. I’m trying to understand what this a_k(x) actually is and why do they say that x belongs to sigma and sigma belongs to the integer domain squared. Is it relevant for the implementation? Does someone has a better reformulation of this sentence: “`a_k(x) denotes the activation in feature channel k at the pixel position x ∈ Ω with Ω ⊂ Z^2”? That would help me a LOT!
Thank you.
You have k possible labels for each pixel in your M x N size image.
Each point x, i.e. {x0,x1}, where x0 is in [0,M) and x1 is in [0,N), or in other words x is in [0,M) x [0,N) (cartesian product) which is a subset of Z^2 (apologies for butchering mathematical notation on my phone).
So you’re calculating a softmax over all your channels for each pixel in the image. And your loss is crossentropy with ground truth segmentation for your image. Each a_k(x) is that channel’s output for that pixel before the softmax layer.
The x ∈ Ω with Ω ⊂ Z^2 stuff is math formalism that you can ignore. It just says that pixel positions are integers and x is a vector of such pixel positions.
A feature map is a 2-dimensional (grayscale) image that is the output of a single filter (also known as a channel) from a convolutional layer. So if your Conv2D layer has 32 filters then it produces 32 feature maps, and each of these feature maps has the same width and height. (Exactly how wide and tall they are depends on the previous layers etc. This is explained in part 1 of the course.)
The notation a_k(x) just says: the value in feature map k at the pixel coordinates given by x (which is a vector with 2 elements).
The softmax function they define here works just like the softmax you’ve seen in part 1, except that it is done for each pixel.
In a normal classifier you end up with a dense layer that outputs a vector of, say, 20 neurons and you take the softmax over those to get a prediction for each of the 20 corresponding classes. Here, however, you don’t want to make a single prediction for the entire image, but a prediction for every single pixel in the image.
So if k = 20 (there are 20 classes) then for pixel (0,0) you do a softmax over all 20 feature maps at coordinates (0,0); for pixel (0,1) you do a softmax over all 20 feature maps at coordinates (0,1); for pixel (0,2)… and so on.
If a is an integer number, the domain of a is Z. If x is a vector of two integers, the domain of x is Z*Z or Z^2. If x is a vector of three integers, the domain is Z^3, etc.
It’s just a way to notate the size of the vector. Instead of saying, “x is a vector with 3 integer elements”, you can say, “x in Z^3”. It’s just math shorthand.
[Likewise, if X is an NM matrix of integers you could say "X in Z^(NM)".]
Another little question regarding this. Why did they say “x ∈ Ω with Ω ⊂ Z^2” instead of just saying " x ∈ Z^2" or “x ⊂ Z^2”? I’m sorry that may seems to be a stupid question but I really want to know the details.
Another thing, why would x be of size 2? Shouldn’t the size of x depends on the count of the k feature maps?
Thanks
x can’t be in all of Z^2, it can only be within your image size (a subset - don’t know how to make an omega symbol on here).
You end up getting an output that is num_pixels * num_channels, but you can look at that as a different output for each pixel instead (since you’re applying softmax independently to each one).
Even after your explanations guys I’m still trying to implement this “energy function” in pytorch with no success.
Here is my code so far:
class EnergyFunction(nn.Module):
def __init__(self):
super(EnergyFunction, self).__init__()
def forward(self, logits, targets):
num = targets.size(0)
A = logits.view(num, -1) # Flatten
B = targets.view(num, -1) # Flatten
C = []
for i in range(num):
C[i] = F.softmax([A[i], B[i]])
I’m not sure why you’re trying to take the softmax over the logits and the targets. Wouldn’t you just take the softmax over the logits and then do a cross-entropy between that softmax and the targets?
My neural network outputs 1 feature maps (instead of 2 from the original paper) so I wanted to experiment with 2 feature maps. But you’re right, the function should take into account the 2 output feature channels of the neural network instead. I modified my neural net architecture so that it now outputs 2 feature channels.
Following your instructions:
class EnergyFunction(nn.Module):
def __init__(self):
super(EnergyFunction, self).__init__()
def forward(self, logits):
# logits is of shape [batch_size, feature_channels, height, width]
# Here: [4, 2, 388, 388]
r = F.softmax(logits)
# r is of shape: [4, 2, 388, 388]
return r
But here r should be of shape [4, 388, 388] or [batch_size, height, width] right? Thing is. I really don’t know how to pass in to the F.softmax() function the pair of pixels from the 2 feature maps .
Thanks again.
I have zero experience with PyTorch, but softmax() usually works across the entire thing. Here, you want to make it work across the feature_channels axis only.
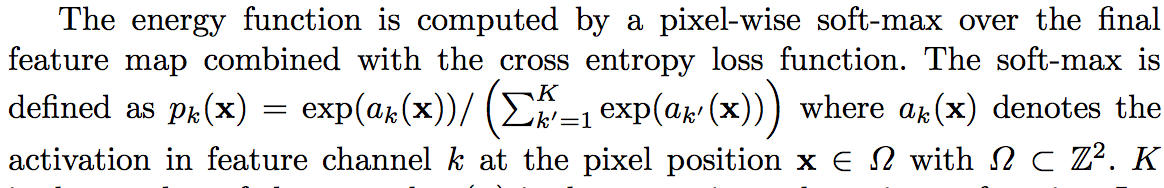




 .
.