I’m late to the discussion but for @radek, @sermakarevich, @jamesrequa et al. who are interested in Kaggle competitions as a mean to explore and learn more, here’s a course you may consider after DL Part 1 V2, ML1 V1 and before DL Part 2 V2
You could audit it first, go through the lectures and then start the free trial once you’re through with the lectures if you want to avoid the 15 day waiting period for the financial aid acceptance
Everyone has a plan until they get punched in the face.
meaning that our plans often don’t stand a chance when confronted with reality. And so has the situation been in my case.
Jeremy shares so much great information and it is coming at such a pace that even if I were to spend all my waking hours only on this course, I wonder if I would be satisfied with my progress .
As is, there are so many things I would like to try out and look into that I feel I am doing the bare minimum and still am not caught up with recent lectures.
Someone needs to get into a time machine and slap some sense into Radek from a couple of weeks ago! How was that plan even remotely narrow? What definition of laser focus is that?!
Let’s say my definition of laser focus evolved and it entails: much less time reading, much less time watching, much more time coding.
Attempting doing this might have been my biggest mistake to date in this course, or a touch of - deranged but still - genius. The jury is still out
(This relates to the project I describe here - essentially implementing the training loop from scratch, building functionality to work with models, etc. Learning a lot of PyTorch / Python which is good - maybe - but at the cost of doing actual deep learning)
First part is done, box is up and running, second part - not sure if worth pursuing any more given how little time is left. Even if I were to figure out how to train on the 50 GB of data, I doubt this would get me very far in the competition. Too little, too late.
Failed on that one miserably numerous times.
I might be getting there
In summary, I think I am learning a lot and am potentially moving at the highest pace that is still relatively reasonable. As I get to only be me and not someone else, whether I would be better off if I were a better programmer / knew more Python / PyTorch to start with - probably, but none of this is an option, and accepting that I have to learn things that might seem very simple is the right way to go.
Would I be better off if I didn’t jump into peeking behind the curtains and used higher level functionality vs putting things together myself? Maybe - but if this is the case than this is a lesson I still haven’t and need to learn. I already have come a long way since watching the first lecture with Jeremy and it is probably hard to imagine what a hopeless theoretician I was back then (especially that going the theory route without practice is the easiest way to go astray, but what else to do as no other resource as far as I know bridges the gap between not knowing and doing as this course).
As is, approaching this as a marathon is the best I can do. Willing to go at this full speed for the next couple of months as I honestly feel I finally am devoting my time to the things that matter, I have a relatively okay-ish handle on learning. If doing so leads to nowhere apart from me learning something I always wanted to learn - which I feel is by far the most likely outcome, then be it.
This is not even close to top 10% and as my data center AKA my parents house gave out (power outage till evening at least) this is likely going to be my final submission
A simple voting ensemble I somehow remembered reading somewhere about and cooked up quickly in the heat of the battle. 4 models - the best being densenet201 achieving ~0.62 on the LB. Trained only the classifier part
Above all, despite the relatively poor results, taking part in this felt really good and I had a lot of fun
Here are the main lessons I learned:
Always start with completing a full pass all the way to submission as early as possible. What I mean by this, is that it is extremely crucial to have a bird’s eye view of everything that you will have to deal with. You cannot assume things - likely this activity will uncover quite a few things you have not anticipated and that might be harder to deal with (or impossible) to deal with effectively if you sink a lot of time into perfecting the earlier stages of the pipeline.
It’s all about IO with datasets large relative to your HW. Just reading the 200GB of data of my HDD takes I believe over half an hour! If I ever again work on something this size, I will want to put some serious thought into RAID0, getting an SSD, more RAM, ways to preprocess the dataset, etc.
Frequent the kaggle forums especially for the competition you are taking part in! Such high quality posts in there and a lot of good pointers how to attack a problem!
All in all, I find that working on this was time well spent But I feel it is important to not lose momentum. Would love to participate in the icebergs or the favorita competition, but the wise choice is probably revisiting collaborative filtering, coding up those RNNs and rewatching lectures So this is the direction that I will try to point myself in
@radek I stumbled upon this post today and I can totally relate. Good job on tracking what not to do.
I have been keeping track of learning priority list(not super organized but hard to focus without having one). Generally, I am alternating between time blocks of learning to blocks of doing. The only thing I would say is to treat it as a marathon and update your plan as you learn what else you need to learn Would love to follow how your plan is going.
