Can you share the benchmarks here? I’ve got the USE benchmarks. Maybe we can make a repo comparing performance of fine-tuned models on a range of commonly used NLP datasets.
Yes, I haven’t started the LM backed classifier yet. I’ll share the results as soon as possible.
That’s correct.
I’m looking at both cosine similarity and the combination of cosine similarity and CE.
Exactly. So while the model’s perplexity is somewhat lower the accuracy of word prediction is slightly higher. It’s hard to tell if that’s directly resulting from the alternative loss function or not. I’m still working on improving the loss by eliminating the possibility of mode collapse.
1 Like
So…as I’ve been reporting, I tried a couple of ways we could improve the results in the Quora notebook. I tried 2 things:
- Commutating columns to double the dataset
- Add additional uni-directional GRUs layer to provide alternate pathways for our gradients to flow(ala resnets)
Finally I compared gereral semantic evaluation results and checked how we performed specifically on the Quora set(we don’t do well).
All results are here:
Though the results are not great, I have a better idea of the problem I’m up against. I hope to work on the real LM backed STS task next.
I was getting 0.38 with USE + 3 layer FCN. The vanilla embeddings with FitLaM were only obtained by training on wikitext and are expected to not have a good understanding of question structure. In your notebook it isn’t clear if you finetuned the LM or not before the classifier backbone. If not, then that should hopefully improve performance.
1 Like
Wait…you used the LM backbone or only the weights from the embedding layer?
I’d used the Transformer model from Universal Sentence Encoder for getting the vector representations of sentences. I was relying on you to provide the FitLaM comparison 
1 Like
Oh USE = universal sentence encoder!
Got it.
Will post results soon…I’ve been busy at work…
Can you share your code please? Do you have a colab notebook?
I took the embedding weights not only after fine tuning but also further training the imdb classifier. I suspect it’s the objective I was training for, that messed up the Quora specific log loss.
Sure, just in the process of documenting the notebooks. Will share the repo and data soon.
BTW, did you mean 0.3 validation loss or test loss with the universal sentence encoder?
I thought you made a kaggle submission with the test set(which is massive compared to the train set) and got a 0.3 NLL.
I meant validation loss. Here’s the link to the GitHub repo: https://github.com/RudrakshTuwani/transfer-learning-quora. I’m yet to commit code for Neural Network baselines on USE. It’s really a work in progress as of now, and you should probably look at it after 2-3 days.
In case you’re interested in playing with the USE embeddings yourself, the link to numpy arrays along with custom dataset and dataloaders are available in the ‘Universal Sentence Encoder’ notebook.
1 Like
Lovely! Thanks man.
1 Like
Did you try using both arccos and cosine sim and find any improvement with arccos?
Yeah I did, there wasn’t any improvement.
1 Like
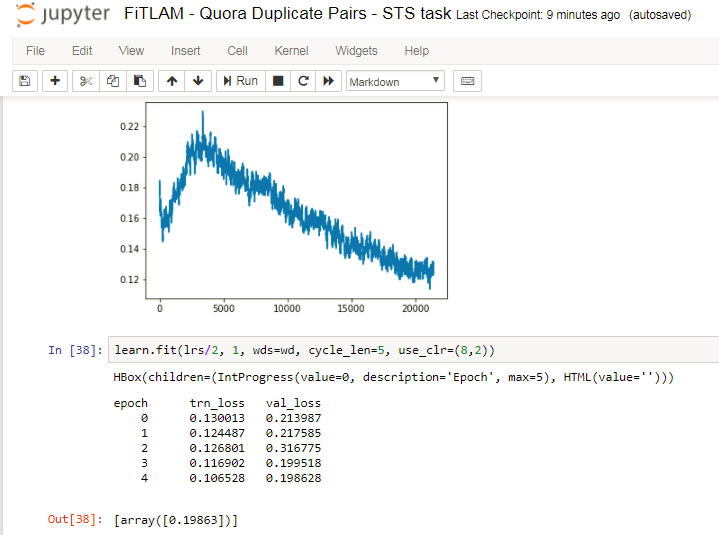
Ok…I have some news. After ditching all other methods, I found some time to work on the FitLam based model.
The kaggle Quora duplicates winner got log loss 0.11 after ensembling a gazillion models and feature engg.
Our FitLam single model with just a bit of training gives 0.19 straight out of the box! Holy cow!!
There’s still bidir, concat pooling and other stuff try! So when @jeremy and Sebastian say that FitLam is akin to alexnet, for NLP…it’s not to be taken lightly!
5 Likes
Note: the default methods in the fast.ai stepper class don’t allow for input X pairs/lists of unequal lengths. So I had to make a minor edits. let me know if you need more info.
1 Like
I’d be interested to hear what you did here.
1 Like
I actually took care of the bulk of it in my Pairdataset, if you see the notebook, under the section: Create dataloader for Quora classifier.
So in the stepper class, I modified the step and evaluate methods where self.m is called.
If len(xs) > 1 pass [xs] else pass xs to the model.
BTW, the validation set accuracy is 98.11% which I didn’t include in the notebook.
1 Like
And a question I’ve had in the back of my mind for a while now:
Why only 1 backbone?
What’s stopping us from having multiple FitLam backbones and let a custom head use an attention mechanism to “learn” how to effectively deal with them.
Then you can do:
learn[0][0].load(‘wikitext103’)
learn[0][1].load(‘imdb’)
learn[0][2].load(‘quora’)
It’s sort of like how they load the jiujitsu program into neo’s head in the matrix.
Are there any papers/projects where this is shown to work/not-work?
And finally, I was finding that slowly reducing BPTT from 70, the source model(wikitext103) down to 20, (mean + std.dev of Quora question lengths) helped with the training greatly. It was just a fluke perhaps, but it seemed like an intuitive thing to try - the LM model works harder to predict next word with a shorter input sequence…+ I was mainly trying to get bigger batches into the GPU. So, I am calling this bptt annealing.
Not sure if this is also worth pursuing, and if it has a proper name in the literature.
Seeking feedback from experts and @jeremy.
Thanks!
3 Likes