The training diverges once out of two, and you can’t use as high learning rates. I may have an explanation for that. The general idea of Leslie’s paper is that during the 1cycle training, we’ll get in a flatter area of the loss function and high learning rates will allow us to travel through it quickly. Flatter means lower gradients.
I got a training divergence the first time I tried it. I was using the LM notebook with Adam, basically exactly as in git, but trying use_clr_beta. Because I’m training something odd (sentencepiece model of misc source code), I’ve kept the learning rates low, in the 1e-4 to 1e-3 range, so this failed with a lr of 5e-4. I had just run an lr_find that was good until 3e-3.
I started playing with this a bit (thx for your help @sgugger on understanding some of the finer points ) and hope to give it a bit more time over the next couple of days.
The big news is that Leslie Smith published code for his last paper on github a couple of days ago:
It is caffe code and unfortunately is quite incomplete, but has some info that might be useful for reproducing results / experimentation. For example, it has the 3 layer model which I am planning on implementing and experimenting with.
I wanted to use this thread to ask other fastai users who used the 1cycle policy to share the situations where it worked and where it didn’t (or did less), so that we all get a better understanding on when to use it. In my (short) experience this works miracles when trying to make a model learn from scratch (as Jeremy proved in last lesson) but less so when you work with a pretrained model you want to fine-tune to a specific situation. In particular, I didn’t find good results (not as good as Adam with use_clr for instance) when trying to first train the added layer with a 1cycle, then unfreeze and train the whole network with another (using differential learning rates) but perhaps I did it wrong. What gave me better result was to train quickly the added layer then do a long 1cycle for the unfrozen network.
I’ve been playing around the last week trying to use it for better results on a Kaggle comp (iMaterialist Furniture) which takes 10+ hours per run. Unfortunately, I’ve not been able to use any of these innovations to improve against basic use_clr. If anything, it has been the reverse of your experience- 1cycle helps a touch tuning the last layer when frozen but performs worse than clr when unfrozen.
Little update on this.
I have been trying for two weeks to make super-convergence work on wikitext-2 (another small subset of wikipedia already tokenized by Stephen Merity and for which there is benchmark available) and it was working a bit, but not too much (and driving me crazy!)
I’ve finally figured it out and even if I’m still not in their 65.6-68.7 range for perplexity on a normal training my best is at 74 for now (I was stuck above 100 for the longest time). Though I use 120 epochs when they use 750. The key setting that changed everything was the gradient clipping. I had dismissed it at first but it turns out that in RNNs, it lets you get to really high learning rate (my best score is with a learning rate of 50 max!) without exploding.
I don’t know if it generalizes to CV or if it’s specific to RNNs, I just ran one experiment on cifar10 where adding gradient clipping gave me a slightly better result at the end (92.7% accuracy instead of 92.2% without, but it could just be random).
The fact it doesn’t get in the way of super-convergence is aligned with the idea I expressed in a previous post: in that period with very high learning rates, we are in an area of the loss function which is rather flat, with low gradients, so clipping doesn’t change a thing.
I’ll prepare a notebook with my best experiments but I’d really like to get to the SOTA result first.
I added the gradient clipping in my LM and it has straight away given 2% accuracy improvement. There’s almost a 3% improvement in the downstream classifier.
The language model seems to be giving out decent results (val.loss: 2.692, perplexity: 14.7742, accuracy: 0.5978). However, when I’m doing text generation, the results aren’t great. Maybe this perplexity for Telugu language is not sufficient to produce good results.
The bigger bad news is I’m unable to replicate my accuracies on the sentiment task. It’s way worser now although the language model accuracy has improved by more than 3 basis points.
The sentiment task val.loss is now more than 0.693 and that’s so depressing. There should be a bug somewhere.
