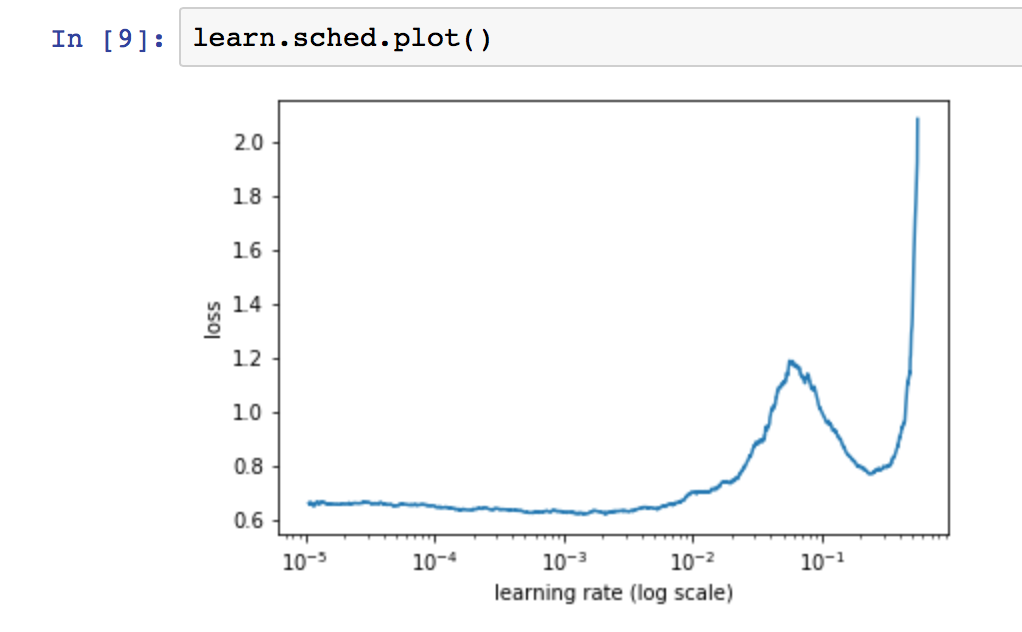
I think of Learning Rate finder as helper to find the best (largest) learning rate. I have seen curves like this in my own tests. Because the model might be over-correcting and loss increases when training from 0.01 to 0.1, I would tend to prefer a smaller learning rate of 0.001 to start with. The loss is also relatively small to begin with, so it makes sense to have a smaller learning rate.
Would be interested in learning more about how others would approach this.
From your graph, you can see that as we increase the learning rate past 1e-3 the loss starts to increase. As we want to minimize the loss, we should pick a point in the vicinity of the minima. To be on the safer side, we choose a point slightly less than the minima. So, for the above case, I would choose 1e-3 or 1e-4.
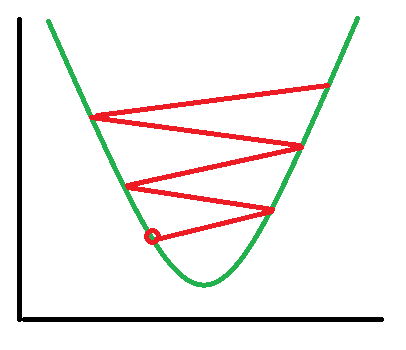
In training deep networks, it is usually helpful to anneal the learning rate over time. Good intuition to have in mind is that with a high learning rate, the system contains too much kinetic energy and the parameter vector bounces around chaotically, unable to settle down into deeper, but narrower parts of the loss function. Knowing when to decay the learning rate can be tricky: Decay it slowly and you’ll be wasting computation bouncing around chaotically with little improvement for a long time. But decay it too aggressively and the system will cool too quickly, unable to reach the best position it can.
Source: http://cs231n.github.io/neural-networks-3/#anneal
Too high a learning rate and you risk missing the weights for which the network fits best.
Souce: @timlee
Too low a learning rate, it will take a lot of time to find the best weights.
Thanks for the reply. I went with 0.001 based on my intuition. However, I am still quite not able to understand why would the loss increase and the decrease? Has it found a local minima?
Am I completely wrong in thinking that there is a relationship between learning rare finder and minimas?
I also see that sometimes. It’s very curious! I think that there are other “flat spots” it finds - for instance maybe setting “all zeros” or “all ones”.
I hope not to say stuff which is trivial to you, I don’t know your background.
The error surface for a loss function is not only nonconvex, but also:
Very bumpy
Very high dimensional
The bumpiness does mean that if you select a very small learning rate (and/or a weak momentum), it won’t be able to jump out of shallow local minimum.
Its high dimensionality (millions of dimensions if you consider a model like vgg16, just to name one) does mean that you would almost certainly be wrong should you try to infer qualitative considerations using your intuition over an example 2d error surface immersed in 3d space.
The only tool which can provide reliable informations about such minima are the eigenvalues of the hessian. It is unpractical (and even infeasible) to routinely use such monster hessian (let alone doing its eigendecomposition) for deep learning, but you could try it if you want to gain a better qualitative understanding of an error surface relative to a small model.
More literate users will hopefully correct me if I’ve been inexact.
The way this learning rate finder is implemented in fastai is simply as a learning rate scheduler that slightly increases the learning rate with every mini batch. It stops training when the loss suddenly becomes a lot higher.
