I think this can be done and would make for a really cool blog post to write
The easiest and slightly naive way to do it, one could take multiple small steps away from the solution in various directions of the weight space and evaluate the cost. Assuming a 3d weightspace, this would be like projecting a grid onto it from the z-direction and taking a measurement within some distance from the solution at the intersections.
We could sum the squares of the differences in costs or sum absolute values, and compare that against the differences in train cost vs validation cost.
We could then do two things:
See if there are certain training methods that tend end up in less spiky areas.
More interestingly, see if indeed less spiky areas generalize better.
I wonder what would be a good dataset to experiment with this. I would be inclined to use the MNIST, but not sure if it is not too simple? BTW I started playing around with FashionMNIST and I think it is generally perceived to be harder, but I do not know much about it.
Either way, I would be interested in working on this Sounds like a really cool idea to explore.
@radek My understanding is that. Annealing (w/o the cyclical learning rate concept) is trying to guess when to decay and by how much to decay the learning rate while Cyclical learning rate is more about stability of the minima.
Lets say we are in a ravine (we dont ‘know’ how spiky it is). If we keep returning to the same path after the cyclic jumps, it means this is quite stable. If we jump around, that means we are exploring other ravines that may be more stable. My view is that this cyclic jump behavior is orthogonal to the general purpose annealing and both techniques can be used?
Note that in the course we’re not using cyclical learning rates (CLR), but SGD With Restarts (SGDR). SGDR seems a bit better in my limited testing. We’re using the idea from the CLR paper for how to set learning rates, however.
I ran an experiment and wrote a blog post looking a bit more closely at this.
There is also an accompanying repository on github with reproducible code (reproducible == open in jupyter notebook and do ‘run all cells’ )
I didn’t find what I was looking for which is a bit of a let down but I think there are nice ways to take the experiment further if anyone would be so inclined. This was genuinely fun to work on so I would be tempted also to look at this sometime down the road if time permits.
I also found it quite hard to do some of the things I wanted to do (for instance, looking at gradients) in keras. After just a day of playing with pytorch I can see how it make non-standard things much easier.
Very interesting @radek! What other approaches to measuring “spikiness” might be worth trying? Or could you intentionally create some very overfit and some with SGDR etc to have a bigger variance of results to test?
@jeremy - once again you provide me with some very good food for thought I started typing a reply but I need to think a bit more on the points that you make.
I now see that overfitting might be the way to go. I think I have a design of an experiment in my mind based on this idea that maybe could work quite well.
Doing this in keras is no fun though - I might be wrong, but I think its moving weights to numpy, applying deltas and moving them back to the GPU to reevaluate the model that takes forever. I wonder if the experiment can be run fully on the GPU using something like torch.rand. Possibly also switching the dataset to something like fashion MNIST or CIFAR-10 might also be a good idea - that might be another way to increase the variance.
I posted this on the blog thread but just saw this thread - so the conversation may be better done here. So moving that post here.
I read the post but did not understand it.
Here are questions:
You trained 100 different simple NN on MINST. What is different in each of these NN?
You say ‘achieving an average of 94.5% accuracy’. Is that average accuracy across these 100? Were all around that number or a large variance?
I understood that now you randomly changed weights and measured resulting loss and compared against previous loss. You took 20 measurements of such change in loss per model. How did you combine these into one number? mean square difference? Absolute sum? % abs change in loss?
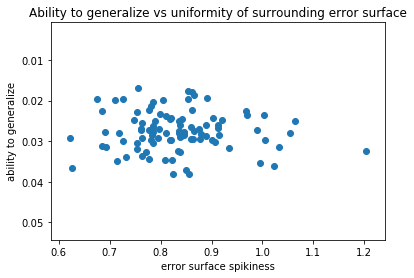
In the end I don’t understand the graph. The x axis could be the computation in 3 which could be measure of change of loss for small change in weights - so spikiness. Right?
About the experimental design, a couple of ideas crossed my mind (just discard them happily if you find them useless or if have already considered them):
I think your design can be valid, but maybe tricky to implement. First thing I would do: I would compare the NNetworks making sure that they have the same, or very close initial validation error.
Second thought, the more complex a Network is, possibly the more complex its error surface. Maybe one hidden layer is not enough complexity, even it the experiment main insight is simple you need complex surfaces!
Third thought,the scale of the weight distortion is essential. Even then, you dont have that many data points, your chart could well be a part of a bigger chart, possibly even with such small data you get positive or negative correlation number, even if not statistically significative.
So, in few words, very nice post and, if you find the time, I would not throw it to the trashbin yet, not without trying some more little ideas like the ones I gave. Maybe you are already there, you know, I wouldnt be in a hurry to draw conclusions yet.
