the file/folder that contains label information for cats/dogs classification in the dataset. How does the model learn without labeling?
Edit: I found that all cat images were put in one folder while dogs in the other one, probably they were labeled in this way, which I am not quite familiar with.