When you get a plot like the above, I’m curious if you would also get a similar plot if the learning rate was not increased on every mini batch but only every 10 or so mini batches. Or what if you tried this with a larger batch size?
In other words, I’m wondering if it is the stochastic nature of the mini batches that is responsible for such a curve?
Source: an article by Carlos Perez. I saved the pic yesterday, but I don’t remember the page address. Search for the paper (and read it if possible) and you’ll find the article, too.
Nice! That does show things becoming smoother with a larger batch size (as is usually the case) but the curves still follow the same general shape. Only when the batch size becomes really small (8 or 4) is there an additional peak.
You know what makes me feel a bit uneasy when studying deep learning? It’s like being a caveman experimenting with fire prior to any knowledge, even rudimentary about the physics of combustion. And this happens even in the academia.
Take Smith’s paper for example. It’s very interesting, and it shows useful experimental result. Still, it is pure experimentation at blind, indeed.
No theoretically grounded results are shown. No further insights about the topology of the loss surface are obtained
In their conclusions, the authors write:
Furthermore, we believe that a theoretical analysis would provide an improved understanding of these methods, which might lead to improvements in the algorithms.
That’s the way to go, in my opinion. Yet, I searched for them and found little or nothing, although something exists (also by Smith) about the forementioned topological insights (in a rather slacky sense, though).
That is how pretty much all technological progress is made. Contrary to popular belief, the science comes after the engineering and the engineering is usually trial-and-error.
It would be great to have a better scientific understanding of how deep learning works, and academics are trying hard to come up with such theories, but in the end the only way to gather enough understanding to create such theories is by doing a lot of getting-your-hands-dirty experiments.
It’s a cyclical process: the engineering begets the science, which informs the engineering, which improves the science, and so on.
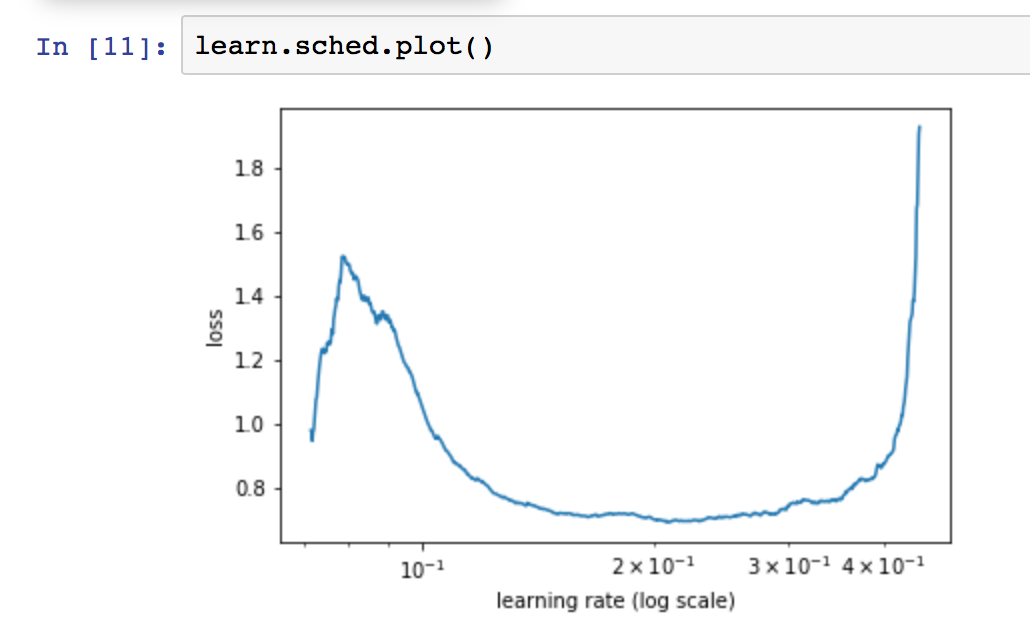
I ran the learning rate finder again after a few training epochs and the graph is shown as follows:
In the lessons, I understood that we choose the steepest point right before the flat point. Since there is no descending line, does this mean I can use any learning rate up to 0.01? Thank you in advance.
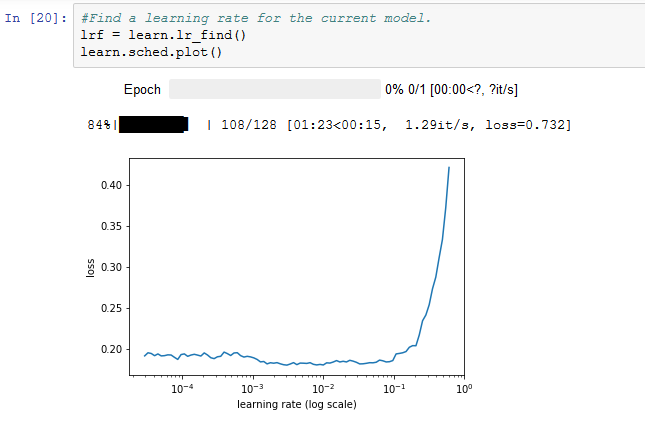
From my experience, if I tried various learning rates (and all other variations) and I still could not train the model properly. I will try different architectures and optimizers. I understand I don’t answer your question. But, it may be the way to move forward. It is part of the journey.