How to change the batch size?
I can’t find this variable in the code!
Batch size is identified in the def get_augs() function as bs.
1 Like
You can change your batch size like so:
data = ImageClassifierData.from_paths (path, tfms=tfms, bs=30, …)
Hope this helps.
1 Like
I have a question…
How could the classifier asses itself on the test set while it doesn’t know the correct answers of the test set?
I mean how could the classifier be sure that it will achieve certain accuracy 98 or 99 when it only knows the correct answers of the validation set but not the test set?
How could it be sure that it will achieve exactly the same accuracy as the validation set on the test set?
1 Like
Hey guys, check out my first medium post, its based on an image classifier i wrote.
please let me know your thoughts
1 Like
Hi everyone!
I’m having a hard time with using the fast.ai library on a Linux machine (ScientificLinux7 ) I SSH to. In short: When building resnet50, the machine I SSH to is unable to locate the pre-trained model.
I set up the fast.ai on the machine by following the instructions on the wiki. When I try to build the fast.ai model:
PATH = 'my_data/hep_images/' sz = 300 arch = resnet50 data = ImageClassifierData.from_paths(PATH,tfms=tfms_from_model(arch, sz),bs=32 ) learn = ConvLearner.pretrained(arch, data, precompute=True)
This results in the following error:
`
FileNotFoundError Traceback (most recent call last)
in ()
2 arch = resnet50
3 data = ImageClassifierData.from_paths(PATH,tfms=tfms_from_model(arch, sz),bs=32 )
----> 4 learn = ConvLearner.pretrained(arch, data, precompute=True)
/mnt/scratch/eab326/fastai/courses/dl1/fastai/conv_learner.py in pretrained(cls, f, data, ps, xtra_fc, xtra_cut, custom_head, precompute, pretrained, **kwargs)
111 pretrained=True, **kwargs):
112 models = ConvnetBuilder(f, data.c, data.is_multi, data.is_reg,
–> 113 ps=ps, xtra_fc=xtra_fc, xtra_cut=xtra_cut, custom_head=custom_head, pretrained=pretrained)
114 return cls(data, models, precompute, **kwargs)
115
/mnt/scratch/eab326/fastai/courses/dl1/fastai/conv_learner.py in init(self, f, c, is_multi, is_reg, ps, xtra_fc, xtra_cut, custom_head, pretrained)
38 else: cut,self.lr_cut = 0,0
39 cut-=xtra_cut
—> 40 layers = cut_model(f(pretrained), cut)
41 self.nf = model_features[f] if f in model_features else (num_features(layers)*2)
42 if not custom_head: layers += [AdaptiveConcatPool2d(), Flatten()]
/mnt/scratch/eab326/anaconda3/envs/fastai/lib/python3.6/site-packages/torchvision/models/resnet.py in resnet50(pretrained, **kwargs)
186 model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
187 if pretrained:
–> 188 model.load_state_dict(model_zoo.load_url(model_urls[‘resnet50’]))
189 return model
190
/mnt/scratch/eab326/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/utils/model_zoo.py in load_url(url, model_dir, map_location)
55 model_dir = os.getenv(‘TORCH_MODEL_ZOO’, os.path.join(torch_home, ‘models’))
56 if not os.path.exists(model_dir):
—> 57 os.makedirs(model_dir)
58 parts = urlparse(url)
59 filename = os.path.basename(parts.path)
/mnt/scratch/eab326/anaconda3/envs/fastai/lib/python3.6/os.py in makedirs(name, mode, exist_ok)
218 return
219 try:
–> 220 mkdir(name, mode)
221 except OSError:
222 # Cannot rely on checking for EEXIST, since the operating system
FileNotFoundError: [Errno 2] No such file or directory: ‘/home/eab326/.torch/models’
`
I’d appreciate any help resolving this issue. Thank you!
I guess that your question got lost among others and as I didn’t see anyone answer I will try to explain (I guess you know by now, but at least it can be registered for posterity).
So, an epoch is one pass in all the training set. The batch size is how many images you analyse at once. See, images are represented as tensors (n dimensional arrays) and you can make calculations with big tensors or small tensors.
If you use big tensors it is faster because you need less computations to pass through all your data. In other words, you need less iterations to finish an epoch. But you will also need more memory to keep that big tensor (the batch) in RAM. In general, you want to keep batches as big as your GPU memory allow.