I tried keeping a list as well a couple of times, but I would quickly fill the list up with a lot of things I thought were essential but really weren’t. Now I just keep a mental list of what to work on - this way I naturally revise what is on it by trying to remember it. I am unable to have too many things on it (usually one or two ) and things naturally fall off it without me even noticing
I have two little kids and a full time job as a rails dev (complex, legacy app) and my recent realization is that I have been going at this deep learning thing too hard. I should not be staying up till 2 AM and this combined with the observation that it’s rarely the issue that we genuinely do not have enough time but rather that we give time to the wrong things means I have to make some deeper life changes hopefully sooner then later
It seems quite obvious at this point that data science related things is what I want to do to greater or lesser extent in life, one way or another. Something strange is also happening through a couple of months of following Jeremy’s and Rachel’s advice very closely - I feel with enough time I am capable of tackling nearly any problem at a level that I think could be quite useful to potential employers. Not sure I have enough to show at this point to convey this to them though and also not fully convinced that doing this professionally at this point would be the way to go.
But I digress - I am currently working on making a deep learning submission to the favorita kaggle competition. Another lesson learned - I will not join a competition in forseeable future just a month before it finishes! Too little time to get to anything fun, okay-ish for learning but not compatible with my schedule at all. 11 days to go only so would like to finish this. I then have a couple of posts I already started that I would like to complete, including beginning a lessons learned from fast.ai lib series. I feel that those posts can be quite good so excited about getting them done, and at least writing down what I want to write and getting it out the door finally will be a good thing
And that is it really as for my plan. Once I make progress on those posts, I will either hop into a new kaggle comp if one launches, or will focus on finishing v2 lectures, or will write more posts including something fun on random forests, or will read the pandas book (Santa got me it for Christmas ) or the DL book by Chollet (I really liked the first couple of pages) - most likely will do some combination of the above sticking 98.9997% to fast.ai materials :). There is still the lin alg course I wanted to do. the 1.0003% of time will be given to reminding myself what works and not straying away too far as there are still so many fast.ai goodies I haven’t taken a closer look at.
As a side note (I think a lot of people might find this useful), there is this great podcast episode with creator of Ruby on Rails, David Hainemeier Hanson. He has a lot of good things to say about productivity and learning, I think I should listen to it again He highlights the value of uninterrupted code sessions and turning down noise in general. I got off Facebook entirely and I am amazed how much can be achieved via giving something uninterrupted attention for some period of time. Need to figure out how to use Twitter better (maybe unfollow a bunch of people / don’t randomly jump into reading it but check it a couple of times a day from my computer only). But a lot of good stuff there from David, would highly recommend this talk and in general his approach to programming (very welcoming to people new to coding and in general from various walks of life, have benefited from listening to him greatly myself).
Sorry about this disorganized post - will try to write a more coherent update speaking directly to the plan I outlined in earlier posts and how it is going sometime down the road, maybe once I have more to show in terms of posts, etc
Kids are slowly waking up so time to get the older one ready for kindergarten and in general get things going around here
The battle was valiantly met at the favorita grocery hills where the armies of general Radek suffered a spectacular yet painful defeat!
I ultimately finished 1117th.
So many lessons learned from this competition - most surrounding the process of approaching a machine learning problem and the data processing part rather then the model construction itself.
The fact that Kaggle launched the new data science bowl competition just now has the potentiality of messing with my plans, but I think I’ll take it very slowly with it and will focus on test driving my general approach and playing around with ensembles.
The main focus going forward will be on working through Pandas for Data Analysis. I also will stat publishing blog posts about what I learned from studying the fast.ai library - have a couple already nearly finished and ideas for more.
It is quite easy for me to post here on the forums since this is quite a friendly space where I feel at home, but for various reasons probably I find it not so easy to tweet. I would like to change that and so I am starting my very own 100 days of Twitter challenge where each day I will tweet something and will comment on someone else’s tweet. The timestamp on this post will serve as a nice way of checking how many days have elapsed
Oh yeah - and if I ever post anything to these forums, which knowing me I most likely will I will strive for conciseness. This is another dimension along which I feel I should improve.
good luck! writing concisely is difficult - i used to write tech doc for a living and those rules from Altucher really helped me: 33 Unusual Tips to Being a Better Writer
I tried reading the first edition of Pandas for Data Analysis, didn’t like it much - I prefer Python Data Science Handbook by Jake VanderPlas. It’s available free online, together with accompanying jupyter notebooks Python Data Science Handbook
I have Chollet’s new book and have read first 5 chapters so far. its a good book with some useful tips. however most the content is already covered in this course.
I think he is not a native English speaker, his explanations at times need improvement.
PS: He uses Keras so the code from book cant be directly if you are using Pytorch.
Great materials there @malrod - thanks for sharing I also found the v1 of the Pandas for Data Analysis not that easy to follow, but v2 is much, much better.
Adding the materials you shared to my mental todo list.
I only started reading it on my mobile phone when I have a bit of downtime (like carrying my toddler around ) - it tickles my brain in a nice way and I like the way he introduces various concepts.
Really well written and I enjoyed his insight from the intro chapter how a deep learning model is essentially a successive transformation of data into more and more useful forms.
Thx for the feedback @cynosure - wonder if the next chapters will make me like the book less or more
Thanks for the feedback- maybe I’ll give that new version of Data Analysis book a try.