By the way, am I the only one who sees an slight negative slope in @radek 's post chart? Maybe my eye is tricking me… but consider myself good spotting chart patternts. My bet is that you already have negative correlation coeficient. If its the case… well you had 50% chances but still I would persevere a bit tuning the experiment and adding more cases!
You trained 100 different simple NN on MINST. What is different in each of these NN?
The all share the same architecture, but the weights are initiated randomly - they converge to different solutions after the four epochs. In the weight space, after the training is done, they all end up in different spots.
You say ‘achieving an average of 94.5% accuracy’. Is that average accuracy across these 100?
Yes, this is correct - this is just an arithmetic mean of the 100 accuracies.
Were all around that number or a large variance?
Yes, the training is very effective - they all were relatively close together though I do not have any numbers that would describe this. The magic - or should I say science - of batch normalization and adaptive learning rates (both will be covered very soon in this course I think) continues to amaze me.
I understood that now you randomly changed weights and measured resulting loss and compared against previous loss. You took 20 measurements of such change in loss per model. How did you combine these into one number? mean square difference? Absolute sum? % abs change in loss?
I ended up going with absolute sum.
In the end I don’t understand the graph. The x axis could be the computation in 3 which could be measure of change of loss for small change in weights - so spikiness. Right?
Yes, you are right - this is the number I obtain in step number 3 by taking 20 measurements for each model and combining them via sum of absolute values. But what is y axis?
For the y axis, the ability to generalize, this is the difference in loss on the train set and the test set. All those numbers were positive - the greater the difference in loss, the lesser the model’s ability to generalize.
Wouldn’t gradient norm give an idea if we land in spiky or flat region ? Given 2 models with similar validation/training losses, would it be a good idea to pick the one with lower gradient norm ?
Yeah, I think that is what we are doing here and we can’t all be right all the time or else no learning would be happening So I guess we are on the right track here
Cool question from you imo and an insightful reply from @jeremy
BTW. this led me to thinking - we could possibly use the norm of the gradient to figure out if we have converged as opposed to staring at the loss and thinking whether we are there yet In reality, probably using the loss is still better instead of using a proxy… but then maybe not necessarily? Maybe with adaptive learning rates the gradient that is an accumulation over many batches carries some interesting information that the train loss on a given batch doesn’t contain?
Well, sorry, don’t mean to get ahead of myself but through the question that you asked @ravivijay I definitely learned something new so thanks for asking
Cool. My question stemmed from recent video from Ian Goodfellow, https://www.youtube.com/watch?v=XlYD8jn1ayE&t=5m40s at 5m40 seconds, he says that even though loss might go down, gradient norm may go up. He says it’s fine and expected in DNNs, but I thought it might be worth digging more while relating to this question.
Thank you @ravivijay This is an amazing talk. I came across this linked on Twitter but someone only linked to the part on numerical stability (which btw are great 20 minutes to invest into watching when someone wants to start using pytorch and hasn’t done low level computations in quite a while - I had quite a few bugs in my first pytorch implementation that were ridiculous once spotted but this talk definitely would have helped!)
With regards to the part that you link - wow! I do not think that Goodfellow ever explains why that is the case that the gradient doesn’t start approaching 0. I mean, I get it that we do not get to a minima in a mathematical sense, but I would expect the gradient to at least start falling a bit! Instead, we seem to accumulate the gradient as training progresses and then its magnitude levels off.
This is very interesting. I think this effect of gradient norm not falling has also to do with the training algorithm used, but it definitely raises interesting questions about the weight space. I wonder what would happen on simpler examples or if there is anything relevant about where we arrive in the weight space based on what happens to the gradient norm. And what would happen if I continue to train but with smaller learning rate?
Through @jeremy’s comments that left me thinking about this qutie a bit, I started working on a continuation to the first medium post, and here are a couple of relevant sentences I think that would be not something I would write a week ago but this is a distinction that I think I now was able to make:
What is a minimum? From a mathematical perspective, this is a well defined term. But from the perspective of a practitioner a minimum is a spot in the weight space that our training algorithm reaches when the network is fully trained and is unable to significantly improve upon via further training.
Have a couple of experiments in mind but they are probably a couple of weeks away - still not even done with lecture 1 to the extent that I would like to be.
Anyhow - sorry for rambling. What you linked to is very relevant and very interesting. Thank you.

 )
)
 - of batch normalization and adaptive learning rates (both will be covered very soon in this course I think) continues to amaze me.
- of batch normalization and adaptive learning rates (both will be covered very soon in this course I think) continues to amaze me.