To set the batch size you can try different sizes and keep an eye in your GPU usage (nvidia-smi command). If you set it too high, your code will have a runtime error. If that happens, try to reduce the batch size.
Hey guys, check out next part of the blog on data visualization techniques. Any suggestions, queries and comments are most welcomed.
ConvLearner.pretrained should work in Kaggle Kernels now if you turn on the new Internet connected option. I’ve got lesson 1 running in this kernel: https://www.kaggle.com/hortonhearsafoo/fast-ai-lesson-1
Hello everybody,
I am Murali from India. I feel this course is a perfect complementary after Andrew NG’s deep learning specialization.
I started a series ‘Fast.AI Deep Learnings’ where I would like to practically implement and share my experiences about each topic.
Here is the first post
Please provide your feedback 
2 Likes
Just for the record, I had two problems with my computer. The first was that the PSU was broken and would crash the computer. The second was that 16GB was apparently not enough. I have now upgraded to 32GB and a got a new PSU (650W) and I can now run all the fastai exercises.
Encounter problem to train a new dataset in lesson 1.
I have download some images of snake and bear through Google. Then I try to train a new dataset by referring to lesson 1’s notebook.
Following are my input in the notebook
PATH = “data/bearsnake/”
subfolder1=‘bear’
subfolder2=‘snake’
sz=224
os.makedirs(‘data/bearsnake/models’, exist_ok=True)
os.makedirs(‘data/bearsnake/train’, exist_ok=True)
os.makedirs(‘data/bearsnake/valid’, exist_ok=True)
import zipfile
path_to_zip_file= ‘data’ + ‘/bearsnake.zip’
directory_to_extract_to=‘data/bearsnake/train’
zip_ref = zipfile.ZipFile(path_to_zip_file, ‘r’)
zip_ref.extractall(directory_to_extract_to)
zip_ref.close()
Everything above are alright. I can see the images to be show.
img = plt.imread(f’{PATH}valid/bear/{files[0]}’)
plt.imshow(img);
The problem comes out when I try to train the model.
arch=resnet34
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz))
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(0.01, 3)
Following is the error message from notebook
OSError Traceback (most recent call last)
in ()
1 arch=resnet34
2 data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz))
----> 3 learn = ConvLearner.pretrained(arch, data, precompute=True)
4 learn.fit(0.01, 3)
~/fastai/courses/dl1/fastai/conv_learner.py in pretrained(cls, f, data, ps, xtra_fc, xtra_cut, custom_head, precompute, pretrained, **kwargs)
112 models = ConvnetBuilder(f, data.c, data.is_multi, data.is_reg,
113 ps=ps, xtra_fc=xtra_fc, xtra_cut=xtra_cut, custom_head=custom_head, pretrained=pretrained)
–> 114 return cls(data, models, precompute, **kwargs)
115
116 @classmethod
~/fastai/courses/dl1/fastai/conv_learner.py in init(self, data, models, precompute, **kwargs)
98 if hasattr(data, ‘is_multi’) and not data.is_reg and self.metrics is None:
99 self.metrics = [accuracy_thresh(0.5)] if self.data.is_multi else [accuracy]
–> 100 if precompute: self.save_fc1()
101 self.freeze()
102 self.precompute = precompute
~/fastai/courses/dl1/fastai/conv_learner.py in save_fc1(self)
177 m=self.models.top_model
178 if len(self.activations[0])!=len(self.data.trn_ds):
–> 179 predict_to_bcolz(m, self.data.fix_dl, act)
180 if len(self.activations[1])!=len(self.data.val_ds):
181 predict_to_bcolz(m, self.data.val_dl, val_act)
~/fastai/courses/dl1/fastai/model.py in predict_to_bcolz(m, gen, arr, workers)
15 lock=threading.Lock()
16 m.eval()
—> 17 for x,*_ in tqdm(gen):
18 y = to_np(m(VV(x)).data)
19 with lock:
~/anaconda3/envs/fastai/lib/python3.6/site-packages/tqdm/_tqdm.py in iter(self)
929 “”", fp_write=getattr(self.fp, ‘write’, sys.stderr.write))
930
–> 931 for obj in iterable:
932 yield obj
933 # Update and possibly print the progressbar.
