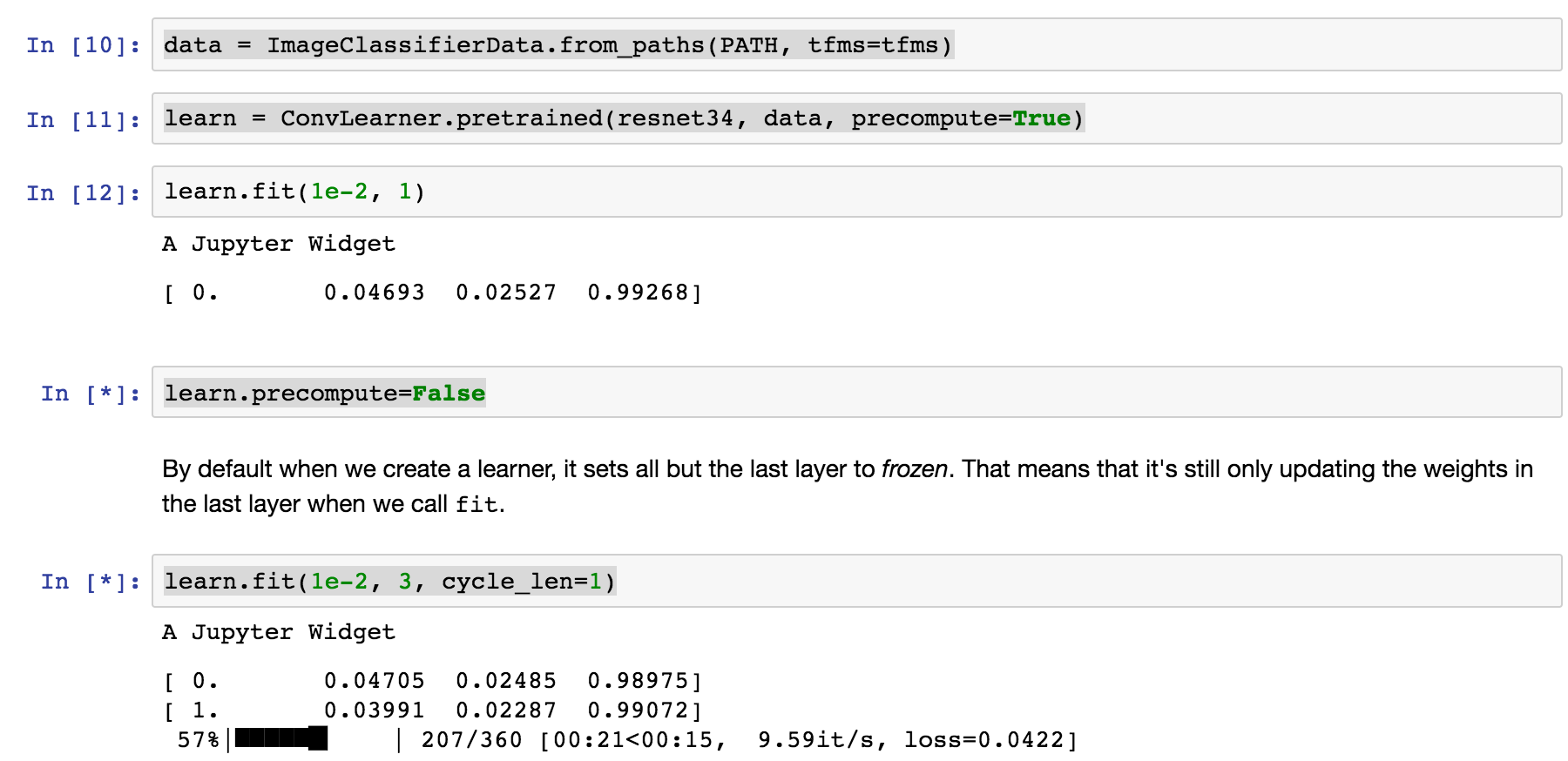
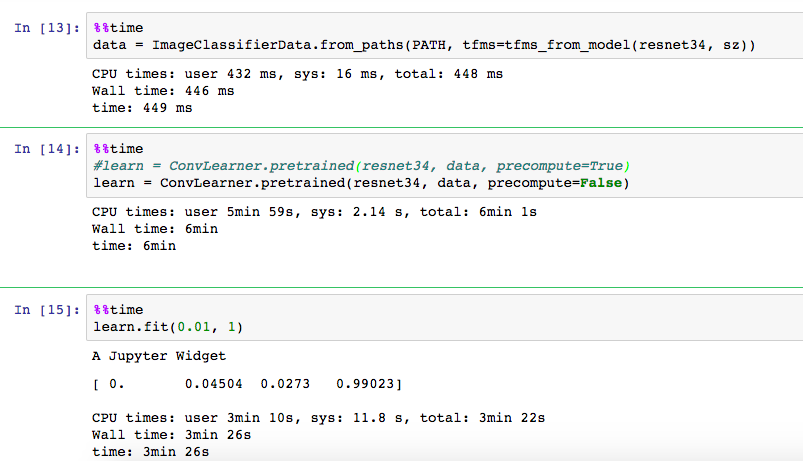
Hi Jeremy,
I am having a similar locking issue using the most recent version of the repo for lesson 1 notebook. I am using my own DL box with GTX1070 running on Ubuntu 16.04
For me everything in the notebook runs great as long as I have learn.precompute=True but once I try to run learn.fit(1e-2, 3, clycle_len=1) with learn.precompute=False then it locks up. See below is the traceback.
