Hey,
I saw Uber released blog post on some research they have been doing with convolution layers. I thought people here would find it super interesting. Here is the post:
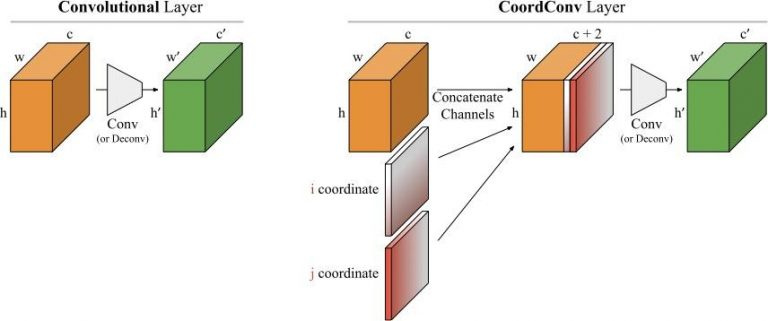
Basically, they found that Convolutions were pretty bad at pinpointing things in an image so they added feature maps that contain the i,j coordinates of each pixel in the map and concatenated it to the convolution output. This allows the convolution layer to learn a translation dependence.
Image of architechture from post.