~/fastai/courses/dl1/fastai/dataloader.py in iter(self)
86 # avoid py3.6 issue where queue is infinite and can result in memory exhaustion
87 for c in chunk_iter(iter(self.batch_sampler), self.num_workers*10):
—> 88 for batch in e.map(self.get_batch, c):
89 yield get_tensor(batch, self.pin_memory, self.half)
90
~/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/_base.py in result_iterator()
584 # Careful not to keep a reference to the popped future
585 if timeout is None:
–> 586 yield fs.pop().result()
587 else:
588 yield fs.pop().result(end_time - time.time())
~/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/_base.py in result(self, timeout)
430 raise CancelledError()
431 elif self._state == FINISHED:
–> 432 return self.__get_result()
433 else:
434 raise TimeoutError()
~/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/_base.py in __get_result(self)
382 def __get_result(self):
383 if self._exception:
–> 384 raise self._exception
385 else:
386 return self._result
~/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/thread.py in run(self)
54
55 try:
—> 56 result = self.fn(*self.args, **self.kwargs)
57 except BaseException as exc:
58 self.future.set_exception(exc)
~/fastai/courses/dl1/fastai/dataloader.py in get_batch(self, indices)
73
74 def get_batch(self, indices):
—> 75 res = self.np_collate([self.dataset[i] for i in indices])
76 if self.transpose: res[0] = res[0].T
77 if self.transpose_y: res[1] = res[1].T
~/fastai/courses/dl1/fastai/dataloader.py in (.0)
73
74 def get_batch(self, indices):
—> 75 res = self.np_collate([self.dataset[i] for i in indices])
76 if self.transpose: res[0] = res[0].T
77 if self.transpose_y: res[1] = res[1].T
~/fastai/courses/dl1/fastai/dataset.py in getitem(self, idx)
194 xs,ys = zip(*[self.get1item(i) for i in range(*idx.indices(self.n))])
195 return np.stack(xs),ys
–> 196 return self.get1item(idx)
197
198 def len(self): return self.n
~/fastai/courses/dl1/fastai/dataset.py in get1item(self, idx)
187
188 def get1item(self, idx):
–> 189 x,y = self.get_x(idx),self.get_y(idx)
190 return self.get(self.transform, x, y)
191
~/fastai/courses/dl1/fastai/dataset.py in get_x(self, i)
271 super().init(transform)
272 def get_sz(self): return self.transform.sz
–> 273 def get_x(self, i): return open_image(os.path.join(self.path, self.fnames[i]))
274 def get_n(self): return len(self.fnames)
275
~/fastai/courses/dl1/fastai/dataset.py in open_image(fn)
249 raise OSError(‘No such file or directory: {}’.format(fn))
250 elif os.path.isdir(fn) and not str(fn).startswith(“http”):
–> 251 raise OSError(‘Is a directory: {}’.format(fn))
252 else:
253 #res = np.array(Image.open(fn), dtype=np.float32)/255
OSError: Is a directory: data/bearsnake/train/ snake/.ipynb_checkpoints
My question is what should I do rectify or u show me the steps to train a different dataset.
Please click following pdf file for the screenshot in jupyter notebook
lesson1-(diff dataset).pdf (343.7 KB)
I saw this warning message when running lesson 1 cell 2 (everything worked fine despite the warning)
/home/ubuntu/src/anaconda3/envs/fastai/lib/python3.6/site-packages/sklearn/ensemble/weight_boosting.py:29: DeprecationWarning: numpy.core.umath_tests is an internal NumPy module and should not be imported. It will be removed in a future NumPy release.
from numpy.core.umath_tests import inner1d
This is the very latest code updated from GitHub today (September 3 2018)
I successfully trained a classifier to distinguish between steam and diesel locomotives incidentally 
I’m attempting to go through the PyTorch Beginner Blitz tutorial, which appears to be out of date (3 statements failed in the first 5). Can anyone recommend an alternative?
I’m running on a fresh fastai paperspace installation.
Thanks!
EDIT: apparently the tutorial is incompatible with the PyTorch 0.3.1.post2 in the installation.
I’ve just set up on Paperspace - the first notebook runs fine in jupyter notebook, but there are some errors locating packages when using jupyter lab. I just thought I’d mention it in case anyone tries to use lab - if you get errors stick with notebook.
I’m trying to run cell 3 in lesson one and I keep getting this error message:
The kernel appears to have died. It will restart automatically.
Is this something to do with the warning received while running cell 2:
/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/sklearn/ensemble/weight_boosting.py:29: DeprecationWarning: numpy.core.umath_tests is an internal NumPy module and should not be imported. It will be removed in a future NumPy release.
from numpy.core.umath_tests import inner1d
I am still trying to set up my Paperspace machine. I was able to follow along without issue until I invoked “jupyter notebook” at which point I should get the following output:
(fastai) paperspace@psgyqmt1m:~/fastai$ jupyter notebook
[I 17:16:50.591 NotebookApp] Writing notebook server cookie secret to /run/user/1000/jupyter/notebook_cookie_secret
[W 17:16:51.110 NotebookApp] WARNING: The notebook server is listening on all IP addresses and not using encryption. This is not recommended.
[I 17:16:51.122 NotebookApp] Serving notebooks from local directory: /home/paperspace/fastai
[I 17:16:51.122 NotebookApp] 0 active kernels
[I 17:16:51.122 NotebookApp] The Jupyter Notebook is running at:
[I 17:16:51.122 NotebookApp] http://[all ip addresses on your system]:8888/?token=44cd3335e311c181531f38031095a217b01127d8152aa3fd
[I 17:16:51.122 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 17:16:51.123 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=44cd3335e311c181531f38031095a217b01127d8152aa3fd
However, what I see is:
jupyter notebook
[I 10:03:16.085 NotebookApp] Writing notebook server cookie secret to /run/user/1000/jupyter/notebook_cookie_secret
Traceback (most recent call last):
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/traitlets/traitlets.py”, line 528, in get
value = obj._trait_values[self.name]
KeyError: ‘allow_remote_access’
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/notebook/notebookapp.py”, line 869, in _default_allow_remote
addr = ipaddress.ip_address(self.ip)
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/ipaddress.py”, line 54, in ip_address
address)
ValueError: ‘’ does not appear to be an IPv4 or IPv6 address
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “/home/paperspace/anaconda3/envs/fastai/bin/jupyter-notebook”, line 11, in
sys.exit(main())
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/jupyter_core/application.py”, line 266, in launch_instance
return super(JupyterApp, cls).launch_instance(argv=argv, **kwargs)
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/traitlets/config/application.py”, line 657, in launch_instance
app.initialize(argv)
File “”, line 2, in initialize
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/traitlets/config/application.py”, line 87, in catch_config_error
return method(app, *args, **kwargs)
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/notebook/notebookapp.py”, line 1629, in initialize
self.init_webapp()
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/notebook/notebookapp.py”, line 1379, in init_webapp
self.jinja_environment_options,
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/notebook/notebookapp.py”, line 158, in init
default_url, settings_overrides, jinja_env_options)
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/notebook/notebookapp.py”, line 251, in init_settings
allow_remote_access=jupyter_app.allow_remote_access,
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/traitlets/traitlets.py”, line 556, in get
return self.get(obj, cls)
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/traitlets/traitlets.py”, line 535, in get
value = self._validate(obj, dynamic_default())
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/notebook/notebookapp.py”, line 872, in _default_allow_remote
for info in socket.getaddrinfo(self.ip, self.port, 0, socket.SOCK_STREAM):
File “/home/paperspace/anaconda3/envs/fastai/lib/python3.6/socket.py”, line 745, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
socket.gaierror: [Errno -2] Name or service not known
Does anyone have any idea what may be going wrong here?
2 Likes
Hey guys, a question about Week 1. The video course reaches up to the “Learning Rate” part of the Notebook. Are we supposed to play with and understand the parts that come after that? The part about improving our model? I didn’t understand that part at all in the notebook.
Hi, when we create an array of 3 learning rates. Are all the layers divided evenly and then applied to the layers?
