In lesson 5 (collaborative filtering), I don’t understand the meaning of “y=learn.data.val_y”, what is it expressing?
I see it’s an array with values related to the validation set, but different to predictions and ground truths.
In lesson 5 (collaborative filtering), I don’t understand the meaning of “y=learn.data.val_y”, what is it expressing?
I see it’s an array with values related to the validation set, but different to predictions and ground truths.
It is your target value (dependent variable) for your validation dataset (e.g., what you are trying to predict).
It should be the ground truth on the validation set. Also, I find it quite useful to think about what the notation entails:
learn.data.val_y
Learn is the learner, it is an object that combines a model and datasets. The learner references (or consists of) multiple objects and variables that can be accessed via the dot after its name. So on a learner there exists something that is data and that in turn references something that is val_y. In case you would like to figure out what each of these are you could do something like type(learn.data). BTW to trace back what lives in the data.val_y you could scroll up to where the learner was defined. At some point it had to have the validation set assigned to it as it doesn’t come built in with one.
So this:
y=learn.data.val_y
is just and assignment of whatever lives in learn.data.val_y to the y variable.
Sorry if this is not something that is useful to you as maybe you realize all that but still thought I would type it out as maybe it will be useful to someone who ventures into this thread 
Hi, thanks for the detailed explanation.
My question boils down to why are these two last columns not equal?
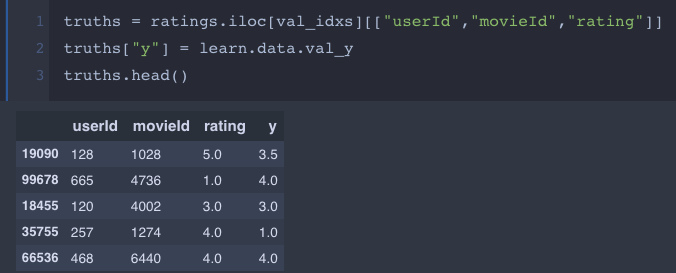
I just filtered the rows from the input dataframe that correspond to the validation indexes and concatenated learn.data.val_y column.
Probably to help you I would need to have access to a computer with the data and the notebook, which I don’t at the moment.
There are a couple of things you could try though. Try passing just an array with a single id to the method that gets us the learner:
learn = cf.get_learner(n_factors, val_idxs, 64, opt_fn=optim.Adam)
and see what comes out.
You could also read in the data directly from the csv file that is passed to the class method that creates the collaboration filtering data object:
cf = CollabFilterDataset.from_csv(path, 'ratings.csv', 'userId', 'movieId', 'rating')
This way you could be sure that what you have stored in the ratings dataframe is in the same order as the data that lives in the ratings.csv
You could also play around with the dataloader or even go as far as get all the batches and look at the indexes. This should allow you to iterate over the entire val set batch at a time:
for batch in iter(learn.data.val_dl):
-> do something interesting to batch here :) it will be a tuple so you might need to figure out what lives in the first and the second slot
Sorry I can’t be of more help atm. Maybe the troubleshooting steps I list above will be able to cast additional light on this.
@radek I’m having the same issue with my data.val_y labels not matching the actual CSV labels
I tried your suggestion of passing just a single Id for val_idxs to the learner object
In the CSV, the label for image 1 is the integer 38
From the validation dataset, the label appears as 60 instead of 38
Figured it out. Looking at the source code for from_csv, it looks like there’s some sorting going on which rearranges the label ordering. What we’re getting is the one hot index.
Using data.classes(data.val_y) will map to the correct ground truth label in the one hot encoding array
HI i am having the same problem but when trying out data.classes(data.val_y) I am getting an type error