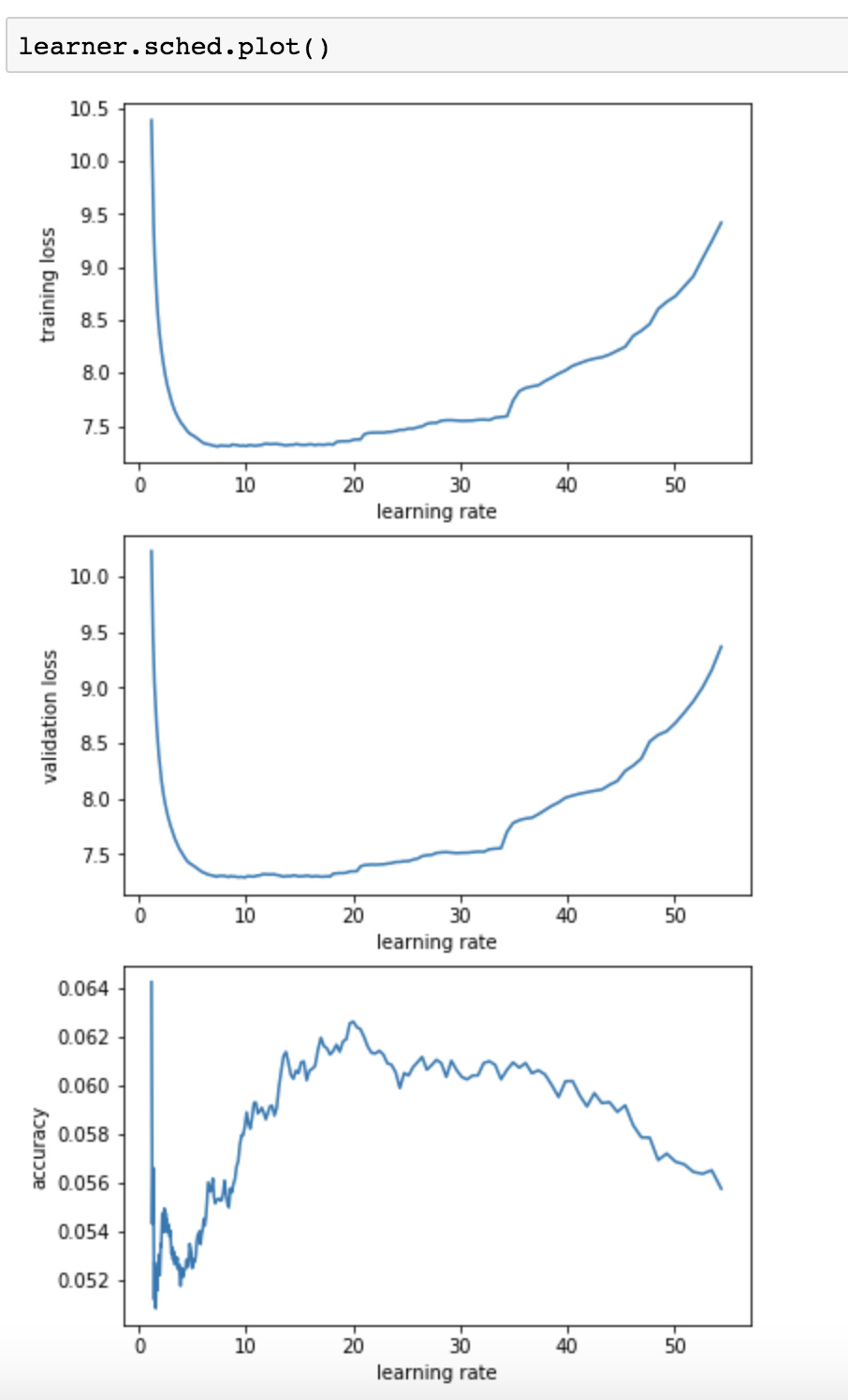
Trying lr_find2 on my language model. Can someone explain what the best LR would be based on these plots, and why? I still don’t totally understand how the LR finder works
 ) and hope to give it a bit more time over the next couple of days.
) and hope to give it a bit more time over the next couple of days.