I have finished lessons 1 and 2 and am trying to apply what I learned on the Invasive Species competition on kaggle but I am stuck at approximately 62% validation accuracy.
To get some practice, I attempted to rewrite the vgg16 class. This is what I have:
import json
import numpy as np
from keras.models import Sequential
from keras.layers.convolutional import Conv2D, ZeroPadding2D, MaxPooling2D
from keras.layers.core import Flatten, Dropout, Dense, Lambda
from keras.utils.data_utils import get_file
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import RMSprop
vgg_mean = np.array([123.68, 116.779, 103.939], dtype=np.float32).reshape((3,1,1))
def vgg_preprocess(image):
image = image - vgg_mean
return image[:, ::-1]
class Vgg16:
def __init__(self):
self.PATH = 'http://files.fast.ai/models/'
self.create()
self.get_classes()
def ConvBlock(self, layers, filters):
model = self.model
for i in range(layers):
model.add(ZeroPadding2D(padding=(1, 1)))
model.add(Conv2D(filters, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
def FullyConnectedBlock(self):
model = self.model
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
def create(self):
model = self.model = Sequential()
model.add(Lambda(vgg_preprocess,
input_shape=(3, 224, 224),
output_shape=(3, 224, 224)))
self.ConvBlock(2, 64)
self.ConvBlock(2, 128)
self.ConvBlock(3, 256)
self.ConvBlock(3, 512)
self.ConvBlock(3, 512)
model.add(Flatten())
self.FullyConnectedBlock()
self.FullyConnectedBlock()
model.add(Dense(1000, activation='softmax'))
model.load_weights(get_file('vgg16.h5',
self.PATH + 'vgg16.h5', cache_subdir='models'))
def get_classes(self):
file_name = 'imagenet_class_index.json'
with open(get_file(file_name, self.PATH + file_name, cache_subdir='models')) as f:
class_dict = json.load(f)
self.classes = [class_dict[str(i)][1] for i in range(len(class_dict))]
def get_batches(self, path, gen=ImageDataGenerator(), shuffle=True, batch_size=32, class_mode='categorical'):
return gen.flow_from_directory(path, target_size=(224, 224),
class_mode=class_mode, shuffle=shuffle, batch_size=batch_size)
def finetune(self, batches):
self.model.pop()
num_classes = len(batches.class_indices)
for layer in self.model.layers:
layer.trainable = False
self.model.add(Dense(num_classes, activation='softmax'))
self.model.compile(optimizer=RMSprop(lr=0.1),
loss='categorical_crossentropy', metrics=['accuracy'])
classes = list(iter(batches.class_indices))
for c in batches.class_indices:
classes[batches.class_indices[c]] = c
self.classes = classes
def fit(self, batches, steps_per_epoch, epochs=1, validation_data=None, validation_steps=None):
return self.model.fit_generator(batches,
steps_per_epoch=steps_per_epoch, epochs=epochs,
validation_data=validation_data, validation_steps=validation_steps)
I attempted to repeat the steps used for the dogs and cats competition in my notebook:

When I use the class above to run the vgg code from lesson 1, it seems to do fine.
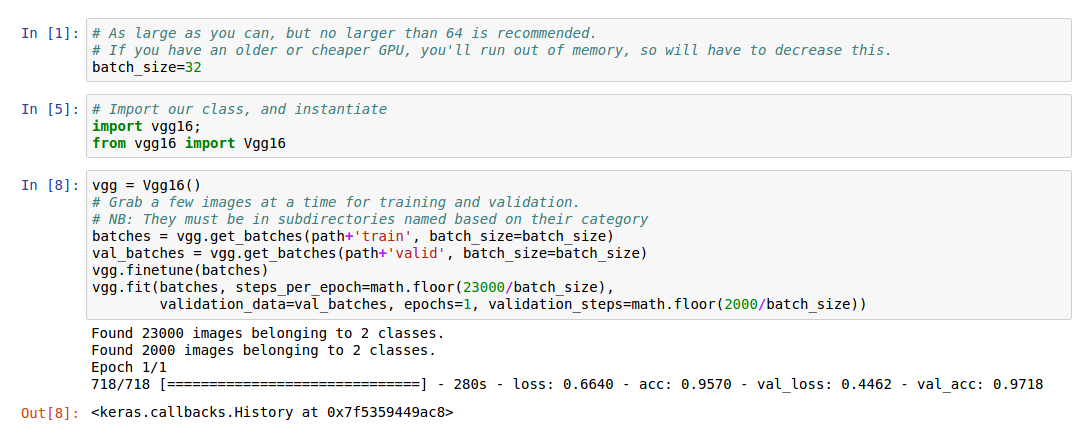
I feel like there is something big that I have missed. Any help is appreciated.