Interesting Result: I tried to classify stock images of women vs barbie doll images (it was my wife’s idea) for the ‘homework’ for week 1. I was surprised that I only got an accuracy of 0.5, like a coin flip. Anyone know why resnet would not perform well here? The results seem to vary from iteration to iteration but the accuracy hovers around 50%. In this run for example, you see that most of the predictions are barbies (<0.5)
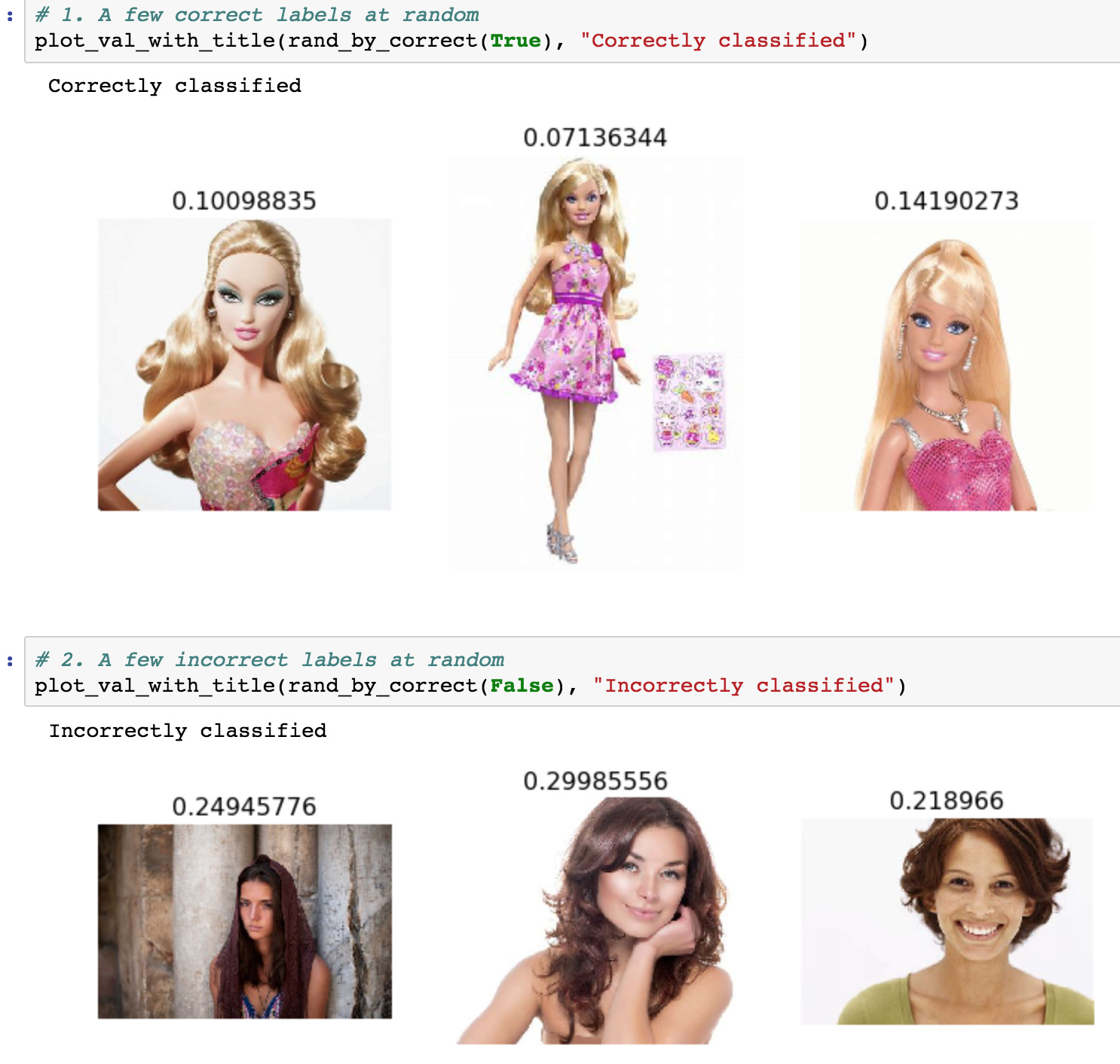
edit: I think the reason may have to do with the fact that I only used 20 images in train and validation sets. In lesson 1, Jeremy had said using 10 images for each class would be ok but as I listen to Lesson 2, I hear he suggests ‘a couple hundred’. So maybe my problem is that I did not download hundreds of images. Although I thought that maybe this would not be necessary as the model was pre-trained.
I am guessing that I will gain more understanding as the course progresses.
1 Like