As for Datacamp - don’t put it on a wait-list You can squeeze it in-between more serious stuff. Exercises are divided into self-contained segments, so any time you have 10-20 minutes of free time, you can dive in. Unless you find such format of learning tiresome (there is a lot of hand-holding and it gets boring after a time) - it may turn out you’ll hate it after first 5 minutes
And I also join the fanclub of Chollet’s new book. I just finished chapter 6 on working with sequences. The material was all new to me, but the explanations were excellent. And the content seems indeed the same as covered on fastai part1 (I only watched the first 4 lectures). I hope this approach to teaching DL gets more popular - teaching DL using python instead of showing equations on slides is still a revolutionary idea.

 It will not give you a sticker at the end, but you get all the knowledge!
It will not give you a sticker at the end, but you get all the knowledge!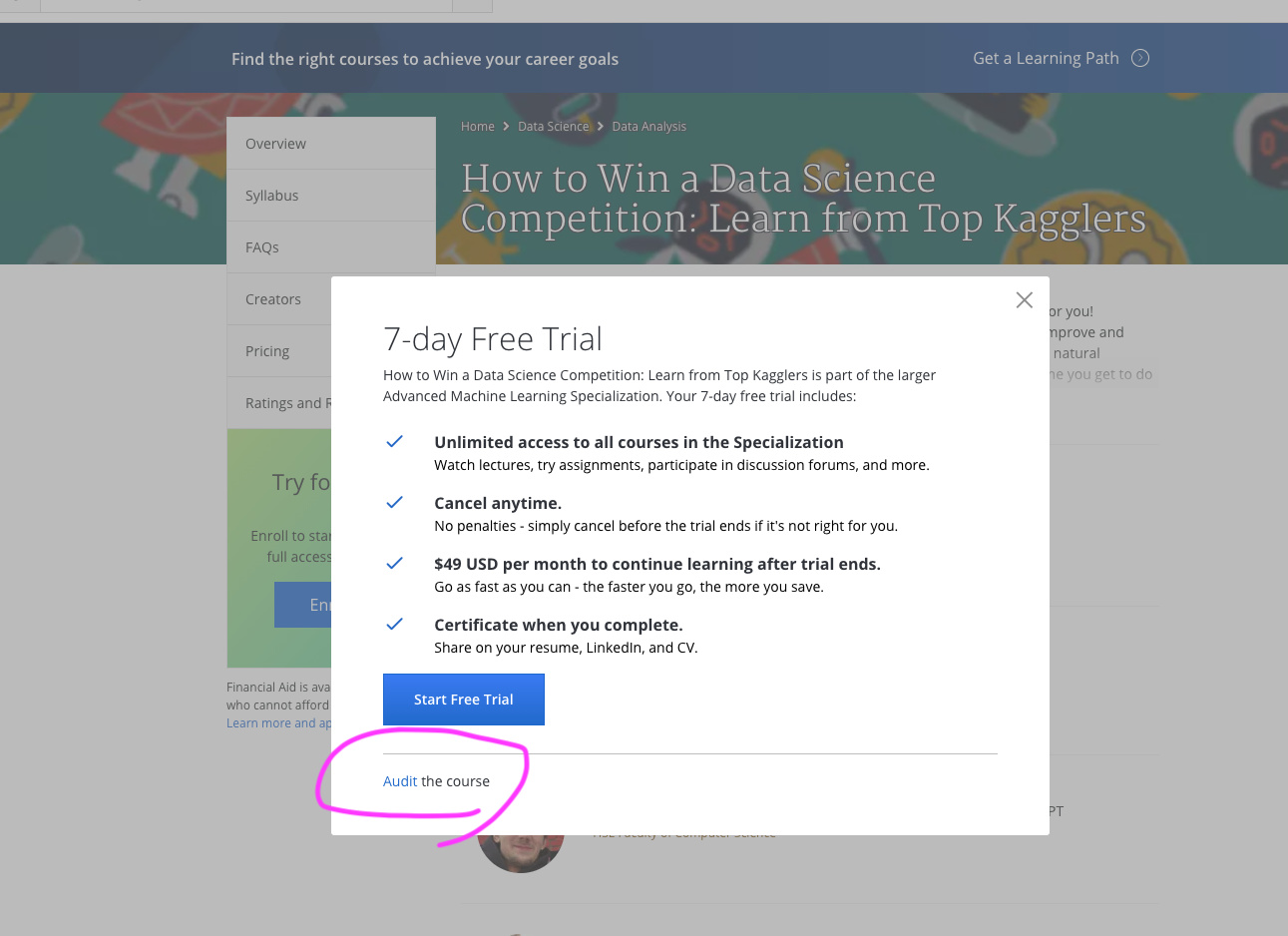
 I wonder how
I wonder how  ?
?