Any help you can provide is much appreciated!!
> ---------------------------------------------------------------------------
> KeyboardInterrupt Traceback (most recent call last)
> <ipython-input-40-5057ed0f08f5> in <module>()
> ----> 1 learn.fit(1e-2, n_cycle=3, cycle_len=1)
>
> /home/james/fastai/courses/dl1/fastai/learner.py in fit(self, lrs, n_cycle, wds, **kwargs)
> 98 self.sched = None
> 99 layer_opt = self.get_layer_opt(lrs, wds)
> --> 100 self.fit_gen(self.model, self.data, layer_opt, n_cycle, **kwargs)
> 101
> 102 def lr_find(self, start_lr=1e-5, end_lr=10, wds=None):
>
> /home/james/fastai/courses/dl1/fastai/learner.py in fit_gen(self, model, data, layer_opt, n_cycle, cycle_len, cycle_mult, cycle_save_name, metrics, callbacks, **kwargs)
> 88 n_epoch = sum_geom(cycle_len if cycle_len else 1, cycle_mult, n_cycle)
> 89 fit(model, data, n_epoch, layer_opt.opt, self.crit,
> ---> 90 metrics=metrics, callbacks=callbacks, reg_fn=self.reg_fn, clip=self.clip, **kwargs)
> 91
> 92 def get_layer_groups(self): return self.models.get_layer_groups()
>
> /home/james/fastai/courses/dl1/fastai/model.py in fit(model, data, epochs, opt, crit, metrics, callbacks, **kwargs)
> 83 stepper.reset(True)
> 84 t = tqdm(iter(data.trn_dl), leave=False)
> ---> 85 for (*x,y) in t:
> 86 batch_num += 1
> 87 loss = stepper.step(V(x),V(y))
>
> /home/james/anaconda3/envs/tensorflow/lib/python3.6/site-packages/tqdm/_tqdm.py in __iter__(self)
> 870 """, fp_write=getattr(self.fp, 'write', sys.stderr.write))
> 871
> --> 872 for obj in iterable:
> 873 yield obj
> 874 # Update and print the progressbar.
>
> /home/james/fastai/courses/dl1/fastai/dataset.py in __next__(self)
> 219 if self.i>=len(self.dl): raise StopIteration
> 220 self.i+=1
> --> 221 return next(self.it)
> 222
> 223 @property
>
> /home/james/anaconda3/envs/tensorflow/lib/python3.6/site-packages/torch/utils/data/dataloader.py in __next__(self)
> 193 while True:
> 194 assert (not self.shutdown and self.batches_outstanding > 0)
> --> 195 idx, batch = self.data_queue.get()
> 196 self.batches_outstanding -= 1
> 197 if idx != self.rcvd_idx:
>
> /home/james/anaconda3/envs/tensorflow/lib/python3.6/multiprocessing/queues.py in get(self)
> 341 def get(self):
> 342 with self._rlock:
> --> 343 res = self._reader.recv_bytes()
> 344 # unserialize the data after having released the lock
> 345 return _ForkingPickler.loads(res)
>
> /home/james/anaconda3/envs/tensorflow/lib/python3.6/multiprocessing/connection.py in recv_bytes(self, maxlength)
> 214 if maxlength is not None and maxlength < 0:
> 215 raise ValueError("negative maxlength")
> --> 216 buf = self._recv_bytes(maxlength)
> 217 if buf is None:
> 218 self._bad_message_length()
>
> /home/james/anaconda3/envs/tensorflow/lib/python3.6/multiprocessing/connection.py in _recv_bytes(self, maxsize)
> 405
> 406 def _recv_bytes(self, maxsize=None):
> --> 407 buf = self._recv(4)
> 408 size, = struct.unpack("!i", buf.getvalue())
> 409 if maxsize is not None and size > maxsize:
>
> /home/james/anaconda3/envs/tensorflow/lib/python3.6/multiprocessing/connection.py in _recv(self, size, read)
> 377 remaining = size
> 378 while remaining > 0:
> --> 379 chunk = read(handle, remaining)
> 380 n = len(chunk)
> 381 if n == 0:
>
> KeyboardInterrupt: