try: !rm -r {PATH}train/.ipynb_checkpoints
also do this for valid.
try: !rm -r {PATH}train/.ipynb_checkpoints
also do this for valid.
Hi guys,how do i resolve this issue? The directory exists, just that there is supposed to be a slash in between Fastaipics and valid, which looks something like Fastaipics/valid… Thanks!
I get this when i set replace=False. What does it mean by “cannot take a larger sample than the population” and how do i work around this?
Thanks!
Hello everyone,
I’m trying to reproduce the first notebook on a sample of the original dogscats dataset (around 200 pictures) by following the instructions given at the end of the notebook (section called “Review: easy steps to train a world-class image classifier”), but I’m a bit confused.
I have difficulty understanding this two times procedure corresponding to the points
which I implemented with
learn.fit(0.05, 2)
learn.precompute = False
learn.fit(0.05, 3, cycle_len=1)
There are two things I don’t understand:
Sorry for my naivety, I’m really a beginner.
Thanks in advance!
Another quick question about how to use lr_find():
I don’t really understand the purpose of the variable lrf in the cell with
lrf=learn.lr_find()
it looks like lrf doesn’t reappear anywhere else in the code. I had the impression that the aim of this lr_find method was to be then able to do the plot with the command
learn.sched.plot()
and then to choose a good learning rate by looking at the plot.
Did I get something wrong?
Thanks in advance.
Precompute and tfms (transformations) have a well discussed thread in this forum… Here’s it
(precompute=True) Answer’s to 3 and 4
lrf=learn.lr_find() we can skip that lrf but it’s quite useful though in the later stages
We can use that lrf as shown below,
lrs = np.array([ 1, 2, 3 ]); learn.lr_find(lrs / 1000)It is based on this Cyclical Learning Rates for Training Neural Networks
@nickl
Aha!
It looks like someone submitted a pull request to fix lesson 2, but the Lesson 1 notebook still needs the fix.
I’ll fix the Lesson 1 notebook and submit a pull request.
the repo is now updated to work with 2.x and 3.x both!
Is there a script to set up a conda environment on my own ubuntu machine with all needed libraries for fast.ai? all that is mentioned here so far concerns a cloud installation. Nevertheless, I seem to possess the latest mobile GPU and wanna give it a go.
I understand the overall concept of the Notebook now. When going line by line, following line stood out
Why is that we use only the probability of dog throughout the notebook. Why don’t we use the probability of cat anywhere? I presume we could’ve used either one as the sum of probability along each row is one or almost 1.
I think they are moved to the fastai repo.
However, I don’t see the folded table of contents in the notebook from lesson 1. Am I missing something?
Hi,
I have just started with fastai Part1v2 course and have finished watching the first video. How are the files divided in Train/Valid etc? How do I know more about these terms and dividing files accordingly?
Interested to find out more about this too!
@alessa / @lukebyrne do you guys have any insights? I saw a post [Wiki: Lesson 1] which talked briefly about this, but I’m not sure if this was ever resolved.
Reason I’m asking is that the ImageClassifierData.from_paths method takes the following args:
trn_name: a name of the folder that contains training images.
val_name: a name of the folder that contains validation images.
test_name: a name of the folder that contains test images.
Any insights into the train/valid/test split required to feed into this method will be really helpful.
Thanks!
Here you find more details stackoverflow
Usually the dogs and cats examples have only train and valid dataset, where the training dataset is 12500 files per class, and the validation dataset is 1000 files per class (~7% of the data).
What you need to pay attention is when you build your datasets, to cut sample files from training dataset and move then in the validation dataset. (Instead of just copy paste).
If you do kaggle competition for example, you will have also a test dataset (with no labels/classes). In this case, you can train your model using the cross-validation technique. And in the end, you can put all of your files in the training dataset (no more validation set), and this will be your final weights.
Here is a short video on how to split the data by Andrew Ng Coursera
[60% training, 20% validation, 20% test]
You can change these params and check how it affects your final model performance.
Thanks @alessa! This was helpful for a general train / test / split. I was wondering more specifically -
do you know of any specific setup requirements for the train / test / split for fastAi’s method?
Thanks again.
When choosing a learning rate with the LR finder, you can plot a vertical line to ensure you choose the correct x-coordinate of the point you’re interested in. Otherwise it can be difficult to interpret values on the x-axis, since they’re in log scale.
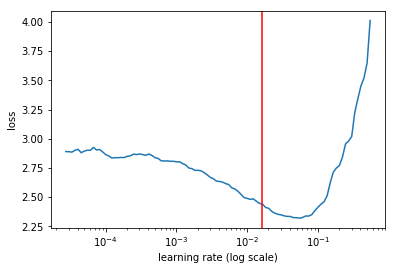
import matplotlib.pyplot as plt
learn.sched.plot()
plt.axvline(x=1.6e-2, color="red");
Also adding %matplotlib notebook seems awesome (edit the same plot until created a new one)
Kaggle CatsDogs Redux Kernel competition asks us to report whats the probability of that image to be a dog.hence interested in calculating dog probability